
Organizations that use Microsoft O365 benefit from maintaining their file assets and documents over collaborative services like Sharepoint. But that's not always the case as smaller teams maintain documents pertaining to their product in their own CMS. Moreover data from legacy systems tend to become obsolete when left unmanaged. With data staying at multiple sources, information becomes localized.
This post is about how organizational content sourced from multiple parties can be collected and accessed in a Unified channel with Microsoft O365. We deal with a feature called Connectors which is a Preview offering from Microsoft at the time of writing.
With the new Connectors program from Microsoft, it's possible to stream your multi-sourced data into one channel and search it effectively with an interface that we already know: Bing Search.
How connectors work
Connector services are based on the concept of search indexing. There are two classes of connectors:
- Built-in connectors
- Custom connectors
Built-in connectors are specific to O365 like DataLake, SQL & File System Connectors. For other systems, Microsoft supports custom connector development, a flexible developer-friendly way to organize & manage the data flow.
Note: Microsoft Connectors are soon to be generally available and here is a link with instructions to try out the preview.
Creating a Custom connector
Building a custom connector deals a lot with utilizing Search APIs available within Microsoft Graph, the developer platform for integrating business services. Every interaction is based on HTTP RESTful APIs from Microsoft Graph and requires an authenticated session (this deals with Azure Active Directory).
A custom Connector would involve 3 major steps:
- Create your connection
- Setup a schema
- Indexing: Create items
Authentication
Search API can be accessed like any other service in Graph. You'll need to provision an Azure Active Directory app with autonomous settings as instructed here.
Create your connection
Connection defines a named entity for your data collection. Ideally every connection would possess a name indicating your data store.
Setup a schema
To start indexing items, connector needs a structure in which data would be persisted - list of properties just like how we define field names & types for a database table.
In addition, there's a range of customizable parameters that give control over ways to make search more effective.
Both primitive types as well as Collections are supported.
| Parameter | What it means |
|---|---|
| name* | 32-char max-length property name |
| type* | data type (provided by Microsoft Graph) |
| isSearchable | true if field should support full-text search |
| isQueryable | true if field should support name:value search filetype:docx
|
| isRetrievable | true if field is used for display |
| isRefinable | true if field should act as a filter |
| labels | semantic type of property: title, url, authors to name a few |
| aliases | alternate name for the property |
Indexing
Once we have connection with schema ready, it's time to index data. Every data item from the external system needs to be organized as per the schema as a property map:
{
"name": "Logistics Management",
"title": "Logistics Management: Procedure",
"url": "https://<sys>/en/docs/oms/logistics-procedure.docx",
"authors": [ "Alex Jones", "John Wick" ],
"createdBy": "Alex Jones",
"lastModifiedBy": "John Wick",
"updatedTimestamp": "2020-08-15T06:01:38Z",
"filename": "logistics-procedure",
"filetype": "docx"
}
In addition, each item requires a resource ID (cannot exceed 32 characters in length) that'll be used to denote an item in the Index. This ID has to be a path parameter of Items Endpoint in Search API.
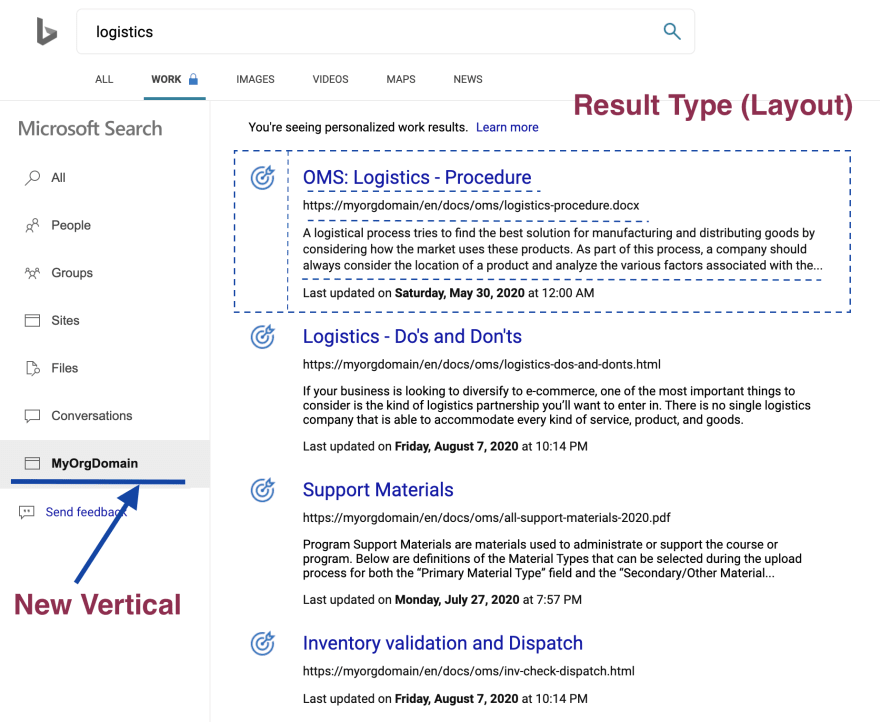
What Bing.com offers
To make sure Bing fetch these results and display to users, it needs a Search Layout to be mapped to your connection.
- Setup a new vertical that refers to the data source.
- Design a Layout for your results. Microsoft Search uses Adaptive card design, to develop a graphical representation of properties, text and images & extensively format your template.
And here we go!
How to manage these connectors
As a Tenant Administrator, high-level info about Connectors is available over Microsoft Admin portal. However, it doesn't show item info. The custom connector is solely responsible for the indexing. The indexing process is time-intensive as there's lot to be carried out under the hood:
- Fetch data from systems
- Transform data per external schema
- Create data item on the index
This process can be optimized in multiple ways:
Limit the amount of data used for searching. Excessive indexing can in turn affect the relevancy ranking. Limitation: An item cannot exceed 4 MB size.
Write data as batches instead of one at a time. However, large batches involve excessive data transfer ultimately causing bottleneck. A judiciously tried batch value can help avoid multiple failure scenarios, alternative check out Batch API. Limitation: Microsoft has limited concurrent operations to 4 for now, expected to increase soon.
As long as data items are independent, handle errors at item-level rather than process-level. A tracking mechanism indicating amount of documents processed at any instant can help control the process efficiently.
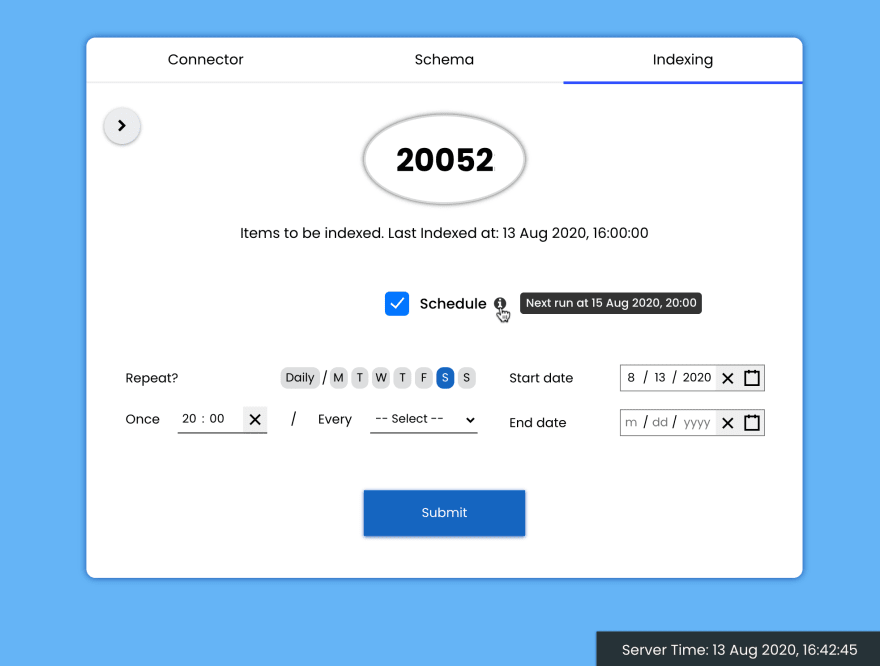
Dealing with a system of about 300-350 GiB data, to automate indexing process with frequent updates, I built a connector management tool, with a UI made with React to initiate, schedule & track the progress of indexing, along with reports to understand reasons of failure.

Links to docs:
- Create Connection
- Setup schema
- Data indexing
- Property data types
- Autonomous authentication
- Verticals & Result Types
And THE END! Hope the post is pretty intuitive in getting to know about what connectors are and how to develop Search experience with Bing. Thanks for your time, appreciate a feedback. See you with another post.
Peace! ✌️



Top comments (0)