Introduction
In today's big data era, organizations are perpetually seeking efficient ways to manage, analyze, and leverage their data. As businesses expand, so does the volume and velocity of their data, necessitating real-time processing and analytics for timely decisions and data-driven insights. This constant data influx has given rise to the concept of streaming data warehouses, a relatively new concept still being deciphered by many. This article aims to demystify the streaming data warehouse, detailing its components, advantages, and why it is pivotal in the modern data stack.
What is a Streaming Data Warehouse?
A streaming data warehouse is an advanced data management system engineered to handle, process, and store real-time data streams almost instantly. Unlike traditional data warehouses, which store historical data and are batch processing-oriented, streaming data warehouses process data continuously as it arrives. This innovative technology amalgamates the functionalities of a conventional data warehouse and a stream processing system, delivering real-time analytics and insights while managing vast volumes of historical and streaming data.
Key Components of a Streaming Data Warehouse
Data Ingestion:
The initial stage in the streaming data warehouse data pipeline involves collecting and importing real-time data from diverse sources such as applications, devices, or other systems. The ingested data can be in various formats, including JSON, Avro, Parquet, and others.Stream Processing:
Following data ingestion, the incoming data streams are processed and analyzed in real-time. Complex event processing (CEP) engines and stream processing engines scrutinize the data for patterns, trends, and anomalies.Data Storage:
Post-processing, the data is stored in a manner that facilitates quick retrieval and analysis. Streaming data warehouse data storage is optimized for both real-time and historical data, enabling rapid query performance and efficient storage management.Real-time Analytics:
This crucial component empowers users to query and analyze the data in real-time, providing immediate insights and enabling informed decision-making.
Advantages of a Streaming Data Warehouse
Real-time Insights: Organizations can make data-driven decisions almost instantly as the data is processed and analyzed in real-time.
Scalability: Streaming data warehouses are engineered to handle vast data volumes, both in motion and at rest, ensuring efficient system scaling as data volume escalates.
Flexibility: A streaming data warehouse offers the flexibility to manage diverse data types, both structured and unstructured, and from various sources.
Reduced Latency: Streaming data warehouses significantly curtail latency associated with data processing and analytics, delivering insights almost instantaneously.
Open-Source Streaming Data Warehouse
An open-source streaming data warehouse is a data management system that leverages open-source tools and technologies to handle real-time data streams, process, store, and analyze them almost instantly. Open-source solutions are often preferred due to their flexibility, cost-effectiveness, and the robust community support they receive. Let's dive into some of the popular open-source tools used in different components of a streaming data warehouse.
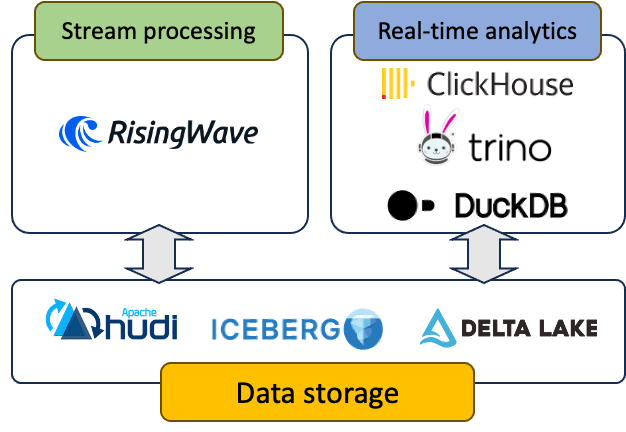
Data Ingestion and Stream Processing
- RisingWave: It is an open-source streaming database that is specifically designed for stream processing. It can handle a large volume of data in real-time, making it an excellent choice for the stream processing component of a streaming data warehouse. RisingWave allows you to ingest, process, and analyze data streams in real-time, providing immediate insights and enabling timely decision-making.
Data Storage
Apache Iceberg: It is an open-source table format for massive analytic datasets. Iceberg provides a better layout and metadata management for data stored in cloud storage or distributed file systems, enabling improved performance and reliability.
Apache Hudi: It stands for Hadoop Upserts Deletes and Incrementals. Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development by managing the storage of large analytical datasets on distributed storage.
Delta Lake: It is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. Delta Lake provides the ability to perform CRUD operations, schema enforcement, and evolution, and ensures data consistency.
Real-time Analytics
ClickHouse: It is an open-source column-oriented database management system that enables real-time generation of analytical data reports using SQL queries. ClickHouse is optimized for performance and is capable of processing millions of queries per second with minimal latency.
Trino: It is an open-source distributed SQL query engine optimized for running interactive ad-hoc analytics queries on data sources of all sizes, ranging from gigabytes to petabytes. Trino is designed to query large datasets that are distributed over one or more heterogeneous data sources, including traditional databases, data warehouses, and big data systems.
DuckDB: It is an open-source analytical data management system optimized for OLAP workloads. DuckDB provides a robust query optimizer and execution engine that can handle complex analytical queries efficiently.
CONCLUSION
In an age where data generation is at an unprecedented rate, real-time data processing and analysis are imperative for businesses to maintain a competitive edge.Streaming data warehouses address this challenge by offering a platform capable of handling real-time data streams, efficient storage, and immediate insights.
Additionally, open-source tools and technologies provide a flexible and cost-effective solution for implementing a streaming data warehouse.
Leveraging RisingWave for stream processing, Apache Iceberg, Apache Hudi, or Delta Lake for data storage, and ClickHouse, Trino, or DuckDB for real-time analytics can help organizations build a robust and efficient streaming data warehouse that can handle real-time data streams, provide immediate insights, and enable timely decision-making.
About RisingWave Labs
RisingWave is an open-source distributed SQL database for stream processing. It is designed to reduce the complexity and cost of building real-time applications. RisingWave offers users a PostgreSQL-like experience specifically tailored for distributed stream processing.
Official Website: https://www.risingwave.com/
Documentation: https://docs.risingwave.com/docs/current/intro/
GitHub:https://github.com/risingwavelabs/risingwave
Originally published at https://www.risingwave.com.





Top comments (0)