
For more content like this subscribe to the ShiftMag newsletter.
Is prompting enough? Emanuel Lacić asked this question on the stage of the Shift Conference in Miamias he explored the process of creating a Copilot for a UI-based chatbot builder.
The chatbot builder in question, Answers Copilot, is a GenAI feature tha t enables end users to design a chatbot based on their natural language input. GenAI creates an outline of the design of how the chatbot should behave, automating the chatbot building process to a degree, and the end user then customizes it to meet their requirement.
Starting with prompting
The initial process relied on prompting: Emanuel and his team described what the underlying code looked like, had Open AI generate the code blocks representing visual elements, and then plugged it in to have it rendered in the UI. Preferably with as few hallucinations (i.e., generated code that leads to an error when rendering), and as predictable output as possible.
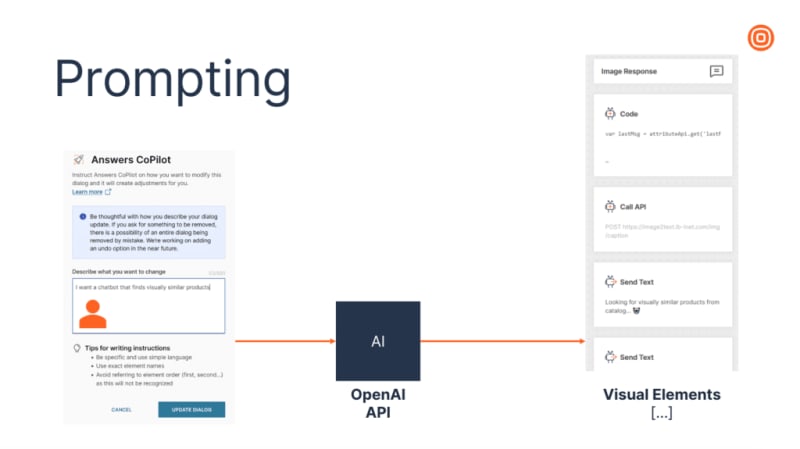
They tested different prompt engineering strategies with Microsoft’s API for GPT-3.5 Turbo. By testing different techniques ranging from zero-shot to few-shot prompting with domain-specific instructions, they managed to lower the percentage of hallucinations to 12.63% on average. Accuracy was measured using HitRate – the number of times where the generated code blacked matched to a 100% of what was expected – which peaked at 2.13%.

Having created the Copilot using different prompting strategies, it was time to answer Emanuel’s titular question: Is prompting enough? The team decided to test the hypothesis that LLMs with context-specific data might yield a lower percentage of hallucinations and higher accuracy (i.e., by measuring the HitRate and turning to fine-tuning.
Bigger is not always better

As end users can task the Answers Copilot with creating a chatbot for a variety of use cases, the task of fine-tuning it required the team to know what input users might provide, as well as what is the desired output. Since real-world data was not available, *GenAI was put to the task of synthetically creating some. *
The data was then used to fine-tune LLMs of various sizes: OpenAI GPT-3.5 Turbo (large), Mistral 7B Instruct(mid), LLaMa 3B (small), and Sheared LLaMa 1.3B (tiny). In addition to training the models with relevant data, the team used LoRA to fine-tune visual element generation.
The fine-tuning process did yield the desired results: LLMs trained on relevant data had a significantly lower number of hallucinations, with 0.04% as the lowest achieved hallucination rate. The accuracy, on the other hand, also improved significantly, where the *HitRate climbed up to 26.72%. *
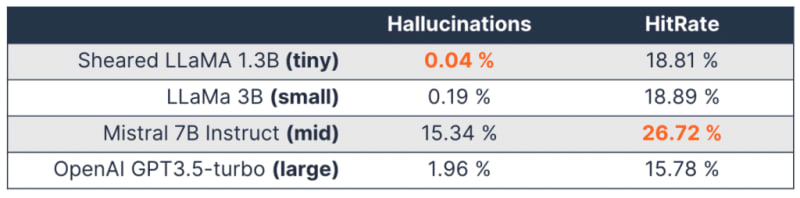
Interestingly, Emanuel notes the best performing models were Sheared LlaMA (in terms of hallucinations) and Mistral 7b Instruct (when it came to HitRate):
Sometimes you don’t need the largest, best performing LLM. But the only way to know which one performs best is to experiment – you can’t know beforehand.
What’s next?
There are always ways to polish Copilots, with user feedback being the logical next step. To that end, he showed the KTO method (Kahneman-Tversky Optimization): As it requires only a binary signal (desirable/undesirable outcome), the user feedback data is more abundant, cheaper, and faster to collect than data based on user preference between two different outputs, which is used in other popular methods like Reinforcement Learning. KTO is also a good choice when there is a marked imbalance between the number of desirable and undesirable examples.
To take user feedback a step further, a multiarmed bandit algorithm can be used, as Emanuel demonstrated, to determine which of the LLMs produces the most favorable results while running in production and, consequently, *which LLM to choose in an automatic way. *
You can find Emanuel’s slides here or find out more about his work on his personal website.
The post Want to build a more accurate Copilot with fewer hallucinations? Move from prompting to fine-tuning. appeared first on ShiftMag.





Top comments (0)