
Natural language processing, which is also known as NLP can be easily explained by the figure present below.

So basically it means that as we speak it creates certain meaningful sentence or we can say data by which our brain is able to understand what others are speaking and even what we are speaking, similarly NLP help the artificial brain to create a meaningful data out of the bunch of data it has received.
Let's first point out the basic procedure of almost every NLP or sentence-related intelligence experiment.
- A human talks to the machine(input, it may be in audio form or may be in text form)
- The machine captures the audio
- Audio to text conversion takes place(if the input is in audio form)
- Processing of the text’s data
- Data to audio conversion takes place(after predicting the required output)
- The machine responds to the human by playing the audio file
so let's relate this a little bit to our day-to-day life, The various examples of NLP that we are observing are the chatbots, The auto-corrects, Personal assistant applications such as OK Google, Siri, Cortana, and Alexa.
Now let's jump into the code/fun part i.e how a machine understands the data.
for example:
- He is a boy
- she is a girl
| name | gender | human |
|---|---|---|
| Ram(boy) | boy(1) | 1 |
| sita(girl) | girl(0) | 1 |
Basically, each word In a sentence that the machine obtained is converted in word vectors that mean into some numeric values and these numeric values play different roles according to their presence in a sentence,e.g.boy and girl plays a different role under gender category but they play the same role under the human category.
Now let's have a look at how these word vectors are formed.we are going to use the NLTK library.it has several features which you can use by first installing all of them:
import nltk
nltk.download('all')
now you can easily convert your paragraph into sentences or even words to preprocess your text more specifically.
e.g.
for converting paragraph to sentences
nltk.sent_tokenize(paragraph)
for converting sentences to words
nltk.word_tokenize('sentences')
Here are some Computer algorithms are used to apply grammatical rules to a group of words and derive meaning from them.
- Lemmatization: It entails reducing the various inflected forms of a word into a single form for easy analysis.
- Morphological segmentation: It involves dividing words into individual units called morphemes.
- Part-of-speech tagging: It involves identifying the part of speech for every word.
- Sentence breaking: It involves placing sentence boundaries on a large piece of text.
- Stemming: It involves cutting the inflected words to their root form.
There are many more like word2vec , bagofwords ,Transformers , encoder & decoders and some most powerful like BERT etc.
But mostly between stemming and lemmatization lemmatization is preferred because it includes calculation based on log values
Now let's see a simple example of Natural entity recognition using NLP
importing the libraries
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
converting each category of entity into a respective vector
from bs4 import BeautifulSoup
import requests
import re
def url_to_string(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, 'html5lib')
for script in soup(["script", "style", 'aside']):
script.extract()
return " ".join(re.split(r'[\n\t]+', soup.get_text()))
ny_bb = url_to_string('https://en.wikipedia.org/wiki/Wikipedia')
article = nlp(ny_bb)
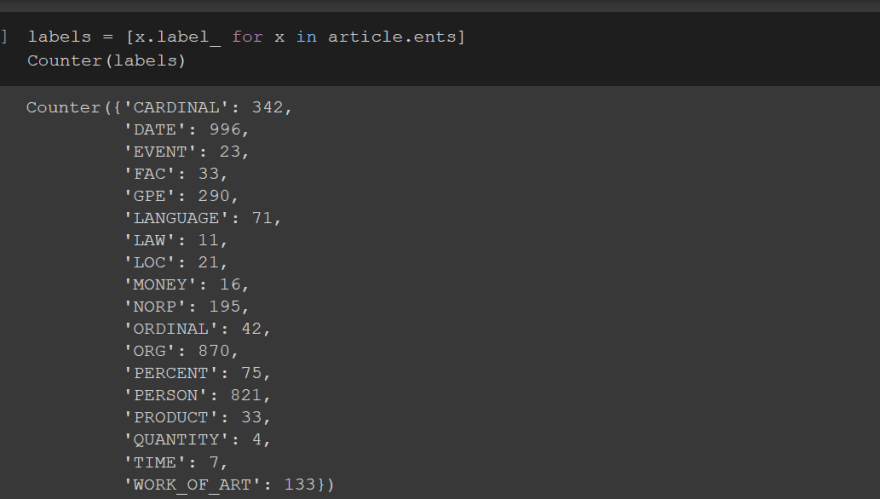
now marking the entities given using some predefined styling
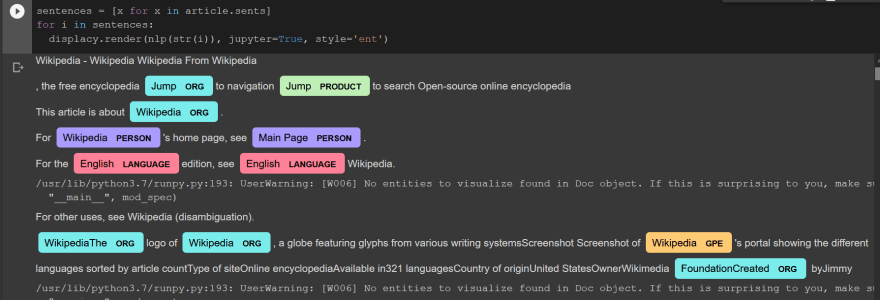
So, That's a brief on what is NLP and how it can be used in every text-related data, and how to preprocess those types of data.
For more preprocessing related stuff do checkout my GitHub profile:https://github.com/Ashishkumarpanda
Do give your reviews on this,
Thank you for reading :)





Top comments (1)
Those interested in NLP basics without the code, read this: devopedia.org/natural-language-pro...