Introduction and requirements
The internet is an endless source of information, and for many data-driven tasks, accessing this information is critical. For this reason, web scraping, the practice of extracting data from websites, has become an increasingly important tool for machine learning developers, data analysts, researchers, and businesses alike.
One of the most popular web scraping tools is Beautiful Soup, a Python library that allows you to parse HTML and XML documents. Beautiful Soup makes it easy to extract specific pieces of information from web pages, and it can handle many of the quirks and inconsistencies that come with web scraping.
Another crucial tool for web scraping is Requests, a Python library for making HTTP requests. Python Requests allow you to send HTTP requests extremely easily and comes with a range of helpful features, including handling cookies and authentication.
In this article, we will explore the basics of web scraping with Beautiful Soup and Requests, covering everything from sending HTTP requests to parsing the resulting HTML and extracting useful data. We will also go over how to handle website pagination to extract data from multiple pages. Finally, we will explore a few tricks we can use to scrape the web ethically while avoiding getting our scrapers blocked by modern anti-bot protections.
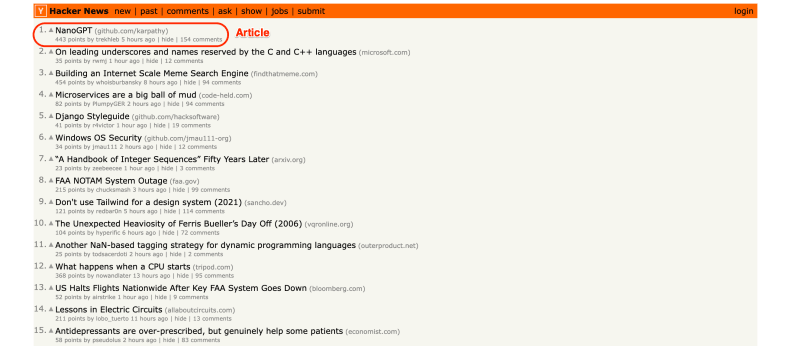
To demonstrate all of that, we will build a Hacker News scraper using the Requests and Beautiful Soup Python libraries to extract the rank , URL , and title from all articles posted on HN. So, without further ado, let's start coding!
Initial setup
First, let's create a new directory hacker-news-scraper to house our scraper, then move into it and create a new file named main.py. We can either do it manually or straight from the terminal by using the following commands:
mkdir hacker-news-scraper
cd hacker-news-scraper
touch main.py
Still in the terminal, let's use pip to install Requests and Beautiful Soup. Finally, we can open our project in our code editor of choice. Since I'm using VS Code, I will use command code . to open the current directory in VS Code.
pip install requests beautifulsoup4
code .
How to make an HTTP GET request with Requests
In the main.py file, we will use Requests to make a GET request to our target website and save the obtained HTML code of the page to a variable named html and log it to the console.
Code
import requests
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
print(html)
Output
And here is the result we expect to see after running our script:

Great! Now that we are properly targeting the page's HTML code, it's time to use Beautiful Soup to parse the code and extract the specific data we want.
Parsing the data with Beautiful Soup
Next, let's use Beautiful Soup to parse the HTML data and scrape the contents from all the articles on the first page of Hacker News.
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html)
Before we select an element, let's use the developer tools to inspect the page and find what selectors we need to use to target the data we want to extract.

When analyzing the website's structure, we can find each article's rank and title by selecting the element containing the class athing.
Traversing the DOM with the BeautifulSoup find method
Next, let's use Beautiful Soup find_all method to select all elements containing the athing class and save them to a variable named articles.
import requests
import json
from bs4 import BeautifulSoup
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html)
articles = soup.find_all(class_="athing")
Next, to verify we have successfully selected the correct elements, let's loop through each article and print its text contents to the console.
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html)
articles = soup.find_all(class_="athing")
# Loop through the selected elements
for article in articles:
# Log each article's text content to the console
print(article.text)
Great! We've managed to access each element's rank and title.
In the next step, we will use BeautifulSoup's find method to grab the specific values we want to extract and organize the obtained data in a Python dictionary.
The find method is used to get the descendants of an element in the current set of matched elements filtered by a selector.
In the context of our scraper, we can use find to select specific descendants of each article element.
Returning to the Hacker News website, we can find the selectors we need to extract our target data.
Here's what our code looks like using the find method to get each article's URL, title, and rank :
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html)
articles = soup.find_all(class_="athing")
output = []
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
output.append(data)
print(output)
Finally, to make the data more presentable, lets use the json library to save our output to a JSON file. Here is what our code looks like:
import requests
from bs4 import BeautifulSoup
import json
response = requests.get("<https://news.ycombinator.com/>")
html = response.text
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html)
articles = soup.find_all(class_="athing")
output = []
# Extract data from each article on the page
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
output.append(data)
# Save scraped data
print('Saving output data to JSON file.')
save_output = open("hn_data.json", "w")
json.dump(output, save_output, indent = 6, ensure_ascii=False)
save_output.close()
Great! We've just scraped information from all the articles displayed on the first page of Hacker News using Requests and Beautiful Soup. However, it would be even better if we could get the data from all articles on Hacker News, right?
Now that we know how to get the data from one page, we just have to apply this same logic to all the remaining pages of the website. So, in the next section, we will handle the websites pagination.
Handling Pagination
The concept of handling pagination in web scraping is quite straightforward. In short, we need to make our scraper repeat its scraping logic for each page visited until no more pages are left. To do that, we have to find a way to identify when the scraper reaches the last page and then stop scraping, and save our extracted data.
So, lets start by initializing three variables: scraping_hn, page, and output.
scraping_hn = True
page = 1
output = []
scraping_hnis a Boolean variable that keeps track of whether the script has reached the last page of the website.pageis an integer variable that keeps track of the current page number being scraped.outputis an empty list that will be populated with the scraped data.
Next, lets create a while loop that continues scraping until the scraper reaches the last page. Within the loop, we will send a GET request to the current page of Hacker News, so we can execute the rest of our script to extract the URL, title, and rank of each article and store the data in a dictionary with keys "URL" , "title" , and "rank". We will then append the dictionary to the output list.
scraping_hn = True
page = 1
output = []
print('Starting Hacker News Scraper...')
# Continue scraping until the scraper reaches the last page
while scraping_hn:
response = requests.get(f"<https://news.ycombinator.com/?p={page}>")
html = response.text
print(f"Scraping {response.url}")
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html, features="html.parser")
articles = soup.find_all(class_="athing")
# Extract data from each article on the page
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
output.append(data)
After extracting data from all articles on the page, we will write an if statement to check whether there is a More button with the class morelink on the page. We will check for this particular element because the More button is present on all pages, except the last one.
So, if the morelink class is present, the script increments the page variable and continues scraping the next page. If there is no morelink class, the script sets scraping_hn to False and exits the loop.
# Check if the scraper reached the last page
next_page = soup.find(class_="morelink")
if next_page != None:
page += 1
else:
scraping_hn = False
print(f'Finished scraping! Scraped a total of {len(output)} items.')
Putting it all together, here is the code we have so far:
import requests
import json
from bs4 import BeautifulSoup
scraping_hn = True
page = 1
output = []
print('Starting Hacker News Scraper...')
# Continue scraping until the scraper reaches the last page
while scraping_hn:
response = requests.get(f"<https://news.ycombinator.com/?p={page}>")
html = response.text
print(f"Scraping {response.url}")
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html, features="html.parser")
articles = soup.find_all(class_="athing")
# Extract data from each article on the page
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
output.append(data)
# Check if the scraper reached the last page
next_page = soup.find(class_="morelink")
if next_page != None:
page += 1
else:
scraping_hn = False
print(f'Finished scraping! Scraped a total of {len(output)} items.')
# Save scraped data
print('Saving output data to JSON file.')
save_output = open("hn_data.json", "w")
json.dump(output, save_output, indent = 6, ensure_ascii=False)
save_output.close()
In conclusion, our script successfully accomplished its goal of extracting data from all articles on Hacker News by using Requests and BeautifulSoup.
However, it is important to note that not all websites will be as simple to scrape as Hacker News. Most modern webpages have a variety of anti-bot protections in place to prevent malicious bots from overloading their servers with requests.
In our situation, we are simply automating a data collection process without any malicious intent against the target website. So, in the next section, we will talk about what measures we can use to reduce the likelihood of our scrapers getting blocked.
Avoid being blocked with Requests
Hacker News is a simple website without any aggressive anti-bot protections in place, so we were able to scrape it without running into any major blocking issues.
Complex websites might employ different techniques to detect and block bots, such as analyzing the data encoded in HTTP requests received by the server, fingerprinting, CAPTCHAS, and more.
Avoiding all types of blocking can be a very challenging task, and its difficulty varies according to your target website and the scale of your scraping activities.
Nevertheless, there are some simple techniques, like passing the correct User-Agent header that can already help our scrapers pass basic website verifications.
What is the User-Agent header?
The User-Agent header informs the server about the operating system, vendor, and version of the requesting client. This is relevant because any inconsistencies in the information the website receives may alert it about suspicious bot-like activity, leading to our scrapers getting blocked.
One of the ways we can avoid this is by passing custom headers to the HTTP request we made earlier using Requests, thus ensuring that the User-Agent used matches the one from the machine sending the request.
You can check your own User-Agent by accessing the http://whatsmyuseragent.org/ website. For example, this is my computer's User-Agent:

With this information, we can now pass the User-Agent header to our Requests HTTP request.
How to use the User-Agent header in Requests
In order to verify that Requests is indeed sending the specified headers, let's create a new file named headers-test.py and send a request to the website https://httpbin.org/.
To send custom headers using Requests, we will pass a params parameter to the request method:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
}
response = requests.get("<https://httpbin.org/headers>", headers=headers);
print(response.text);
After running the python3 headers-test.py command, we can expect to see our request headers printed to the console:

As we can verify by checking the User-Agent, Requests used the custom headers we passed as a parameter to the request.
In contrast, that's how the User-Agent for the same request would look like if we didn't pass any custom parameters:

Cool, now that we know how to properly pass custom headers to a Requests HTTP request, we can implement the same logic in our Hacker News scraper.

Web scraping: how to crawl without getting blocked | Apify Blog
Guide on how to solve or avoid anti-scraping protections.
 blog.apify.com
blog.apify.com
Required headers, cookies, and tokens
Setting the proper User-Agent header will help you avoid blocking, but it is not enough to overcome more sophisticated anti-bot systems present in modern websites.
There are many other types of information, such as additional headers, cookies, and access tokens, that we might be required to send with our request in order to get to the data we want. If you want to know more about the topic, check out the Dealing with headers, cookies, and tokens section of the Apify Web Scraping Academy.
Restricting the number of requests sent to the server
Another common strategy employed by anti-scraping protections is to monitor the frequency of requests sent to the server. If too many requests are sent in a short period of time, the server may flag the IP address of the scraper and block further requests from that address.
An easy way to work around this limitation is to introduce a time delay between requests, giving the server enough time to process the previous request and respond before the next request is sent.
To do that, we can use the time.sleep() method before each HTTP request to slow down the frequency of requests to the server. This approach can help to reduce the chances of being blocked by anti-scraping protections and allow our script to scrape the website's data more reliably and efficiently.
time.sleep(0.5) # Wait before each request to avoid overloading the server
response = requests.get(f"<https://news.ycombinator.com/?p={page}>")
Final code
import requests
import json
from bs4 import BeautifulSoup
import time
scraping_hn = True
page = 1
output = []
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
}
print('Starting Hacker News Scraper...')
# Continue scraping until the scraper reaches the last page
while scraping_hn:
time.sleep(0.5) # Wait before each request to avoid overloading the server
response = requests.get(f"https://news.ycombinator.com/?p={page}", headers=headers)
html = response.text
print(f"Scraping {response.url}")
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html, features="html.parser")
articles = soup.find_all(class_="athing")
# Extract data from each article on the page
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
output.append(data)
# Check if the scraper reached the last page
next_page = soup.find(class_="morelink")
if next_page != None:
page += 1
else:
scraping_hn = False
print(f'Finished scraping! Scraped a total of {len(output)} items.')
# Save scraped data
print('Saving output data to JSON file.')
save_output = open("hn_data.json", "w")
json.dump(output, save_output, indent = 6, ensure_ascii=False)
save_output.close()





Top comments (0)