When designing your data models you should always have one important thing in mind: how do I index it ?
Indexes can make your data consumption faster and easier. A query that will take 2 seconds to complete without an index, can take only a few milliseconds to complete with one.
In MongoDB, indexes are the difference between a full collection scan, and a quick index scan.
Without Indexes, MongoDB will have to do a collection scan for every query it executes.
A collection scan is where MongoDB needs to check every document in a collection in order to find if it's suitable for the given query.
For example, lets assume we have a movies collection.
The model for each document will look as follows:
_id: ObjectId,
name: String,
description: String,
genres: String[],
writers: String[],
directors: String[],
actors: String[],
length: Number,
rating: Number,
release: Date,
location: {
country: String,
city: String
},
reviews: {
reviewer: String,
review: String,
date: Date
}[]
And our query will request all the movies that have a rating greater than 8.
db.collection.find({ rating: { $gt: 8 } })
This query, without an index on the rating field, will cause MongoDB to scan each document in our movies collection and check if its rating is greater than 8.
This can be perfectly fine for smaller collections and queries that do not need to return results quickly.
However, In bigger collections, a collection scan can make your app into the perfect loading screen viewer.
To solve this issue, we will want to use indexes, and use them right.
MongoDB Indexes
In MongoDB indexes are B-Trees that hold a portion of the data set.
An index can store a specific field from the documents (Single Field Index) or a set of fields (Compound Index), ordered by the field's value.
MongoDB allows to index any type of field in a document.
Types of Indexes
MongoDB has several types of indexes, each one of them is meant for a different type of field or for different type of query.
Single Field Index
A single field index is an index assigned to one specific field of the document,
the index will be a sorted structure of this field that will point to the documents in our collection.

In this example, an ascending index was created on the rating field { rating: 1 }.
This index will create a structure, ordered by the rating field, where every item in this structure 'points' to the connected document in the collection.
In order to create a single field index we will need to execute the following command:
db.<collection>.createIndex({<field>: <type>})
The type of the index (1 or -1) describes the order of the items in our index, where 1 means ascending order and -1 means descending order.
In our case:
db.movies.createIndex({ rating: 1})
This command will create an ascending index on our rating field in our movies collection.
We can also create a single field index on an embedded field (a field inside another field) when using a dot notation:
db.movies.createIndex({location.country: -1})
This command will create a descending index on the country field inside the sub-document, location, in the movies collection.
Furthermore, a single field index can also be created on an entire embedded document, for example:
db.movies.createIndex({location: 1})
This command will create an index on the location field as a whole.
In order to use this index, the query will need to specify all the fields of the sub-document in the same order it's listed in the index and in the documents in our collection.
Compound Index
A compound index is an Index that can hold multiple fields of the document at once (up to 32 fields).
When creating a compound index, each field can have a different sorting order.
The first field will determine the initial order of the documents, the second field will determine the order of all the documents that don't have a unique value on their first field (their value of the first field appears in more than one document).
The next index fields will do the same for the next 'sorting layers'.
For instance, if we create an index on { length: 1, rating: -1 } the index will be ordered from the shortest video to the longest one. if several videos have the same length, they will be ordered by their rating, from higher to lower.

This example shows how the index is ordered first by the length of the movie and then, when the length of several movies is the same, it's ordered by their rating.
Compound indexes will be useful for queries containing multiple fields, like:
db.collection
.find({
length: {$gt: 60, $lt: 90},
rating: {$gt: 8}
})
.sort({rating: -1})
when creating a compound index on the length and the rating fields, our index will "support" the query, therefore, it will execute faster.
An index will support a query when all the fields that appear in the query, also appear in the index.
When the index supports the query MongoDB will only scan the index and not the documents, therefore, there will be a huge performance boost.
In order to create a compound index you will need to execute the following command:
db.<collection>.createIndex({
<field1>: <type>,
<field2>: <type>,
...
})
In our case:
db.movies.createIndex({length: 1, rating: -1})
This index will be a compound index on the length and rating fields, where length will be sorted by an ascending order and rating will be sorted in a descending order.
Multikey Index
An index on an array field is called a multikey index.
Multikey indexes can be constructed from array fields containing scalar values (numbers, strings, etc…) or from array fields containing nested documents (like the reviews field in our movies collection).
The command to create a multikey index is not different from the one to create a single field index
db.<collection>.createIndex({ <field>: <type> })
Compound multikey indexes are possible, however, only one of the fields can be an array (in a specific document).
For example, a compound multikey index can not be created on the writers &
directors fields, because both of them are arrays
// Will not work
db.movies.createIndex({ writers: 1, directors: -1 })
This command will work if for every document, only one of those fields is an array, so document_1 can have writers as array and directors as string, and document_2, at the same time, will have writers as string, and directors as array.
Furthermore, if an index was already created, new documents that violate the index (2 or more of the index fields are arrays) will fail to get inserted into the collection.
However, a compound multikey index on the writers and rating fields, will work.
db.movies.createIndex({ writers: 1, rating: -1 })
Text Index
Text indexes support text search queries on string content, they can include fields of type String, or, array of Strings.
Each collection can have only one text index (but this index can be structured on multiple fields).
In order to create a text index on a single field, execute the following command:
db.<collection>.createIndex({<field>: "text"})
For multiple fields:
db.<collection>.createIndex({
<field1>: "text",
<field2>: "text",
...
})
As mentioned, text indexes support $text query operations:
db.<collection>.find({
$text: {
$search: <string>,
$language: <string>,
$caseSensitive: <boolean>,
$diacriticSensitive: <boolean>
}
})
This query will search for the string, specified in the $search field, in all the fields specified in our text index.
For example, in our movies collection, we will create the following text index:
db.movies.createIndex({
name: "text",
description: "text",
genres: "text",
writers: "text",
directors: "text",
actors: "text"
})
And we will execute the following query:
db.movies.find({
$text: {
$search: "Arnold"
}
})
This query will search on all the fields we specified in our text index; name, description, genres, writers, directors and actors.
This means that if the name "Arnold" appears in one of those fields inside a document, the document will "return" to us.
Text indexes can have weights.
Weights can be given to each field in the text index in order to give them priority over other fields when doing a text search.
To give weight to a field, specify the weight in the options:
db.<collection>.createIndex({
<field1>: "text",
<field2>: "text"
},
{
weights: {
<field1>: <weight1>,
<field2>: <weight2>
}
})
In our case:
db.movies.createIndex({
name: "text",
description: "\"text\","
genres: "text",
writers: "text",
directors: "text",
actors: "text"
},
{
weights: {
name: 4,
description: "2"
}
})
Our name field has a weight of 4, description field has a weight of 2 and all the other fields have the default value of 1.
That means that name has twice the impact of description and description has twice the impact of any other field (like genres and writers).
Which fields should we index ?
Supporting Query Fields
In order to make MongoDB scan the index and not the collection, while executing a query, we should index fields that "support" that query.
An index will support a query when it contains all the fields the query specifies.
For example:
db.movies.createIndex({genres: 1, rating: -1})
will support the following query:
db.movies.find({genres: 'Horror', rating: {$gt: 6}})
The index we created contains all the fields the query specifies (genres & rating), therefore, it will support it.
A compound index's can also support queries that specify the fields of the prefix (and nothing more).
An index Prefix is the subset of a compound index's fields, from start to finish.
For example:
db.movies.createIndex({genres: 1, rating: -1, length: 1})
has the following prefixes:
{genres: 1}
{genres: 1, rating: -1}
Therefore, the following queries will be supported:
db.movies.find({genres: 'Comedy', rating: 5, length: {$lte: 120}})
db.movies.find({genres: 'Sci-Fi', rating: 8})
db.movies.find({genres: 'Documentry'})
That's why our index will also support the next query:
db.movies.find({genres: 'Drama'})
Even though the query doesn't contain the 'rating' field, the index will support it because it's prefix contains the 'genres' field, the only field in the query.
Supporting Sort Fields
An Index will support a sort when:
The order of the fields in the sort is equal to the order of the fields in the index.
Sorting with Single Field Index
When doing a sort operation on a descending/ascending single field index using the indexed field as the sort rule, the index will always support the sort.
For example:
db.movies.createIndex({ rating: 1 })
will support the following sorts:
db.movies.find().sort({ rating: 1 })
db.movies.find().sort({ rating: -1 })
This index support a descending order as well (even though the index is ascending) because MongoDB can reverse it's order.
Sorting with Compound Index
A compound index can support sorting on multiple fields.
In order to support a sort, a compound index will have to:
- Define it's fields in the same order of the sorted fields
db.movies.createIndex({ length: 1, rating: 1 })
Will support
db.movies.find().sort({ length: 1, rating: 1})
But, it won't support:
db.movies.find().sort({ rating: 1, length: 1})
- Define the same order for it's fields as the sort specified, or, define the complete opposite order for them.
db.movies.createIndex({ length: 1, rating: -1 })
will support
db.movies.find().sort({ length: 1, rating: -1})
db.movies.find().sort({ length: -1, rating: 1})
but won't support
db.movies.find().sort({ length: 1, rating: 1})
db.movies.find().sort({ length: -1, rating: -1})
A compound index can also support a sort with it's prefix:
The prefix will have to obey the same rules stated above.
db.movies.createIndex({ length: 1, rating: -1, location.city: 1 })
will support the following sorts:
db.moveis.sort({ length: 1 })
db.moveis.sort({ length: -1 })
db.moveis.sort({ length: 1, rating: -1 })
db.moveis.sort({ length: -1, rating: 1 })
db.moveis.sort({ length: 1, rating: -1, location.city: 1 })
db.moveis.sort({ length: -1, rating: 1, location.city: -1 })
If the sort can't get the sorting order from the index, it will have to do the sort in memory.
More often than not, getting the sort order from the index have better performance than doing the sort in memory (without an index).
Furthermore, sorting in memory has it's limits, if an index is not used, the sort will abort if it uses 32 MB of memory.
Things to notice
Index should fit in ram
In order to maximize index's performance, it should fit entirely in Memory.
Index selectivity
In order to create a truly useful index, it needs to separate the data as much as possible.
For example, let's assume our rating in our movies collection is a value between 1 to 3, that means, that if we create an index on the 'rating' field, it will only separate the documents into 3 sections (rating: 1, rating: 2, rating: 3).
However, if we create an index on the 'release' field the data will separate into many small sections, each section will represent all movies that were released in that day.
Hands on
In order to truly know which fields we should index, we need to know the queries we will execute.
Let's assume our movies application have 3 main features that it needs to have:
- Search a movie by it's name, description, genres, writers, directors and actors.
- Get a sorted list of movies by their genre & rating.
- Get a list of movies a certain actor has played in.
For each query, I have used explain in order to get relevant information about it.
I've run a test with 20 stages for each query, were each stage represents a different amount of documents in the movies collection.
Each stage added 10k documents to the movies collection and then executed each query 200 times, 100 time with a relevant index and 100 times without an index.
Total amount of queries executed per stage is: 2 x 3 x 100 = 600.
First Query
Our first query will need to find movies when we search for them using a string, probably from a search bar. The query will search for our string in the name, description, genres, writers, directors and actors fields.
db.movies.find({
$text: {
$search: "Human"
}
});
Without an index, we won't be able to do a $text $search, so our query will need to look as follows:
db.movies.find({
$or: [
{ name: { $regex: 'Human', $options: "i" } },
{ description: { $regex: 'Human', $options: "i" } },
{ genres: { $regex: 'Human', $options: "i" } },
{ writers: { $regex: 'Human', $options: "i" } },
{ directors: { $regex: 'Human', $options: "i" } },
{ actors: { $regex: 'Human', $options: "i" } }
]
});
If we create the following text index, we will be able to use the $text $search
db.movies.createIndex({
name: "text",
description: "text",
genres: "text",
writers: "text",
directors: "text",
actors: "text"
})
Let's compare our results, with, and without an index.


Bonus data from the last stage:
Documents returned:
- Not Indexed: 9,868
- Indexed: 9,868
Total documents examined:
- Not Indexed: 200,000
- Indexed: 9,868
Second Query
Our second query will look as follows:
db.movies.find({genres: "Fantasy"}).sort({rating: -1});

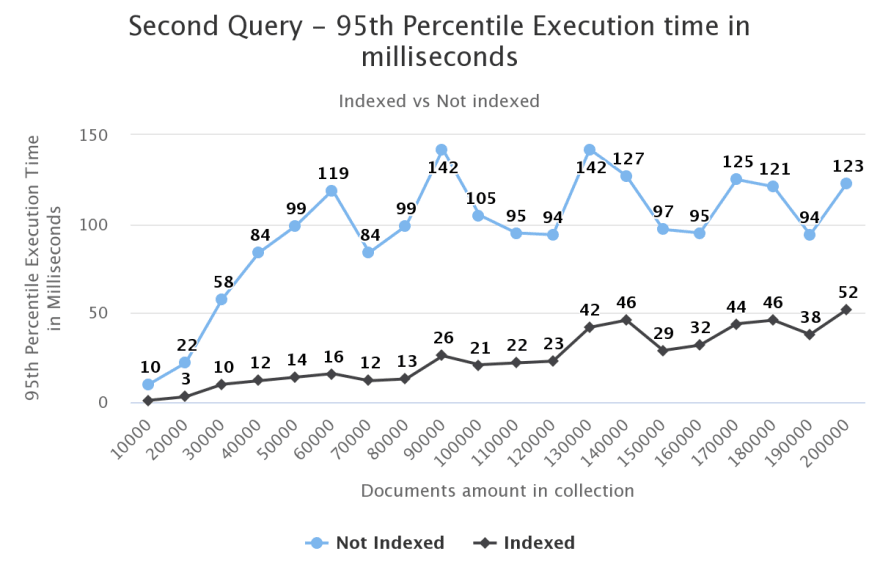
Bonus data from the last stage:
Documents returned:
- Not Indexed: 0
- Indexed: 19,957
Total documents examined:
- Not Indexed: 91,605
- Indexed: 19,957
We can see something out of the ordinary in this data...
The amount of documents returned in the Indexed query is not equal to the amount returned in the not indexed one...
When executing this query when an index is not found, no documents return to us.
Why is that?
That happens because we also do a sort operation in this query and when we do not have an index, our sort has a limit of 32mb used in memory (as noted above).
Therefore, our not indexed query reaches that limit, and the query gets cancelled.

As we can see in the chart above, our sort becomes too demanding when our collection has 100k documents.
Third Query
Our third, and last, query will look as follows:
db.collection.find({actors: 'Jules Strosin'});

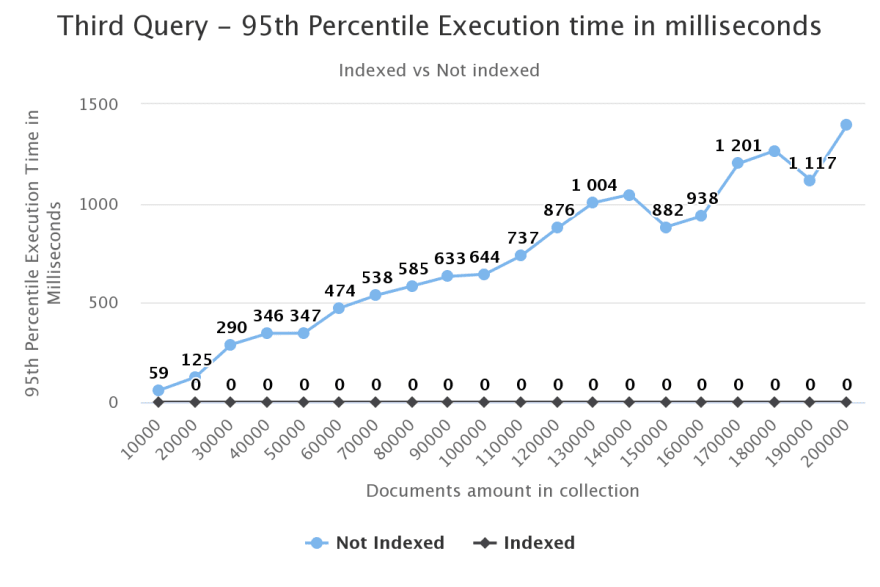
We can see that the index in this query had a huge impact on performance, from more an execution time of more than a second to less than a millisecond.
Bonus data from last stage:
Documents returned:
- Not Indexed: 11
- Indexed: 11
Total documents examined:
- Not Indexed: 200,000
- Indexed: 11
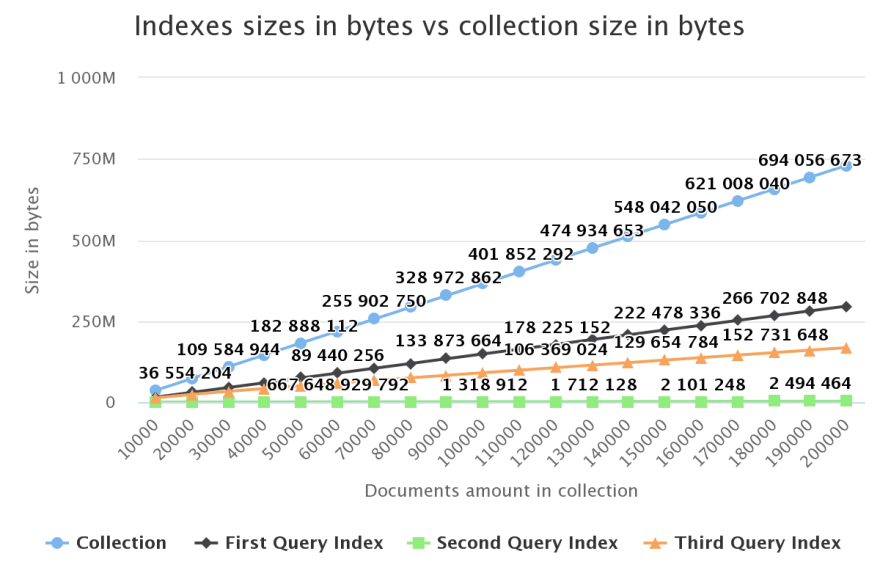
Bonus
Indexes might have a huge, positive impact on performance, but they can also get pretty big, some can get well over 1gb.
You should always check the size of your indexes and remember that a memory stored index is a lot faster than a disk stored one, so make sure they have the space they need.
Conclusion
Indexes can make your queries faster and simpler, as well as prevent them from failing in certain situations.
However, they do have a size, and it needs to be regarded.
Before making an index, think which queries you want to optimize and which fields the index should contain in order to do so.
Please Note
Geospatial and Hashed Indexes were not covered in this article, for further reading about those you can visit 2dsphere indexes and Hashed Indexes.





Top comments (2)
Great idea how to explain this topic. I think I have understood it better now :-)
Thanks!