
This article lives in:
Intro:
I joined future demand 2 years ago as a software engineer, and during the last year my team and I had been working with Metaflow and in this article, I want to summarize our experience using it.
The framework was developed originally at Netflix and it has an active community, and as the framework is still relatively new, I decided to write an article to describe what is Metaflow, and how it fits in the whole picture of the product development process. Even though there is very nice documentation for Metaflow, I thought writing our experience based on real-world use cases would be helpful and easier to grasp.
To give a quick overview of Future Demand, we work with events organizers (sports, music, and entertainment events), and we boost their ticket sales by extracting knowledge from the data they already have. We use the idea of taste clusters for targeting people based on their real interests rather than social and demographic characteristics. For example, targeting based on musical taste is basically what drives the sales in the classical music field other than any other characteristic.
What is Metaflow?
Metaflow is a framework that helps data scientists to manage, deploy and run their code in a production environment. And it accelerates the development process by tracking the experiments done by the data scientists.
Pre Metaflow:
At the time I joined the company, the data science team had already developed their models. Their code was python scripts, which ran locally on their machines to deliver the final results.
Going one step back in time this code was originally written in Jupyter notebooks. It was then extracted and refactored by our team to run as pure python scripts for automation.
For us, as engineers, the focus was on deploying and managing this code, how we can automate it, and putting these scripts in production.
Metaflow comes into play:
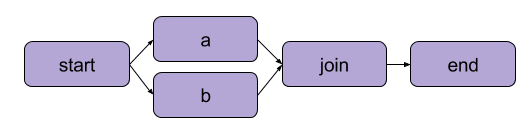
At that time our machine learning code could have been described as a DAG (Directed Acyclic graph).
The DAG in short is a mathematical representation for a workflow, it describes the steps you do to treat and transform data, basically, it is an abstraction for a data pipeline

And it can contains some steps on parallel.
There was no advantage for managing the workflow ourselves, so we decided to use a framework to run and manage the code for us.
Using a framework can help us in many aspects. for example automation, parallelization, orchestration, failover (resuming after a specific step has failed), etc.
Doing some research we found many options like (Luigi, Airflow, Metaflow, MLflow), and as we were impressed by the high level of integration between Metaflow and AWS, we decided to go with Metaflow.
Metaflow terminologies:
Metaflow Flow:
The Flow is the main concept in Metaflow, it is a piece of code that describes the steps you want to execute, and what is the order of execution for these steps.
Let us consider the DAG provided in the image below:

Basically this flow can be implemented as follows:
from metaflow import FlowSpec, step
class LinearFlow(FlowSpec):
@step
def start(self):
self.my_var = 'hello world'
self.next(self.a)
@step
def a(self):
print('the data artifact is: %s' % self.my_var)
self.next(self.end)
@step
def end(self):
print('the data artifact is still: %s' % self.my_var)
if __name__ == '__main__':
LinearFlow()
And the flow can be executed easily as follows:

Metaflow Run:
The concept of Metaflow run — at least for me — was something new and smart. Basically, every time you or any other team member runs a flow — locally or on AWS — all the metadata connected to the flow will be stored automatically for later use, in a central database or on S3.
For example:
- Anything you assign to self will be stored.
- The time of the execution.
- The version of the code which has been executed.
- The metadata (input parameters, status, the user who executed the flow).
- The data science artifacts (models, feature sets, training data)
Metaflow service:
As I mentioned in the last section every run for Metaflow is being tracked, but how does this happen?
In short, there is a client API server running (on AWS).
We call this a Metaflow meta-service, and every time a flow has been executed (locally or on AWS), all the metadata about your run will be transmitted to a central database — under the hood — using the meta-service.
Metaflow use cases:
I will mention some use cases where we could benefit from Metaflow and how it could make our development and deployment process much easier
Tracking and versioning:
While developing the models, our data scientists had to do experiments and select the best feature set which gives the best model. Basically, they were using excel files to store which feature set gave which result.
There should be a nicer way to do this, right?
The answer is yes, Metaflow will store all the data about the experiments you do, or any other team member does, and you can easily inspect all the historical runs to compare and select the best result for your model.
Inspecting your historical runs is very easy, and it can be explained using this code snippet:
from metaflow import Flow
flow = Flow('ModelCreationFlow'). # which flow you want to inspect
for run in flow: # iterate over all the historical runs
if run.successful:
print(run.finished_at) # print when was the run
run_id = run.id # get the run id
df_predection = Flow("ModelCreationFlow")[run_id].data.df_predection
In this code snippet, we are iterating over all the historical runs for a flow and reading some data from each run which was very useful.
Apart from doing experiments, our models were also being trained by constantly changing training data. Iterating over historical runs helped us to understand how this is affecting our models, which is something we could track easily using Metaflow.
Scaling and cloud integration:
Another use case for us was that we wanted to train our models locally, but some steps needed too much time and resources to execute.
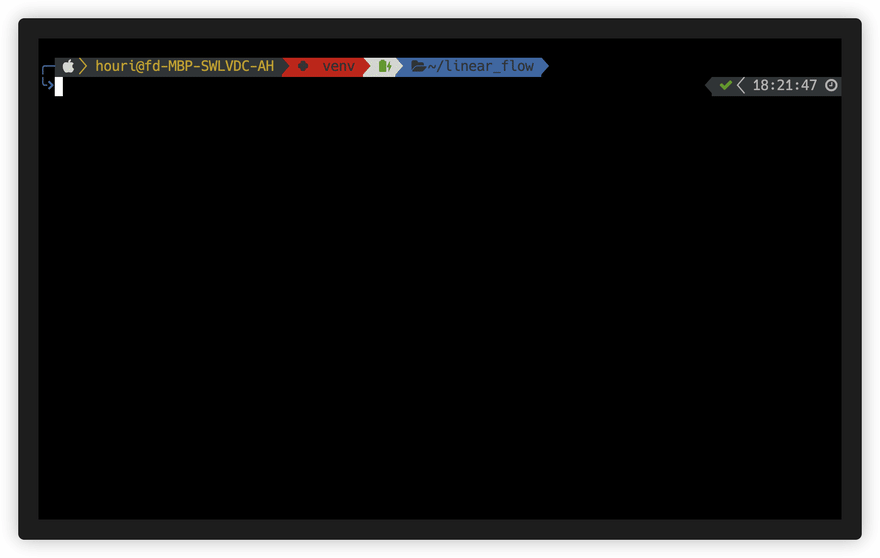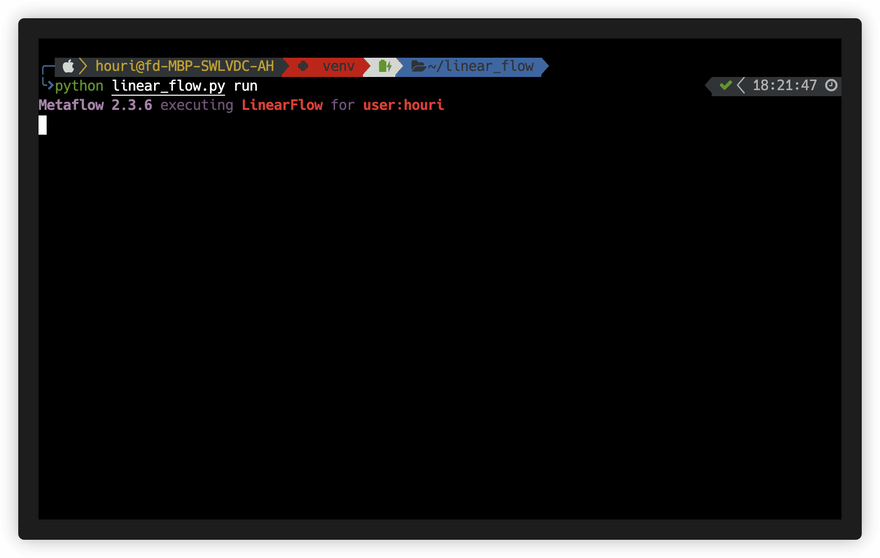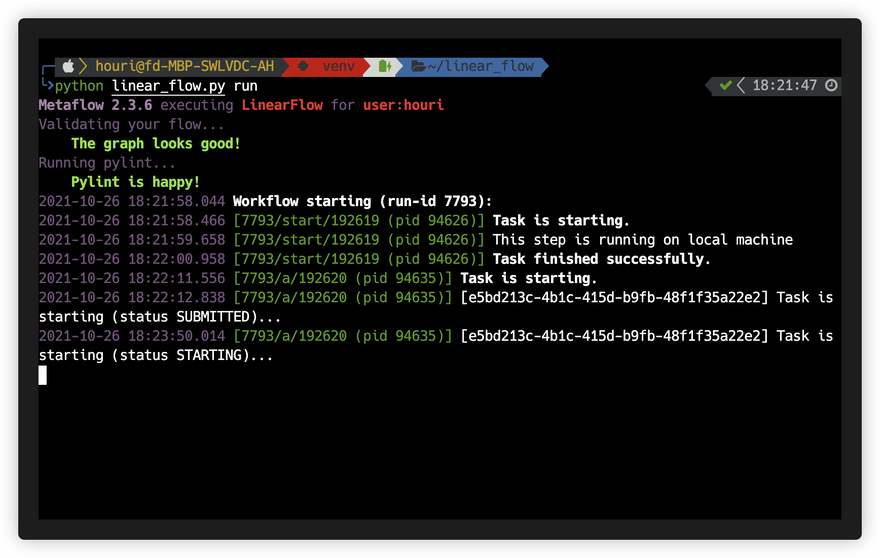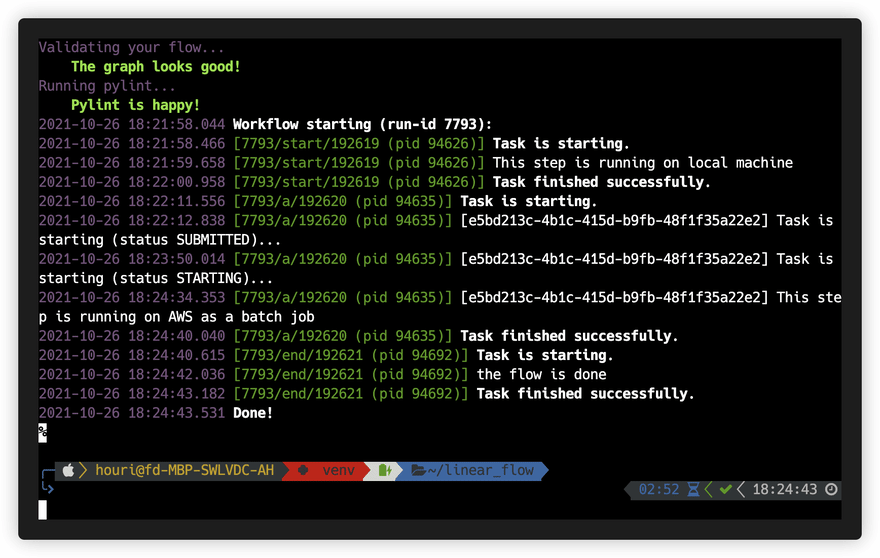
We found out that we can easily switch specific steps to be executed as a batch job on AWS, even if we are running the flow locally — which can be done using the batch decorator:
from metaflow import FlowSpec, step, batch
class LinearFlow(FlowSpec):
@step
def start(self):
print('This step is running on local machine')
self.next(self.a)
@batch(memory=60000, cpu=1). # using batch to execute step on AWS
@step
def a(self):
# A memory intensive task or a cpu intensive task
print('This step is running on AWS as a batch job')
self.next(self.end)
@step
def end(self):
print('the flow is done')
if __name__ == '__main__':
LinearFlow()
By using the batch decorator for step a, we forced executing this exact step on AWS, using the requested memory and CPU resources, while still using our IDEs to run the code.
Deployment:
Deployment is another useful aspect of Metaflow. The first time we discussed how to deploy and automate the process of re-training our models, we thought about dockerizing our code, and selecting which service is the best to run the code, and so on …
Later we found out that the deployment process couldn’t be easier using Metaflow. Basically, and by executing one command, we could reflect our local flows as a step-functions state machine on AWS, which we could trigger using lambda functions or manually.
This is an example:

And the flow has been reflected as a step-functions state machine on AWS:
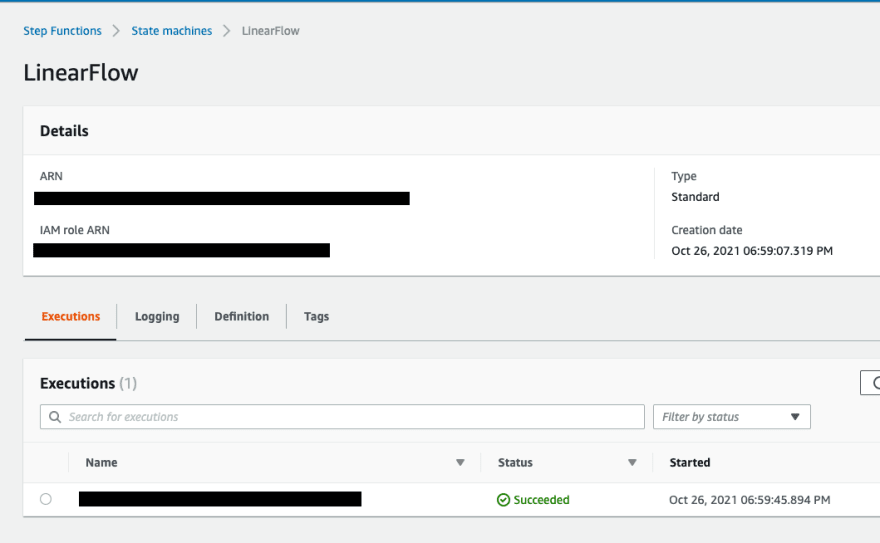
and we were used to triggering them manually sometimes on AWS and we scheduled daily runs using lambda functions.
This is how step functions for our flows look like on AWS:

Later we built a simple deployment pipeline and we attached it to our code repositories.
Every time someone pushed new changes to a specific branch all the changes were reflected directly on the related step function.
Continuous delivery for machine learning:
In one of the use cases, we used a data science model behind a rest API, to serve a frontend and give event recommendations, and because of this, our model needed to be trained on a daily basis to include new events. We used Metaflow to load the latest version of the model on the backend, with the following steps:
- Loading the model on the backend from the latest successful run for Metaflow.
- Doing a sanity test for the service using the loaded model, and only if it passes the tests then we use the new model.
- If the sanity tests fail we go back to an earlier Metaflow run to load an older version from the model which can pass our tests.
This can be done definitely without Metaflow, but for us, it was much cleaner and easier to use Metaflow to version and store all the data science artifacts for us.
Debugging and resuming failed flows:
Another useful use case was the ability to resume failed steps.
Sometimes, the step-function that is scheduled to run daily on AWS fails.
Since the data is changing constantly, reproducing bugs becomes more difficult, and because of that, we wanted to have the ability to resume failing steps, with the same datasets. And by using Metaflow we could easily inspect the flow on our machines, look at the data which caused the bug, resume the flow execution from the failed step, and debug what went wrong.
Finally …
In conclusion using Metaflow, in some aspects, was as important as using Git for the code itself. And It gave our data scientists the possibility to manage their code through its entire lifecycle to deployment. Also, it gave us (the engineers) more time to focus on other parts of the system.
I hope you enjoyed the article… My name is Ahmad, I am a software engineer and this is my first technical blog post, and for this reason, any positive or negative feedback is more than appreciated!
Before You Go …
Thanks for reading! I hope you enjoyed the article… If you want to get in touch with me, feel free to reach me at ahmad.hori@gmail.com or on my Linkedin also you can follow me on Medium for more stories.





Top comments (2)
very useful blog post. Thanks for sharing.
Do you have any example flow which includes training a mode, deploying and also versioning ?
This is an amazing read Ahmed. Why don't you go ahead and share it with Google's Dev Library: devlibrary.withgoogle.com/