In the previous post we set up Apache Drill, Minio and PostgreSQL to set up a basic pipeline of data processing.
In this installment we are allso going to incorporate Kafka and show how we can merge the relational and realtime events.
Connecting to Kafka
With an existing kafka setup open up the Apache Drill Storage tab and click on Update next to the inactive Kafka source:

Sending Data to Kafka
Create a topic
Open a terminal and run the topic create command:
$ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic purchase-events --partitions 1 --replication-factor 1
Created topic purchase-events.
Publish some JSON
Open a terminal in your KAFKA_HOME and run the kafka-consumer command:
$ bin/kafka-console-producer.sh --topic purchase-events --bootstrap-server localhost:9092
>
The scenario we will use is that once the main system has approved a payment, it will send a message to Kafka showing the transaction details and the approval status (SUCCESS or FAILED). There are some example JSON structures below:
{ "txn_id" : 12346, "store_id" : "45873AD", "cust_id" : "02145SYD", "amnt" : 122.49, "status" : "SUCCESS" }
{ "txn_id" : 12348, "store_id" : "78534AS", "cust_id" : "26354MLB", "amnt" : 16.01, "status" : "FAILED" }
{ "txn_id" : 12345, "store_id" : "98369AS", "cust_id" : "98764TGH", "amnt" : 34.99, "status" : "SUCCESS" }
{ "txn_id" : 12348, "store_id" : "78534AS", "cust_id" : "26354MLB", "amnt" : 16.01, "status" : "SUCCESS" }
{ "txn_id" : 12334, "store_id" : "92374SS", "cust_id" : "45268PER", "amnt" : 89.99, "status" : "FAILED" }
{ "txn_id" : 12352, "store_id" : "98674DC", "cust_id" : "25478MLB", "amnt" : 30.12, "status" : "SUCCESS" }
In your Drill Query console, run the following query:
select * from kafka.`purchase-events`;
You should get a table representing:
- data
- kafka topic
- kafka partition id
- message offset
- message timestamp

Merging the RDBMS data with Realtime data
To actually make this data handy, what we will do is use the following scenario:
- User has submitted their order and the order is stored in PostgreSQL
- Our Order Service has submitted a request to the Payment Service to clear a payment for the order
- The Payment Service sends the transaction details and payment status to Kafka once it has completed the request
- We want to then view a quick report on the orders that are being placed and their status.
- Successful orders will then be sent to stores to be fulfilled.
To satisfy this, we will take the order information from our Order service and process only successful orders.
(next article we will add actions for items that have failed)
Create the order PostgreSQL table
Run the following script to create the database, role and tables and insert some data:
create database sales_db;
create role sales_admin with password 'letmein' login;
grant all on database sales_db to sales_admin;
create table purchase_order (
order_id bigint generated always as identity,
order_total numeric(5,2),
store_id varchar(12),
customer_id varchar(12),
order_status varchar(20) DEFAULT 'SUBMITTED'
);
alter table purchase_order add constraint pk_order PRIMARY KEY (order_id);
insert into purchase_order (order_total, store_id, customer_id) values (12.56, 'STORE_1', 'CUST_12');
insert into purchase_order (order_total, store_id, customer_id) values (122.65, 'STORE_15', 'CUST_89');
insert into purchase_order (order_total, store_id, customer_id) values (56.98, 'STORE_43', 'CUST_51');
insert into purchase_order (order_total, store_id, customer_id) values (35.00, 'STORE_1', 'CUST_61');
select * from purchase_order;
order_id | order_total | store_id | customer_id | order_status
----------+-------------+----------+-------------+--------------
1 | 12.56 | STORE_1 | CUST_12 | SUBMITTED
2 | 122.65 | STORE_15 | CUST_89 | SUBMITTED
3 | 56.98 | STORE_43 | CUST_51 | SUBMITTED
4 | 35.00 | STORE_1 | CUST_61 | SUBMITTED
We want some data that matches up to our database in the kafka topic so lets push the fresh data on the kafka-console-producer:
{ "txn_id" : 1, "store_id" : "STORE_1", "cust_id" : "CUST_12", "amnt" : 12.56, "status" : "SUCCESS" }
{ "txn_id" : 2, "store_id" : "STORE_15", "cust_id" : "CUST_89", "amnt" : 122.65, "status" : "FAILED" }
{ "txn_id" : 3, "store_id" : "STORE_43", "cust_id" : "CUST_51", "amnt" : 56.98, "status" : "FAILED" }
{ "txn_id" : 4, "store_id" : "STORE_1", "cust_id" : "CUST_61", "amnt" : 35.00, "status" : "SUCCESS" }
Create our query
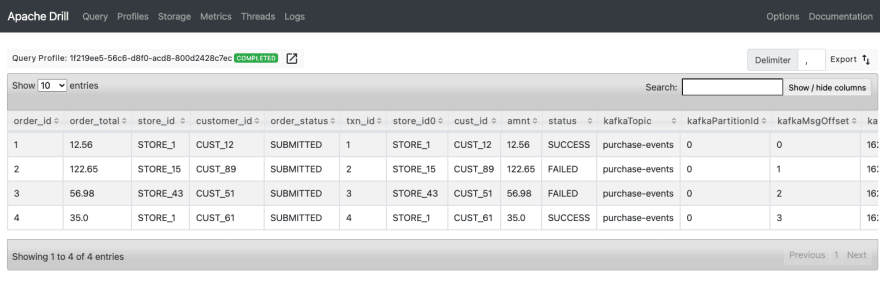
Now that we have some data in our database and topic, let's create a topic to join the data:
select p.*, e.*
from kafka.`purchase-events` e
join salesdb.`purchase_order` p
on p.order_id = e.txn_id;
If successful, you should now have realtime data being matched with what is in your database!
Next
Next article we will set up orchestration of all these events using another Apache open source project called Airflow.





Top comments (0)