Let's compare these two open-source libraries: Selenium, the more mature option that has been around for over a decade, and Playwright, its more recent competitor from Microsoft.
Why use Playwright or Selenium?
Both are easily the most popular libraries for controlling headless browsers. Here are some of the most common challenges they can handle:
RPA, web automation, workflow automation: clicking buttons, filling out forms, etc.
Automation testing: UI testing, end-to-end testing, performance testing, service worker testing, testing Chrome Extensions
Extracting data from multiple pages or websites concurrently
More specifically, here are tasks that Selenium and Playwright can complete for web scraping and web automation:
Running scripts in headless mode
Handling cookies and sessions
Handling frames and iFrames
Handling pop-ups and alerts
Using proxy servers or VPNs to change the IP address of the scraper
Bypassing anti-scraping measures and CAPTCHAs
Taking screenshots of web pages
Recording and playing back web actions and interactions
🧪 What is Selenium?
Selenium is a popular open-source web testing automation tool of 10+ years, used primarily to test web applications across different browsers and platforms.
Selenium is a suite of tools that consists of three components: Selenium WebDriver (the part that directly communicates with the browsers). Selenium IDE (Integrated Development Environment), and Selenium Grid.
If we're being technically correct, in the context of scraping with Selenium we'll be comparing not Selenium as a whole but rather the Selenium Webdriver specifically. Also, for web scraping, Selenium is used mostly in conjunction with Python.
Why is Selenium used for web scraping?
Selenium lets you programmatically interact with UI elements; it supports various browser engines, OSs, and most used languages. This means it can basically imitate user actions in any browser (which is important for testing), which is why Selenium has also become a natural first-choice tool for browser automation and extracting data from the web. In addition to the language freedom it gives in terms of script writing, because it's been around since 2004, it also has amassed a large active community and detailed docs.
Most importantly, Selenium can interact with web pages on the browser side. This means that Selenium can run JavaScript and deal with dynamically loaded websites, which sets it apart from other web scraping libraries powered by HTML parsing.
🎭 What is Playwright?
Playwright is an open-source Node.js library for automated browser testing that is also extremely popular for web scraping. It is relatively new (2020), cross-platform, cross-language, and provides full browser support. Together with Puppeteer, Playwright is a direct competitor to Selenium.

Playwright vs. Puppeteer: which is better? | Apify Blog
Two powerful Node.js libraries: described and compared.
 blog.apify.com
blog.apify.com
Why is Playwright used for web scraping?
Playwright is easy to set up, requires no additional configuration, and supports multiple browsers, including Chromium, Firefox, and Webkit. Additionally, it can be used in the most popular programming languages including TypeScript and JavaScript, Python, and Java. Playwright is fast and evolves dynamically, has plenty of unique features useful specifically for web automation (headless mode, autowaits, browser contexts, persisting in authentication state, custom selector engines, etc.), and wide community support.
🔥 Playwright vs. Selenium: a quick rundown of the differences
For a long time, Selenium was the default option for web automation, but now there are alternatives available. Playwright and Selenium started pretty much at the same level. But because Playwright has been developing more dynamically, it was gradually able to surpass Selenium in popularity. Here's a short comparison before we dive into the main differences:
| ♻️ Selenium | 🎭 Playwright | |
|---|---|---|
| Launch date | 2004 | 2020 |
| Maintained by | Selenium | Microsoft |
| GitHub stars | 25K as of 2023 🔗 | 47K as of 2023 🔗 |
| Accessibility | Open-source | |
| Browser engines | Chromium (Chrome, Edge, Opera), Firefox, Gecko (Mozilla), WebKit (Safari) | |
| Internet Explorer | ||
| Language bindings | JavaScript, Java, Python, C# | |
| Ruby, PHP, Perl | TypeScript, .NET | |
| OS compatibility | Windows, Mac OS, Linux | |
| Setup | Drivers needed to interface with the chosen browser | Install npm package via API npm init playwright@latest |
| Web interactions | Anything a user can do: open page, find element, click, hover, put or delete text, etc. | |
| Execution speed | 20% slower 🔗 | 20% faster 🔗 |
| Generating automation code | SeleniumIDE 🔗 | CodeGen 🔗 |
| Opening a web browser | Restarting every time for every test in the suite | Starting only once, at the beginning of the test suite. Persistent browser contexts |
| Interaction with DOM elements | WebElements 🔗 | Locators 🔗, use of ElementHandle is discouraged; Shadow DOM piercing available |
| Waits | Convoluted story, risk of race condition | Works very well, autowaiting with possibility of customization |
| Screenshots | Yes, code is a bit bulkier | Yes, multiple kinds (fullscreen, single element, in a buffer). |
| Video recording | No | Yes |
| iFrame | Yes, treated as a separate window, need extra lines of code to move in and out. | Yes, treated as any other DOM element |
Syntax differences for basic interactions on the web
| Selenium (Docs 🔗) | Playwright (Docs 🔗) | |
|---|---|---|
| Locate an element | By class name, for instance:await driver.findElement(By.name('q'))
|
By label, for instance:await page.locator('#tsf > div:nth-child(2) > input')
|
| Open page | await driver.get('https://selenium.dev'); |
await page.goto(url); |
| Hover | driver.actions().mouseMove(elem).perform(); |
locator.hover() |
| Click | element.click() |
locator.click() |
| Select option | select.selectbyIndex(1) |
await page.getByLabel('Choose a color').selectOption({ label: 'Blue' }); |
| Type text in text box | element.sendKeys("hello!") |
await page.getByLabel('Local time').fill('2020-03-02T05:15'); |
| Reading the data from page |
element.getText() element.isEnabled() element.isDisplayed()
|
element.innerText()element.isEnabled()element.isVisible()
|
| Drag and drop | const draggable = driver.findElement(By.id("draggable")); const droppable = await driver.findElement(By.id("droppable")); const actions = driver.actions({async: true}); await actions.dragAndDrop(draggable, droppable).perform(); |
await page.locator('#item-to-be-dragged').dragTo(page.locator('#item-to-drop-at')); |
| Initiate browser driver | const driver = await new Builder().forBrowser('chrome').build(); |
const browser = await playwright.chromium.launch(); |
Differences in features
👩💻 Language differences
Although both Playwright and Selenium support Python, Python developers tend to prefer Selenium over Playwright. There's no obvious reason for this; Playwright's support for Python is continuous, consistent, and no worse than Selenium's updates. Perhaps the fact that Selenium has been around for longer plays its role, since over this time the Selenium community has amassed a legacy of documentation, questions, and answers which might be very helpful for beginner Python devs.

Comparison for search volumes of Python+Selenium vs. Python+Playwright
Selenium also wins over other web scraping Python libraries when it comes to dynamic loading. Scrapy or Requests might be easier to get started with for web scraping, but they have a limitation: they cannot run client-side JavaScript. These libraries cannot handle the websites that are loaded dynamically - which is a lot of websites these days. Selenium can run JavaScript and interact with the website on its terms. Not without caveats, however.
Playwright , on the other hand, tends to be more on the JavaScript and Node.js side of things. In fact, Playwright is so tightly associated with Node.js that it was the most obvious choice for us when we were working on our own Node.js-based scraping library, Crawlee. Besides, Playwright's team tends to introduce many of its new features first for JavaScript and TypeScript, and then for the rest of the languages - which demonstrates its priorities.
📺 Browser initialization and browser contexts
✂️ TL;DR: Playwright is faster than Selenium because of browser contexts.
Selenium is built to start a new browser process for each test or action , which can take some time if you have several of them (a suite). When building their framework, Playwright devs were well aware of this limitation, so they developed browser initialization with a different logic in mind: browser contexts.
Playwright starts a browser process once and then creates a new context for each test, which is a defining factor that makes it a generally faster tool to use. These browser contexts are basically browsing sessions, similar to a browser tab or window, existing independently of each other. Each context has its own set of cookies, browser storage, and browsing history. This allows for multiple pages to be opened and interacted with simultaneously, each with their own separate state - autonomy that is hard to get with Selenium.
In Playwright, contexts persist , so you can easily create new contexts, switch between them, and close them - without any loss in speed. This makes it easy to open multiple tabs or switch between different pages - sounds about right for creating and testing web automation flows.
🖱 Interacting with elements on the page
✂️ TL;DR: Selenium has a complex story for waits, Playwright has autowaiting.
While Selenium can interact with dynamically loaded websites, it has a complex relationship with virtual DOM , hence, selecting elements on the page. Selenium's logic of interacting with an element starts with having to find this element by a locator (Name, ID, CSS Selector, LinkPath, and XPath). This assumes that the element will be already loaded on the page, which can't be guaranteed to happen every time. This logic creates a risk for race condition - a reaction mismatch between the browser and WebDriver script (user's actions).
Example: you instruct the browser to open a page and click on a button. Your script seems to be running well, but then when it comes to the button action, it throws a "no such element" error, although the button element is clearly there. The issue is, your script starts acting on it before the button actually shows up. These race conditionsthat occur between the browser and the user's instructions cause flakiness; one time, the script runs successfully, and another time it fails. Now imagine you need to perform multiple clicks... Nightmare!
Race conditions can even happen for external reasons: if you have a day when your internet connection is unstable, the page loads slower than your script starts reacting to it. Although Selenium has no shortcut for fixing that mismatch, there are a few ways to get around it and set up the condition to retry until the element is found. But they aren't pretty. Since implicit waits are discouraged by Selenium (they "cause unintended consequences, namely waits sleeping"), you usually end up with a mix of explicit or fluent waits and a condition - which adds complexity to your script.
Example of Selenium script for waiting and clicking on an element:
const documentInitialised = () =>
driver.executeScript('return initialised');
await driver.get('file:///race_condition.html');
await driver.wait(() => documentInitialised(), 10000);
const element = driver.findElement(By.css('p'));
await element.click();
Playwright , on the other hand, offers a different logic for interacting with elements. Its Locators might be a bit trickier to learn than Selenium's WebElements, but they are created in a way to prioritize what the user sees on the page, which makes Playwright very suitable for web automation.
Example of Playwright script for waiting and clicking on element:
await page.getByRole('p').click();
Besides, to max out their reliability card, Playwright team developed a set of actionability checks - preconditions that are checked before interacting with a DOM element. For instance, for page.click(), Playwright will ensure that the element you're trying to click on is attached to the DOM, visible, stable, receives events, and enabled. It will automatically wait until all these conditions are fulfilled and only then will act on the element.
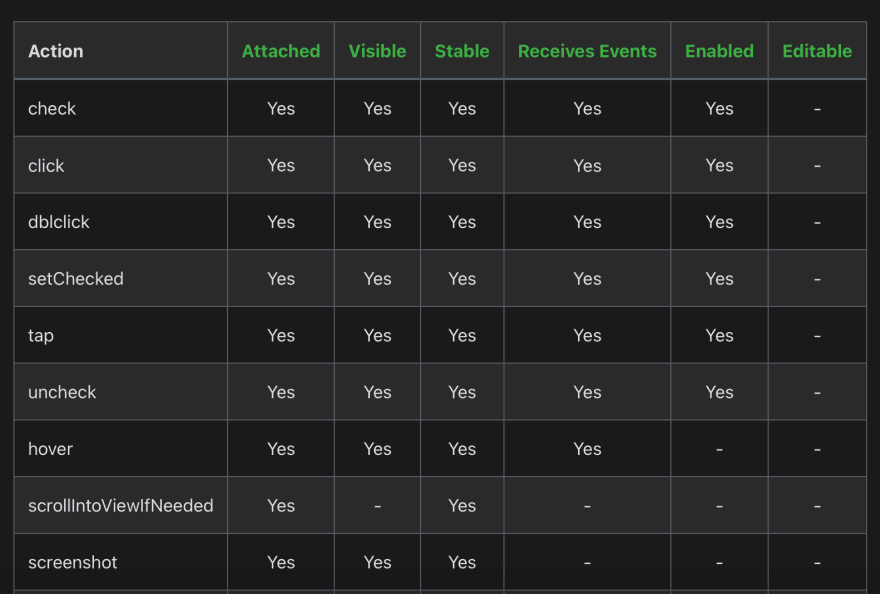
Playwright's actionability checks for a few actions in browser: https://playwright.dev/docs/actionability
In this way, Playwright's logic sets you up to automate repetitive code and diminishes the risk of flakiness. If the required checks do not pass within the given timeout frame, action will throw you a TimeoutError. It is important to note that Playwright's automated waits are not set in stone, and you can customize them as it fits your case: for instance, by disabling non-essential actionability checks.
🏃 How to migrate your Selenium code to Apify
Be it for legacy reasons or personal preference, at some point you might need to migrate your Selenium code. If you ever decide to make the Apify platform the new home for your Selenium scrapers, don't forget to use Selenium code runner 🔗 to make the process smooth and fast.

Here are the three main steps you need to make to migrate your Selenium code to Apify (in headless Chrome):
1) Import required packages
const Apify = require('apify');
const { Capabilities, Builder, logging } = require('selenium-webdriver');
const chrome = require('selenium-webdriver/chrome');
const proxy = require('selenium-webdriver/proxy');
const { anonymizeProxy } = require('proxy-chain');
2) Define a function to launch the Chrome WebDriver
const launchChromeWebdriver = async (options) => {
let anonymizedProxyUrl = null;
// logging.installConsoleHandler();
// logging.getLogger('webdriver.http').setLevel(logging.Level.ALL);
// See https://github.com/SeleniumHQ/selenium/wiki/DesiredCapabilities for reference.
const capabilities = new Capabilities();
capabilities.set('browserName', 'chrome');
// Chrome-specific options
// By default, Selenium already defines a long list of command-line options
// to enable browser automation, here we add a few other ones
// (inspired by Lighthouse, see lighthouse/lighthouse-cli/chrome-launcher)
const chromeOptions = new chrome.Options();
chromeOptions.addArguments('--disable-translate');
chromeOptions.addArguments('--safebrowsing-disable-auto-update');
if (options.headless) {
chromeOptions.addArguments('--headless', '--no-sandbox');
}
if (options.userAgent) {
chromeOptions.addArguments(`--user-agent=${options.userAgent}`);
}
if (options.extraChromeArguments) {
chromeOptions.addArguments(options.extraChromeArguments);
}
const builder = new Builder();
if (options.proxyUrl) {
const anonymizedProxyUrl = await anonymizeProxy(options.proxyUrl)
chromeOptions.addArguments(`--proxy-server=${anonymizedProxyUrl}`);
}
const webDriver = builder
.setChromeOptions(chromeOptions)
.withCapabilities(capabilities)
.build();
return webDriver;
};
3) Get input and prepare proxy URL and user agent
Apify.main(async () => {
const input = await Apify.getInput();
console.log('Input:');
console.dir(input);
// Prepare proxy URL
let proxyUrl = '';
if (input.proxy) {
const { useApifyProxy, apifyProxyGroups, proxyUrls } = input.proxy;
if (useApifyProxy) {
proxyUrl = Apify.getApifyProxyUrl({ groups: apifyProxyGroups });
} else if ((proxyUrls || []).length) {
proxyUrl = proxyUrls[Math.floor(Math.random * proxyUrls.length)];
}
}
// Prepare user agent
let userAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36';
if (input.userAgent) userAgent = input.userAgent;
const options = {
proxyUrl,
userAgent,
headless: true,
};
And that's it! Give it a try and let us know how it went!

Example Selenium · Apify
Example of loading a web page in headless Chrome using Selenium Webdriver.
 apify.com
apify.com





Top comments (0)