
Introduction
In the intricate realm of databases, indexes stand as silent heroes, enhancing the performance of queries and expediting data retrieval. In this blog post, we'll unravel the mystery behind indexes, exploring their definition, purpose, and real-world applications.
At their core, indexes are data structures that provide a swift pathway to locate and access specific rows within a database table. Think of them as the index in a book—a quick reference that directs you to the exact page containing the information you seek.
Let's Get Right Into It
Indexes are data structures that store a subset of the data in a table, along with a pointer to the location of the original record. They are similar to the indexes in a book, which help you find the page number of a topic you are looking for, without having to scan the whole book. For example, if you want to find the page number of the topic “database”, you can look it up in the index at the end of the book, and see that it is on page 23. Similarly, if you want to find the record of a customer with a specific name in a table, you can use an index on the name column, and see the pointer to the record, without having to scan the whole table.
Use Cases of Indexes and its Impact
Indexes are useful for speeding up data retrieval, as they reduce the number of disk I/O operations required to access the data. They also improve query performance, as they allow the database to use efficient algorithms to find the matching records, such as binary search, hash lookup, or tree traversal. Moreover, indexes can support unique constraints, which ensure that no two records in a table have the same value for a given column or combination of columns.
However, indexes are not free. They require extra storage space, as they store a copy of the data in a different format. They also impose overhead on data modification operations, such as insert, update, and delete, as they need to be maintained and updated whenever the data changes. Therefore, it is important to use indexes wisely, and only create them on the columns that are frequently used in queries, and that have high selectivity, meaning that they can filter out a large number of records.
Types of Indexes
There are different types of indexes in database, depending on the number of columns they include, the order of the values they store, and the way they are implemented. Some of the common types of indexes are:
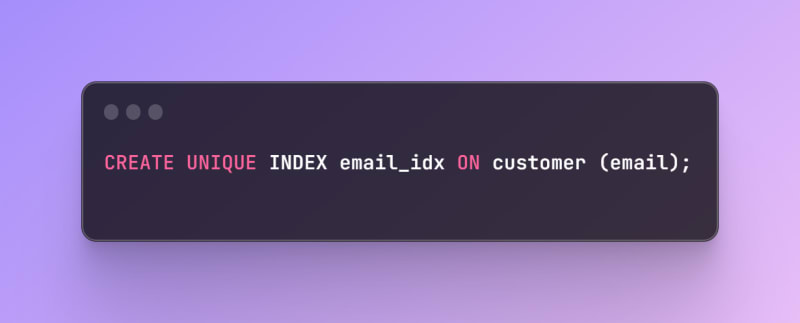
- Unique index: This is an index that ensures that no two records in a table have the same value for a given column or combination of columns. For example, you can create a unique index on the email column of a customer table, to prevent duplicate email addresses. You can create a unique index using the CREATE UNIQUE INDEX statement, as follows:
- Single-column index: This is an index that includes only one column of a table. For example, you can create a single-column index on the name column of a customer table, to speed up queries that search for customers by name. You can create a single-column index using the CREATE INDEX statement, as follows:

- Composite index: This is an index that includes more than one column of a table. For example, you can create a composite index on the name and city columns of a customer table, to speed up queries that search for customers by name and city. You can create a composite index using the CREATE INDEX statement, as follows:

- Implicit index: This is an index that is automatically created by the database when you define a primary key or a foreign key constraint on a table. For example, if you define a primary key on the id column of a customer table, the database will create an implicit index on the id column, to enforce the uniqueness and the referential integrity of the column. You do not need to create an implicit index explicitly, as the database will do it for you.
You can drop an index using the DROP INDEX statement, as follows:

This will delete the index name_idx from the database, and free up the storage space it occupied. However, you should be careful when dropping an index, as it may affect the performance and the functionality of your queries. You should only drop an index if you are sure that it is not needed, or if you want to replace it with a better one.
Let's Visualize it
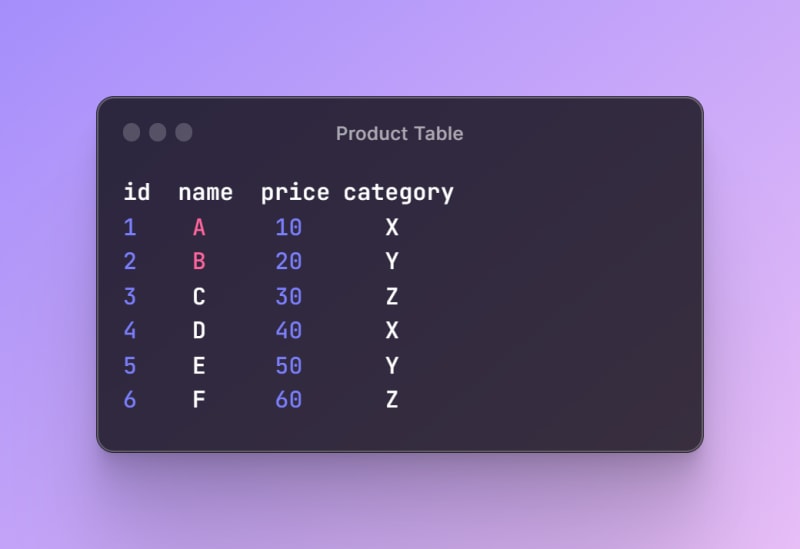
To illustrate how indexes work in database, let us consider an example of a complex query, and how creating the right index can help execute it faster. Suppose we have a table called product, which has the following columns and data:
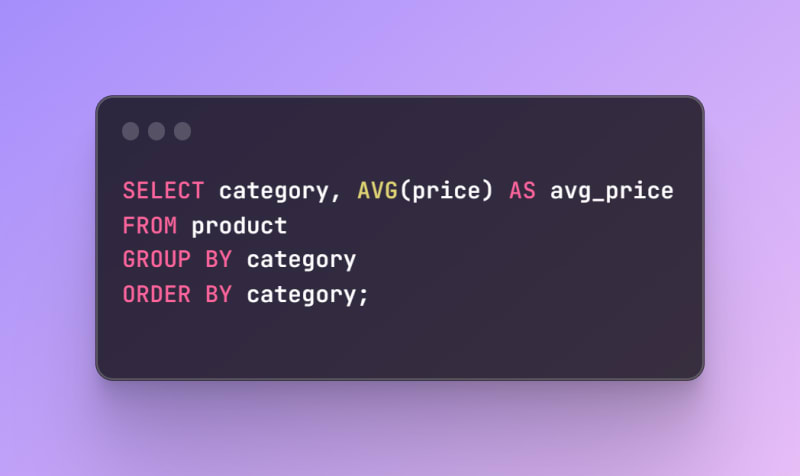
Suppose we want to run the following query, which finds the average price of the products in each category, and orders the result by the category name:
If we do not have any index on the product table, the database will have to scan the whole table, and perform the following steps:
Read each record from the disk, and store it in the memory.
Calculate the average price for each category, by adding the prices of the products in the same category, and dividing by the number of products in that category.
Sort the result by the category name, using a sorting algorithm, such as quicksort or merge sort.
Return the result to the user.
This process will take a lot of time and resources, as the database will have to read all the records from the disk, perform the calculations, and sort the result.
However, if we create a composite index on the category and price columns of the product table, using the following statement:

The database will create an index that stores the values of the category and price columns, along with a pointer to the original record, in a sorted order. The index will look something like this:

Now, when we run the same query, the database will use the index, and perform the following steps:
Read the index from the disk, and store it in the memory.
Scan the index, and calculate the average price for each category, by adding the prices of the products in the same category, and dividing by the number of products in that category. The index is already sorted by the category name, so there is no need to sort the result again.
Return the result to the user.
This process will be much faster and efficient, as the database will only have to read the index from the disk, which is smaller and more compact than the whole table, and perform the calculations, without having to sort the result.
Conclusion
In conclusion, indexes are powerful tools that can help you improve the performance and the functionality of your database. However, they also have some limitations and trade-offs, such as the extra storage space they require, the overhead they impose on data modification operations, and the need to maintain and update them regularly. Therefore, you should use indexes wisely, and only create them on the columns that are frequently used in queries, and that have high selectivity. You should also monitor and analyze your queries, and see how they use the indexes, and whether they need to be modified or dropped. By doing so, you can optimize your database, and make it more responsive and reliable.
Thank you for reading! If you have any questions or feedback about this article, please don't hesitate to leave a comment. I'm always looking to improve and would love to hear from you.
Also, if you enjoyed this content and would like to stay updated on future posts, feel free to connect with me on LinkedIn or X or check out my Github profile. I'll be sharing more tips and tricks on Django and other technologies, so don't miss out!
If you find my content valuable and would like to support me, you can also buy me a coffee. Your support helps me continue creating helpful and insightful content. Thank you!





Top comments (0)