
When you create a custom GPT OpenAI only allows you to upload 20 documents. Uploading documents is a pretty cool feature, but let's face it, 20 documents won't bring you far. If you want to create for instance a legal advice GPT, you typically need hundreds and sometimes thousands of documents.
In the video below I am demonstrating how to achieve this by creating a "context endpoint" with Magic using Low-Code and No-Code software development. This allows me to scrape my website, upload thousands of PDF documents, or thousands of other types of files. Below the video you can find the code required to create your endpoint.
Explanation
The GPT I create in the video will not use ChatGPT directly. Every single time I ask a question, it will pass my question into my Magic Cloudlet. My cloudlet again will use my query to retrieve relevant context data, which it returns to OpenAI. ChatGPT will use this context data to answer my question.
A Magic cloudlet allows you to upload thousands of documents, scrape your website, and add a lot more sources for your data than the default upload document feature from OpenAI. This allows us to extend the 20 document upload restriction OpenAI added to custom GPTs by a lot.
Every time a user asks your GPT a question, ChatGPT will invoke your endpoint, passing in the query to Magic, allowing Magic to use VSS and RAG to retrieve relevant data. Magic will return the data it finds to ChatGPT, which will use the context to answer the user's question.
The Code
Below you can find the Hyperlambda code I use in the video - Or rather a simplified and stronger version of the code.
.arguments
query:string
.description:Returns context from your training snippets as a string, using VSS search through your training data.
// Making sure caller passed in a [query] argument since this argument is mandatory.
validators.mandatory:x:@.arguments/*/query
// Invoking slot responsible for retrieving context.
unwrap:x:./*/signal/*
signal:magic.ai.get-context
type:ainiro_io
vector_model:text-embedding-ada-002
prompt:x:@.arguments/*/query
threshold:decimal:0.3
max_tokens:int:2000
// Returning result to caller.
unwrap:x:+/*
return
context:x:@signal/*/context
Use the above code, create an endpoint according to the instructions from the video, and make sure your GPT is using some sort of system message resembling the following.
- Use the get-context action for all questions I ask to retrieve context to answer my question.
- Preserve Markdown as is, such as for instance images, and return relevant images as Markdown.
- If you cannot find the answer to my question, inform me that you don't know the answer, and encourage me to provide some keywords such as AINIRO, chatbot or AI Search to give it more context to work from.
Notice our little "Markdown trick" in the above instruction. Since Magic allows you to declare image references as Markdown, this allows you to have a custom GPT that display images, such as illustrated below.
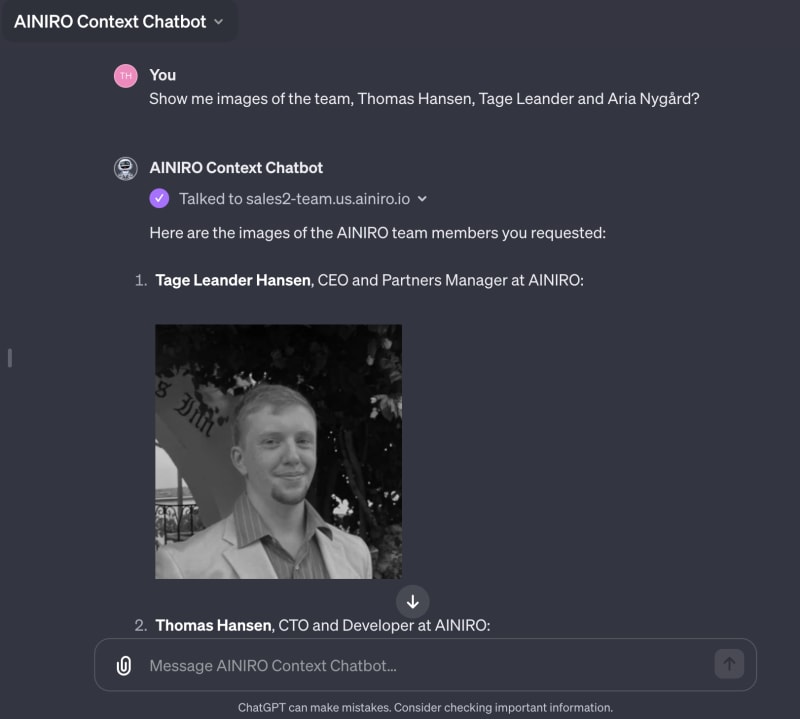
Also notice that the above endpoint will return maximum 2,000 OpenAI tokens due to its max_tokens:int:2000 parameter to our slot invocation. If you want to you can modify this number. If you do, make sure you don't overflow your model such that it returns too much data for ChatGPT to be able to answer your question. I made the GPT I created in the above publicly available if you want to try it.





Top comments (0)