
Resolvi fazer a minha implementação da rinha de backend essa semana, e a experiência que tive foi bastante interessante e até contra-intuitiva em alguns pontos, nesse artigo pretendo listar exatamente as técnicas que aprendi para escalar minha aplicação.
Fazendo um resumo breve, a Rinha de Backend foi uma competição criada pelo @zanfranceschi onde cada participante sobe um serviço, com um limite máximo de 3GB de RAM e 1.5 CPUs, contendo no mínimo 4 elementos: 2 instâncias de uma API feita em qualquer linguagem, 1 nginx para baleancear a carga entre as APIs e um banco para persistência de dados em disco. Esse serviço precisa aguentar um teste de estresse com Gattling, cujo código do teste foi feito pelo próprio @zanfranceschi em Scala.
No final minha implementação conseguiu aguentar o teste de estresse de 58 mil requisições em 3min, dando a média de quase 281 requisições por segundo.

Pra entender os requisitos da implementação basta acessar o repositório da Rinha.
Para ver minha implementação basta acessar o meu repositório. No meu caso, implementei a API em Golang e usei o banco postgres para persistência em disco.
Aprendi muitas coisas importantes sobre escalabilidade com esse desafio, e aqui vou pontuar as que mais fizeram diferença no resultado final da performance da minha aplicação:
Índice em campo único
Um dos pontos do stress test é fazer uma massiva busca por termos.
Dado um termo, a API deverá retornar os 50 primeiros resultados de registros no banco (que são as pessoas), cujo termo esteja presente no campo "apelido", "nome" ou em algumas das "stacks", que representa um array de strings.
Para facilitar a consulta, criei um campo no banco chamado de "search_index", esse campo, do tipo varchar, une todos os outros campos num único texto, assim a pesquisa pode ser direcionada unicamente para este campo.

Além disso, adicionei um índice do tipo GiST nesse campo, o que aumentou drasticamente a performance das consultas.
Channels e goroutines para processamento concorrente
Channels são canais de comunicação entre threads no Golang, e isso é útil para delegar a tarefa de inserir no banco de dados para uma thread diferente daquela que está lidando com a requisição do Gattling, assim podemos responder à requisição mais rapidamente.
Fiz com que a rota para criação de uma pessoa não inserisse no banco diretamente, mas sim enviasse para um channel, onde do outro lado há um worker recebendo esses dados numa goroutine. O worker recebe a pessoa da channel e insere num slice e, quando o slice atingir 1000 pessoas, o worker faz um batch insert no banco de dados.
Num projeto em produção, onde eu deveria me preocupar com consistência dos dados, substituiria a channel por um sistema de filas como kafka ou rabbitMQ, ou até mesmo filas do Redis, para que os dados não fiquem em memória, mas não era necessidade para o desafio, então optei por sacrificar a consistência por ganho de performance.
A vantagem foi que a inserção é feita em apenas uma operação, usando apenas uma conexão com o banco, e gerenciado por um worker que está rodando numa thread diferente da requisição dos usuários.
Cache
Utilizei Redis para criar gerenciamento do cache de cada pessoa. Ao acessar a rota de criar pessoa a API, antes de enviar o recurso para o channel, salva o ID e o apelido no cache.
Esse cache otimizou a consulta, já que o endpoint de consultar pessoa poderia buscar os dados direto no cache com o ID, mas também otimizou a criação, já que existe uma constraint que impede a pessoa de ser registrada caso o apelido já esteja em uso por outra pessoa. Então antes de enviar para o channel a API faz uma busca por apelido no cache, e, caso já esteja em uso, retorna imediatamente uma mensagem de erro.
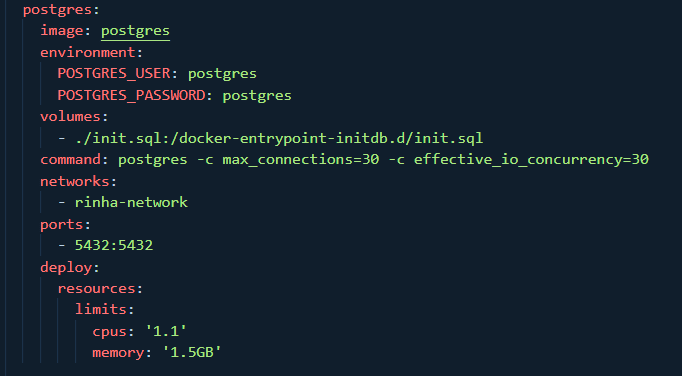
Limitação de conexão do nginx e postgres
Essa foi a parte mais interessante, e esse é o tópico que dá nome ao artigo...
A ganho mais significativo de performance que a minha implementação teve foi, sem dúvidas, quando DIMINUI DRASTICAMENTE a quantidade de conexões máximas, tanto do nginx quanto do postgres.
Minha configuração inicial do nginx permitia até 2048 conexões simultâneas na minha instância, e a do postgres permitia até 300 conexões no máximo. O problema é que, dado um cenário de recursos limitados - 3GB de RAM e 1.5 CPUs -, o maior gargalo está no fluxo de entrada de novas requisições.
Cada conexão com o postgres é um fork de um processo, e isso custa CPU, portanto, num cenário de escassez, a solução mais eficiente é limitar o número máximo de requisições simultâneas, assim o banco consegue gerenciar de forma mais eficiente as conexões existentes. Diminuí o número máximo de conexões de 300 pra 30, e com cada API tendo um pool máximo de 15, e isso já diminuiu o uso de CPU do postgres de 100% no pico para, no máximo, 50%. Foi uma mudança considerável.
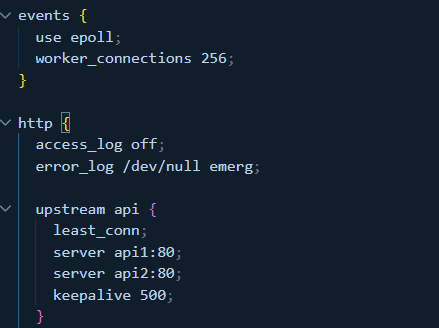
Quanto ao nginx, diminuí o número de worker connections para 256, a ideia é que, como as requests virão de qualquer forma, o mais importante é controlar o fluxo de entrada para que conexões não sejam feitas em quantidades maiores do que o postgres e redis são capazes de lidar. Isso aumenta o tempo de espera do cliente para a conexão ser estabelecida, mas o mesmo tempo impede um overhelm da nossa aplicação e diminui o consumo de recursos de forma concorrente.
No fim, a maior lição aprendida é que, no quesito escalabilidade, as vezes menos é mais. Simplificar a aplicação, abrir mão de processamentos desnecessários e limitar as conexões para garantir que a CPU dará conta do fluxo de entrada pode fazer mais diferença do que otimização com algoritmos, refatoração do código ou buscar o framework/linguagem perfeita.



Top comments (0)