With the rise of serverless technology, making web services only gets easier. Serverless apps change the old monolithic architecture of apps and promote more of a microservice solution to technical problems.

With the advantage of autoscaling, and multi-region deployments it is no wonder that serverless apps are making a quick rise in recent years. The cost of serverless has also redefined how we make software as it is now on a per request basis rather than a time-based service.
Even better, serverless also enables small services to be free altogether. Only being needed to be paid after a million requests or so. An example would be Azure Function’s consumption plan.
What does Serverless have to do with this tutorial?
The main reason serverless is being mentioned here is because FaunaDB is a NoSQL database that is made for serverless in mind. The pricing on this database is request based, precisely what serverless apps need.
Using a service like FaunaDB can help cut costs so much that the hosting capabilities of the app would be virtually free. Excluding the development costs of course. Thus, using a monthly billed database for serverless apps kind of kills the point.
A free stack example would be a combination of Netlify, Netlify Functions, and FaunaDB. Though it would only be ‘free’ for a certain amount of requests. Unless you are making an app that gets thousands of users on day zero of deployment I don’t think it would be much of a problem.
In my opinion, using a monthly billed database for serverless apps kind of kills the point
Flask on the other hand is a microframework written in Python. It is a minimalistic framework with no database abstraction layers, form validation, or any other particular functions provided by other frameworks.
Flask is by large serverless compatible. You can make a serverless Flask app using AWS Lambda. Here is an official guide to Flask serverless from serverless.com.
Getting Started
Setting up Python and Pip
First of all, install Python and Pip. I’m not going to list all the possible ways of installing it, for Windows users you can get the installer here. As for Linux users if you are using a Debian/Ubuntu-based distro open your command prompt and install python and pip like this:
sudo apt update
sudo apt install python3 python3-pip
To check if the installation is correct try executing these commands:
python --version
pip --version
The version numbers would then show for the corresponding commands.
Installing dependencies
After the environment setup is complete, the next step would be to install Flask itself. The installation process is simple just enter:
pip install Flask
Then, install the python driver for FaunaDB:
pip install faunadb
Voila! You’re all set!
Making a To-Do List App
Now we are going to make an example app with the mother of all app ideas, the to-do list app.
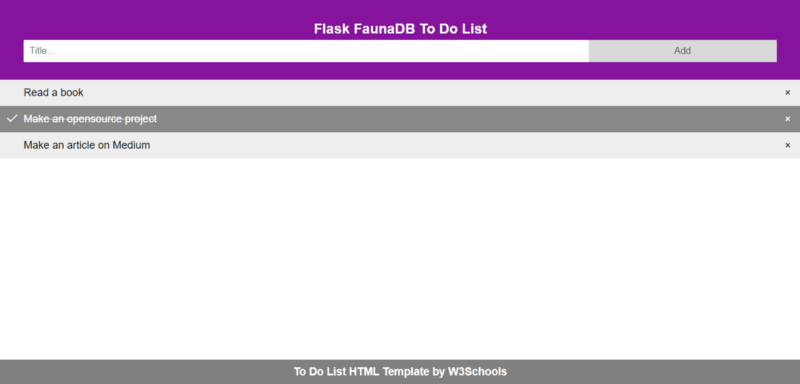
To-Do List Template
For this example, because we will be focusing mainly on how to make the API we will be using the W3School template for the to-do list app frontend.
Basic Project Structure
Our project would be an implementation of a helper pattern. A simple outline of our project would be like so:
\-
|--app.py
|
|--services
|--todo_service.py
|--helpers
|--todo_helper.py
|--entities
|--faunadb_entity.py
FaunaDB Indexes
Wait, what are indexes?
Indexes are how you make ‘where’ statements in FaunaDB. It allows you to get specific documents based on the field values.
To create a new Index, just go to the Indexes section on your database and click New Index.

When creating an Index, choose the collection you would want to interact with. Then define the field name you want to search by. Lastly, define your index name make sure it is unique and readable.

For example, let’s make an index where we can get all the data in an existing collection.

Oh, what about an index to get todos by the user’s email? Easy.

If you want to make the terms unique, check the Unique checkbox to add a constraint.

To add constraints to a certain collection you need to create indexes with terms that contain unique fields.
To help you understand better, here is an official article from Fauna to help you understand indexes.
Let’s Make The API
Make the Flask startup file
First, write a python file that would run Flask.
from flask import Flask
app = Flask( __name__ )
if __name__ == " __main__":
app.run(host='0.0.0.0')
Write the FaunaDB entity script
Next, before we start writing our services and helpers we must first define an entity file to connect to FaunaDB.
import os
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
def get(index, data):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
res = serverClient.query(q.get(q.match(q.index(index), data)))
res["data"]["ref_id"] = res["ref"].id()
return res["data"]
except Exception as ex:
raise ex
This is used to get a FaunaDB document by Index. The get function does not return multiple documents and is only able to return a single document at a time.
To get multiple documents we need to use a map function to return multiple data by a certain index.
def get_multiple(index, data=None):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
res_arr = []
if data is None:
res = serverClient.query(
q.map_(
q.lambda_("data", q.get(q.var("data"))),
q.paginate(q.match(q.index(index)))
)
)
res_arr.extend(res["data"])
elif isinstance(data, list):
for x in data:
res = serverClient.query(
q.map_(
q.lambda_("data", q.get(q.var("data"))),
q.paginate(q.match(q.index(index), q.casefold(x)))
)
)
res_arr.extend(res["data"])
else:
res = serverClient.query(
q.map_(
q.lambda_("data", q.get(q.var("data"))),
q.paginate(q.match(q.index(index), q.casefold(data)))
)
)
res_arr.extend(res["data"])
arr = []
for x in res_arr:
x["data"]["ref_id"] = x["ref"].id()
arr.append(x["data"])
return arr
except Exception as ex:
raise ex
The lambda function will pass the data needed in the Index while paginate will search for the specific documents in the collection, then the map function will return all matching documents as a list.
def get_by_ref_id(collection, id):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
res = serverClient.query(q.get(q.ref(q.collection(collection), id)))
res["data"]["ref_id"] = res["ref"].id()
return res["data"]
except Exception as ex:
raise ex
Get document by reference Id is the only function that does not use an Index rather would utilize the document’s reference Id.
The code for creating, updating, and deleting documents would be similar. Because FaunaDB is a NoSQL database the data structure doesn’t matter as long as it is passed as a dictionary. Updating and deleting documents would also need an extra reference Id parameter, similar to the Get document by reference Id function.
def create(collection, data):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
res = serverClient.query(q.create(q.collection(collection), {"data": data}))
res["data"]["ref_id"] = res["ref"].id()
return res["data"]
except Exception as ex:
raise ex
def update(collection, id, data):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
res = serverClient.query(q.update(q.ref(q.collection(collection), id), {"data": data}))
res["data"]["ref_id"] = res["ref"].id()
return res["data"]
except Exception as ex:
raise ex
def delete(collection, id):
try:
serverClient = FaunaClient(secret=os.environ.get("FAUNA_SERVER_SECRET"))
serverClient.query(q.delete(q.ref(q.collection(collection), id)))
return True
except Exception as ex:
raise ex
Make the To-Do helper
After writing the FaunaDB entity script, write the helper functions for the collection. The helper functions need to be small precise functions that do exactly one thing.
from entities.faunadb_entity import get, get_multiple, get_by_ref_id, create, update, delete
def get_all_todos():
try:
return get_multiple('all_todos')
except Exception as ex:
raise ex
def get_todo_by_ref_id(id):
try:
return get_by_ref_id('todo', id)
except Exception as ex:
raise ex
def create_todo(data):
try:
return create('todo', data)
except Exception as ex:
raise ex
def update_todo(id, data):
try:
return update('todo', id, data)
except Exception as ex:
raise ex
def delete_todo(id):
try:
return delete('todo', id)
except Exception as ex:
raise ex
Make the To-Do service
When all the helpers are ready, write the service file to be used as endpoints. All the requests are parsed at the service level, thus the helper level will only receive processed data.
from flask import request, jsonify
from helpers import todo_helper
def get_all_todos():
try:
print(todo_helper.get_all_todos())
return jsonify(todo_helper.get_all_todos())
except Exception as ex:
raise ex
def get_todo_by_ref_id(id):
try:
return jsonify(todo_helper.get_todo_by_ref_id(id))
except Exception as ex:
raise ex
def create_todo():
try:
req_data = request.get_json()
return jsonify(todo_helper.create_todo(req_data))
except Exception as ex:
raise ex
def update_todo(id):
try:
req_data = request.get_json()
return jsonify(todo_helper.update_todo(id, req_data["data"]))
except Exception as ex:
raise ex
def delete_todo(id):
try:
return jsonify(todo_helper.delete_todo(id))
except Exception as ex:
raise ex
Attach the routes to the service endpoints
Finally, when the endpoints are set, add the endpoints to the app.py
from services.todo_service import get_all_todos, get_todo_by_ref_id, create_todo, update_todo, delete_todo
from flask import Flask
app = Flask( __name__ )
app.add_url_rule('/api/todos', methods=['GET'], view_func=get_all_todos)
app.add_url_rule('/api/todos', methods=['POST'], view_func=create_todo)
app.add_url_rule('/api/todos/<string:id>', methods=['GET'], view_func=get_todo_by_ref_id)
app.add_url_rule('/api/todos/<string:id>', methods=['PUT'], view_func=update_todo)
app.add_url_rule('/api/todos/<string:id>', methods=['DELETE'], view_func=delete_todo)
if __name__ == " __main__":
app.run(host='0.0.0.0')
You’re done! Don’t forget to test the APIs with Postman before deployment.
Summary
TL;DR You can check out my Github repository for the project and try to run it yourself.
Boilerplate code for Flask and FaunaDB project
In this tutorial, you have learned to make an API using Flask and FaunaDB.
To recap we have made:
- API endpoints using Flask.
- Indexes in FaunaDB.
- A simple entity helper for FaunaDB.
- A readable boilerplate for future API projects.
You now have a quick boilerplate setup to use when you want to make a quick app in a matter of hours. Future plans include adding a Swagger implementation to the existing boilerplate.
Hope this is a great start for you, have a nice day!





Top comments (0)