
If you find yourself reading this post, there are very good chances that you find yourself in the shoes of a MySQL database administrator, a database-savvy developer, or even a sysadmin. If you’re reading this post, also chances are that you know a couple of things about storage engines, indexes, partitioning, normalization, search engines helping you secure your data, and whatnot.
In this blog, we will dive deeper into the correlation between big data and foreign keys on MySQL.
What is Big Data and What are Foreign Keys?
Before diving further into big data sets and its interaction with foreign keys, we would need to explain what big data is. Well, generally, everything in this space is very simple – big data refers to any data set that is so large that it is sometimes deemed unusable by a system.
Generally, big data refers to a lot of rows – for a data set to be considered in the “big data” range, it should have at least a hundred million rows, and the values should be preferably distinct as well.
Foreign keys, on the other hand, are columns that are used to link data between tables – in other words, foreign keys are used to link data existing in one table to another.
Your Data and Foreign Keys
You can create foreign keys in the following way (we are running queries with Arctype for this example):

In this example, we have used a different table ( demo_2 ) to create the foreign key on, but foreign keys can also refer to columns in the same table.
When working with foreign keys on MySQL, one should also note that MySQL offers a couple of reference options:
- The
NO ACTIONoption offered by MySQL means that if a row in one table is the same as the row in the other table, no action should be performed (i.e. data should not be updated nor deleted.) This option is a synonym to theRESTRICToption. - The
CASCADEoption offered by MySQL means that if a row in one table is updated or deleted, it will also be updated or deleted in another table too. - The
SET NULLoption offered by MySQL means that if a row in one table is updated or deleted, the column with the foreign key will have its values set toNULL.
As you can probably tell by now, the FOREIGN KEY option available in MySQL lets us ensure that links between tables are left intact whatever happens. Now let’s explore what happens when foreign keys are used together with big data.
Foreign Keys and Big Data
In order to understand how foreign keys might interact with big data, we must first define what data do we consider being “big.” In many cases, big data would be considered any kind of data that holds more than, say, 50 or 100 million rows of data. In certain obscure edge cases, some developers might consider “big data” to contain a billion rows or more (there are even search engines that deal with tens of billions of rows of data while also helping you secure yourself on the web.)
For MySQL, it’s safe to say that big data would start from 50 million rows and go up to 10 billion rows or even more.
For a foreign key use case, we are going to use two tables each consisting of about 70 million rows with an engine set to InnoDB. In order to begin our experiment, we would need two tables. Their architecture and structure can vary – it’s not vitally important (though you should keep in mind that we will only use one foreign key column for this purpose).
Here are the steps we take:
- We open up my.cnf (the main MySQL configuration file – find it in
/var/lib/mysql/. It has many configuration options that can be set up, but for this specific example, we are only interested in InnoDB-based parameters: find them below.) - We set our
innodb_buffer_pool_sizeto approximately 60 to 80% of available operating memory in our system. - We set our
innodb_log_file_sizeto 25% of the value set ininnodb_buffer_pool_size(if you wonder why we take steps #1 and #2, refer to our older blog post about InnoDB and big data – there we explain everything in more detail). - We create a dummy table and import our data using
LOAD DATA INFILEinstead of usingINSERT INTO(the general idea is thatLOAD DATA INFILEcomes with a lot less overhead thanINSERT INTOdoes:LOAD DATA INFILEis also designed for bulk data importing as it comes with numerous so-called “bells and whistles” including giving us the ability to ignore certain rows or columns, only load data into specific columns, etc.: refer to our blog post about it for more information.) - Once our data is imported into our table, we import our data into a second table.
We import data before adding any kind of indexes because one of the primary statements that are used to add indexes onto a table is ALTER TABLE, which makes a copy of the table on the disk, then loads data into it, and then adds indexes on top of everything we just mentioned. That means if our table is of 100GB in size, and we presume our index would consume 10GB, we would need at least 110GB of free space on the disk to be able to proceed with index creation. MySQL would need space for existing data, existing indexes, and an index we want to add.
Once we have our data, we need to run a query like so (in this case, demo_table is the name of our first table, demo_column defines the column we are going to put our foreign keys onto, and the table after the REFERENCES keyword allows our two tables to be linked together) – we would need to use ADD CONSTRAINT if we want to use foreign keys on multiple columns, but if we are using a foreign key on only one column, such a query will do:
ALTER TABLE demo_table ADD FOREIGN KEY(demo_column) REFERENCES demo_table2(demo_column);
Once we run such a query on our table, we would have a foreign key on one of our columns on a table with big data sets! Except, no, that’s a fantasy – instead, we would have an error like the following:
ERROR 1215 (HY000): Cannot add foreign key constraint
The first question is, of course, why? The answer, thankfully, is plain and simple – MySQL didn’t like such an approach because the table we are adding foreign key indexes onto did not have a primary key and we tried to add a foreign key on a column that does not have a primary key on top of it.
In order to solve this issue, we need to add a primary key on top of our table running big data. Our query would now look like so:

… Except for the fact that ALTER TABLE with big data does not work well (remember – we said that ALTER TABLE queries on bigger data sets make a copy on the disk: do you want MySQL to make a copy of your table with potentially hundreds of millions of rows?) What do we do? The answer is simple: we truncate both of our tables, then add a primary key index on top of them (we will call our column id), and add a foreign key on top of the column that has a primary key. In this case, remember that MySQL tables can only have one primary key and primary keys in MySQL tables are often columns with a data type of an integer.
Here’s a couple of caveats – in this case, do not run DELETE queries on any of your tables: TRUNCATE will generally complete much faster because DELETE scans every record before removing it – TRUNCATE does not.
Once you have TRUNCATEd both of your tables, add an id column by running an ALTER TABLE query like the one specified below (in this case, ALTER TABLE would be fast because there is no data inside of any of the tables):
ALTER TABLE demo_table ADD id INT(100) NOT NULL AUTO_INCREMENT PRIMARY KEY;
would do. Repeat the query on both of the tables, then proceed with LOAD DATA INFILE. As far as LOAD DATA INFILE is concerned, make sure to load data only inside of columns that are specified in your file skipping the id column. You can do it by specifying them at the end of the query like so:

You might also want to specify a FIELDS TERMINATED BY clause to tell MySQL, MariaDB, or Percona Server what character terminates your columns (see example above.) Once your LOAD DATA INFILE query is executing, you are free to see how many rows are inserted into your table by simply navigating to phpMyAdmin or any other database management tool of your choice, and observing. You can even see the rows that are inside of the table itself: no issues here as well. Wait a couple of minutes (or hours, depending on the configuration inside of your my.cnf file and how much rows your data set has: LOAD DATA INFILE has a tendency to slow down after importing some amount of data too...) and your import should be finished. Once MySQL finishes importing data, go ahead and run an ALTER TABLE query to add a foreign key: this might seem a little counterintuitive since we just told you that ALTER TABLE queries on big data are slow due to the copying of data, but what we haven’t mentioned is that adding indexes using ALTER TABLE is generally faster when we run the ALTER TABLE statements after importing data into a table and not vice versa.
Regardless of what data set you elect to use, the point is that you need to be more careful when dealing with foreign keys and bigger data sets because keys are indexes and all indexes tend to slow down our processes for a little while when they are being created due to the fact that our tables will be locked, and also they slow down any UPDATE, INSERT, and DELETE queries. Also keep in mind that foreign keys are related to at least two tables: if we are working with bigger data sets we must be 100% sure that we need to use foreign keys on our data sets because if we do not and our database isn‘t properly normalized, we‘re in line for trouble (see the section about importing bigger data sets for some problems we may encounter on the way.) Regardless, foreign keys have their purpose, but if we work with big data as well, we must know how to do that properly too.
Foreign Keys and Importing Big Data
Remember when we said that indexes make the performance of such queries slower while accelerating the performance of read-based queries in return? Foreign keys are not an exception here. To start figuring out how foreign keys interact with bigger data sets, we are going to need to know the structure of our tables looks like. For that, run a SHOW CREATE TABLE demo_table query where demo_table is the name of your table:
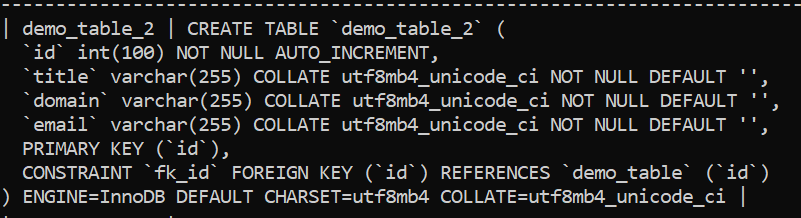
You will instantly see that our table has a FOREIGN KEY on an id column and that it has a collation of utf8mb4_unicode_ci (the precise reason why we avoid utf8 is because of the fact that onlyutf8mb4 offers full unicode support which can help avoid issues like data loss: utf8 does not.)
The understanding of these concepts is vital to achieving better performance: inserting data on a table without foreign keys on its columns will always, always be faster than on those with them because when data is updated, the index has to be updated as well. We will import 100,000 rows into our table and see how much time that will take. We will be using INSERT statements (they come with much more overhead than LOAD DATA INFILE does because INSERT INTO is not designed for big data importing while LOAD DATA INFILE is.)
We will import our data using a simple Import functionality available in phpMyAdmin:
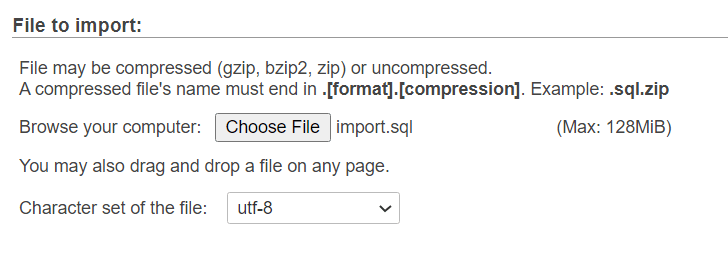
It is important to note that phpMyAdmin comes with a couple of additional functionalities that would be useful for imports of big data sets including foreign key checks and partial imports. If you know that your file only consists of INSERT statements and you want to skip a couple of them for example, it could be very useful. Disabling foreign key checks will make the import faster due to the fact that MySQL would not enforce referential integrity between tables:

If you leave the Enable foreign key checks checked however and a foreign key check fails (e.g. if you insert a row that already exists in a table), MySQL will come back with an error like so:
#1452 - Cannot add or update a child row: a foreign key constraint fails
With that being said, go ahead and import data. First thing that we should notice in this kind of scenario is that the process of importing it takes rather long so it would be smart to issue a SHOW PROCESSLIST; query to see what the processes in our database instance are doing. Locate your process (it will probably say “Opening tables” so you know it’s the one) and see how much time it takes. In our scenario, it is taking more than 15 minutes (divide seconds by 60.) We filtered out the query from the list (the format is ID:user:host:database:command:time:action:query):
![]()
Observe the status of your query. Want to hear some news? It will take more than 20 minutes for MySQL to import 10,000 rows into your table. Yeah, that is the power of foreign keys.
In this case, “Opening tables” means that MySQL will have to finish the current statement before opening a table, so it’s actually importing data. To understand why, glance at your SQL file once again: it should start with a statement like:
LOCK TABLES demo_table WRITE;
After that, your INSERT INTO statements should follow (if you have more than a couple thousand rows, they will be made in bulk meaning that your INSERT INTO statements will look like this for faster processing):
INSERT INTO demo_table (column) VALUES (‘Demo’), (‘Demo 2’);
And your file should finish with UNLOCK TABLES; meaning that MySQL will prevent opening tables until all statements are finished, and once your table also contains foreign keys, they will need to be updated together with the table, and that will take long regardless of how many rows you will have. Of course, there are a couple ways around this: to make your INSERT queries faster, you could use the power of starting a transaction by using START TRANSACTION; and then using COMMIT; at the end of your query, which would essentially make MySQL only make changes to the database permanent when all queries would have finished executing, and that would save time. You could also disable foreign key checks (discussed above) and that would make performance a little faster as well. But when we are dealing with bigger data sets and especially when our tables have foreign keys, none of those solutions would fit: instead, we would want to look into LOAD DATA INFILE (refer to the explanation above.)
You might want to kill your query now – at this point, it’s still opening tables (after 40 minutes have passed), so it’s useless. Get the ID of your query and let it die either through a CLI or through the Arctype client:
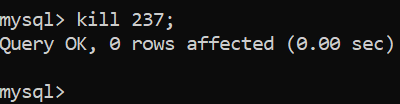
Now, let’s do a couple of experiments. Make a table exactly like one you have by issuing a CREATE TABLE demo_2 LIKE demo where demo is the original name of the table and demo_2 is your new table, make sure you have no indexes on it, remove all ALTER TABLE and LOCK TABLES; statements from the SQL file, make sure your new table is running InnoDB, then come back to phpMyAdmin, navigate to your database and import the file into your new table again. Your import should finish instantly. MySQL will take a minute and import the file successfully:

MySQL imports 10,000 rows in 0.1 second meaning that to import around 100,000 rows it should consume approximately a second, perhaps two. Compare that to importing data on foreign keys: the difference is apparent.
To see the difference with bigger data sets when LOAD DATA INFILE is in use, grab a file consisting of at least 50 million rows, and let MySQL load it in on a table without foreign keys at first (while your data is importing, you can also observe the entire process by going back into phpMyAdmin: no issues here.) Finally, observe the entire process in the CLI:

Want to know why? The table had no indexes which needed to be updated! Now, add a foreign index onto a column and load the same set of data using the same LOAD DATA INFILE query (truncate it first though – TRUNCATE TABLE is significantly faster than deleting rows by amounts of 100,000 or 1,000,000 at a time, so do that):

Now, add a UNIQUE INDEX and load the data in again using the same query ( IGNORE will ignore all errors):

You will notice that LOAD DATA INFILE slows down after a while, but finally, it finishes after a while:


The speed of LOAD DATA INFILE-like queries is also heavily dependant on the storage engine you find yourself using. We won’t go into all of the nitty-gritty details about MySQL storage engines in this blog post (we have covered how InnoDB might be a fit for big data a little earlier on), however, we do want to remind you that if you find yourself in the MyISAM shoes, your LOAD DATA INFILE queries will slowly degrade in performance if you are importing big data sets. Much of that has to do with the fact that when LOAD DATA INFILE is used with MyISAM, takes advantage of a parameter called bulk_insert_buffer_size to make bulk data inserts faster to tables that are not empty, so it would be smart to increase the size of this variable to be as big as you possibly can set it to according to the parameters of your operating system.
However, with importing out of the way, you are probably wondering how foreign keys interact with big data deletion procedures as well. Let us show you.
Foreign Keys and Deleting Big Data
For this use case, we are going to use the same set of big data – one table with foreign keys set up, one without. Since deleting rows one-by-one isn’t very practical in a real-world scenario, we are going to go with the scenario that would seem the most likely: deleting rows with a LIMIT clause. Issue a query like so on a table with foreign keys and the one without (here demo_table is the name of your table):
DELETE FROM demo_table WHERE email = ‘demo’ ORDER BY id ASC LIMIT 5000;
The LIMIT clause is used to target specific records that we want to delete: in this case, we are targeting ascending rows up until the limit of 5,000. In other words, we order rows by their IDs and deleting the first 5,000 rows in our results. Keep in mind that we must have the ORDER BY and WHERE clause for this query to work. First, the table with foreign keys through a CLI:

Now almost the same query through the Arctype SQL client – notice that time is shown in milliseconds below the query instead:

Now the one without – can you predict the results? Probably. It is indeed faster, even when sometimes the difference might not be very noticeable, but it is there. First, the CLI:

Now the Arctype client:

Now let’s delete more rows – say, 50 million in a descending order. The first result is a table with a foreign key, the second one is from the one without:

Let’s try different queries – again, the first result is a table with a foreign key, the second one is from the one without:

The same queries (the first result is a table with a foreign key, the second one is from the one without) through the Arctype client:

Now, let’s delete rows from a table without a foreign key:

Again, the difference is there. Speed is not the only enemy of foreign keys though:
- The data type of a foreign key might not match the data type of a primary key which means that we would lose referential integrity (referential integrity is a property basically stating that all of the data attributes are valid.)
- Foreign keys at scale might not be that bright of an idea after all – the whole idea of foreign keys in relational database management systems such as MySQL is to provide “referential integrity” (refer to an explanation above) between a parent and a child table.
- Foreign keys are usually columns that link to other columns and the more data we have the more complex our operations might become. For example, if we specify that we want to use the
CASCADEoption, then we will face a scenario that if a row in one table would be updated or deleted, the same row in another table would too. This might prove to be devastating if we update the wrong row, if we mistakenly delete data, or in other similar cases.
Foreign keys are not always a nightmare though: especially not when we have a little less data.
Foreign Keys and Smaller Data Sets
Everything gets easier when you have less data to query through – it’s easier to optimize your queries, you probably don’t need to use normalization, you probably don’t need indexes, and, of course, it’s easier to work with foreign keys too. To see how foreign keys might interact with smaller data, once again create two tables with a column that has a PRIMARY KEY, then put a foreign key on top of it ( PRIMARY KEY columns would also increment automatically meaning that you must specify an AUTO_INCREMENT clause here as well):

In this case, keep in mind that our queries look a little different as well: we implemented a constraint that says whenever data is updated or deleted in one table, it should be updated or deleted in another table too. Here it would probably be a smart idea to ensure that both of your tables run InnoDB (and not MyISAM as it might be specified in your my.cnf or, if you run Windows, my.ini files): simply specify your engine as InnoDB as in the example above, and if you forgot to do so, keep in mind that ALTER TABLE demo_table ENGINE = InnoDB; would do. Repeat this step for both of the tables. Also keep in mind that we can specify an option like ON UPDATE or ON DELETE (see example above), but by default the option is set to RESTRICT.
Big Data, Data Breaches, Foreign Keys and The Future
As far as big data and foreign keys are concerned, there are a couple of things you should be aware of as well: one of them is that by default, when InnoDB (one of MySQL’s storage engines) is in use, foreign keys cannot be used together with partitions.
Also keep in mind that indexes, and especially foreign keys, are not supported by some storage engines in MySQL. For example, MyISAM does not support those, so if we would find ourselves in a scenario where we would need to run COUNT(*) queries inside of our database instance (remember – MyISAM stores the row count inside of its metadata, while InnoDB does not) and need foreign keys together with it, we could be in trouble.
One more vital point of concern is that foreign keys would surely slow down both INSERTs and LOAD DATA INFILE operations since the index would have to be updated together with the data. The more data you have, the more apparent the problem will become.
Summary
To summarize, foreign keys on bigger data sets together with MySQL or MariaDB are almost never a great idea. First off because of the fact that big data itself needs to be maintained in a proper way, we would need to take care of the structure of our database, and also index things properly. Secondly, foreign keys slow down almost all maintenance operations – queries involving foreign keys will be slow in almost any kind of scenario, and also keep in mind that some of MySQL’s storage engines do not support foreign keys when partitioning is in use (and if we deal with big data sets, there’s a very big chance that we would need to partition them in one way or another.) The use of foreign keys might be viable, but only if we evaluate our project needs carefully and only if we are dealing with a relatively small amount of rows.
No matter what data you are working with, though, by using the SQL client provided by Arctype you will be able to observe the structure of your tables, construct high-performing queries and also share them with your team, and even create charts. PlanetScale on the other hand will be helpful if you need to spin up a serverless database platform in a matter of seconds.
If you find yourself in the big data space and also care about information security, data breach search engines can help secure your organization through an API offering or simply letting you search through tens of billions of leaked data acquired from hundreds of data breaches.
We hope you stick around for more content, visit the Arctype blog and try out its SQL client, visit the blog of PlanetScale and find out a thing or two about non-blocking schema changes and similar content, and finally, run a scan through data breach search engines or implement their API into your own infrastructure to make sure your data is always safe and that you sleep soundly. See you in the next blog!





Top comments (0)