1. Understanding the Problem of Large Data Queries
REST APIs often interface with databases or file systems to retrieve data. However, when dealing with massive datasets, directly loading the data into memory can lead to out-of-memory errors. Imagine a REST endpoint that queries millions of records from a database—if the entire dataset is loaded into memory at once, the server can easily run out of resources.

1.1 The Consequences of Not Handling Large Data Queries
If large data requests aren’t handled appropriately, it can lead to:
- OutOfMemoryErrors that crash the server.
- Increased response time , resulting in poor user experience.
- System slowdowns due to the overwhelming amount of data processing at once.
So, how can we design REST APIs that scale effectively even when querying large amounts of data?
1.2 Solutions Overview
We will cover three primary techniques that can help handle REST endpoints when the queried data is larger than the available memory:
- Pagination : Fetch data in chunks by splitting large datasets into smaller, manageable pieces.
- Streaming : Stream the data directly from the data source, sending it to the client piece by piece.
- Batch Processing : Divide the data processing task into multiple, smaller batches.
Let’s delve deeper into each method and explore how they can be implemented in a REST API.
2. Implementing Pagination for REST API Queries
Pagination is one of the simplest and most effective techniques for handling large data queries. It works by splitting the data into smaller, manageable parts, allowing clients to request data one page at a time.

2.1 How Pagination Works
Pagination is typically implemented using query parameters like page and size. For example, a request might look like this:
GET /api/data?page=1&size=100
In this scenario:
- page=1 indicates that the client wants the first set of results.
- size=100 specifies that the client wants 100 records per request.
The backend will then retrieve only the requested records from the database and send them in the response, along with pagination metadata.
2.2 Code Example for Pagination
@GetMapping("/data")
public ResponseEntity<List<Data>> getData(
@RequestParam(value = "page", defaultValue = "0") int page,
@RequestParam(value = "size", defaultValue = "100") int size) {
Pageable pageable = PageRequest.of(page, size);
Page<Data> resultPage = dataRepository.findAll(pageable);
return new ResponseEntity<>(resultPage.getContent(), HttpStatus.OK);
}
In this code:
- We are using Spring Data’s Pageable interface to handle pagination.
- The dataRepository will only query the number of records specified by the size parameter, starting from the offset determined by the page.
2.3 Demo and Results
If you query the endpoint like this:
GET /api/data?page=0&size=50
The server will respond with 50 records. The user can then request the next set by increasing the page number.
Response example:
{
"data": [...],
"page": 1,
"size": 50,
"totalPages": 10
}
By implementing pagination, the server is only tasked with fetching and processing small chunks of data, ensuring that the memory is not overwhelmed.
3. Leveraging Streaming for Large Data Queries
For cases where the data is too large for pagination, or where real-time data flow is required, streaming provides a powerful alternative. Streaming allows data to be sent to the client as it is being processed, rather than waiting for the entire dataset to be fetched.
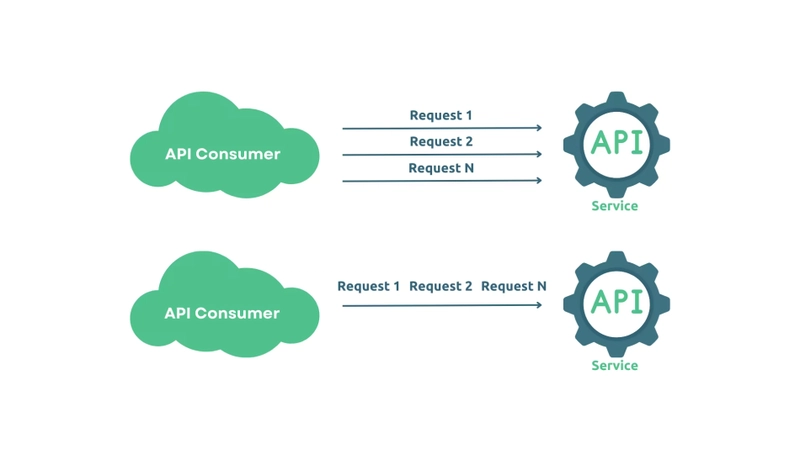
3.1 How Streaming Works
With streaming, the server retrieves data from the database or data source in chunks and sends each chunk to the client as soon as it is ready. This ensures that the client receives the data progressively without overwhelming the server's memory.
3.2 Code Example for Streaming
Here’s how you can implement streaming in Spring Boot using Jackson Streaming API:
@GetMapping("/stream-data")
public void streamData(HttpServletResponse response) throws IOException {
List<Data> dataList = dataRepository.findAll();
response.setContentType("application/json");
ObjectMapper objectMapper = new ObjectMapper();
JsonGenerator jsonGenerator = objectMapper.getFactory().createGenerator(response.getWriter());
jsonGenerator.writeStartArray();
for (Data data : dataList) {
objectMapper.writeValue(jsonGenerator, data);
response.flushBuffer(); // Send data as it becomes available
}
jsonGenerator.writeEndArray();
jsonGenerator.close();
}
In this code:
- We fetch the data from the repository in a list.
- The data is then written to the response stream incrementally using JsonGenerator.
- The flushBuffer() method ensures that the data is sent to the client in chunks as soon as it is ready.
3.3 Demo and Results
By calling this endpoint, the client will start receiving data immediately without waiting for the entire dataset to be loaded. This allows the API to handle very large datasets efficiently.
Response example:
[
{"id": 1, "name": "Item 1"},
{"id": 2, "name": "Item 2"},
// Data keeps coming as it is processed
]
With streaming, we avoid loading the entire dataset into memory at once, while ensuring that the client receives data continuously.
4. Batch Processing for Heavy Data Requests
Batch processing is a technique where large datasets are divided into smaller batches, and each batch is processed separately. This approach is useful when processing each batch requires some intensive work, such as transforming or enriching data.
4.1 How Batch Processing Works
Batch processing breaks down a large request into multiple smaller jobs. Each job processes a subset of the data, ensuring that no single job exceeds memory limits.
4.2 Code Example for Batch Processing
Here’s an example using Spring Batch to process data in chunks:
@Bean
public Step processStep() {
return stepBuilderFactory.get("processStep")
.<Data, ProcessedData>chunk(100)
.reader(dataReader())
.processor(dataProcessor())
.writer(dataWriter())
.build();
}
In this example:
- The chunk(100) method specifies that we will process 100 records at a time.
- The reader fetches data, the processor transforms it, and the writer saves the processed data.
4.3 Demo and Results
If a client requests a large dataset, it will be processed in chunks of 100 records. This ensures that the system's memory isn’t overloaded, and each batch can be handled efficiently.
5. Conclusion
Handling large data queries in REST APIs requires careful consideration and the right approach. By using techniques like pagination, streaming, and batch processing, you can efficiently manage large datasets without overwhelming system resources.
If you have any questions about these strategies or need further clarification, feel free to leave a comment below!
Read posts more at : Strategies for Handling a REST Endpoint That Queries More Data Than Available Memory

Top comments (0)