
If you are already familiar with other SQL databases but new to PostgreSQL, then this article is perfect for you. It will help you understand the nuances and get started with PostgreSQL.
Note: Most comparisons in this article are targeted towards MySQL since it is the closest open source database that PostgreSQL can be compared against.
No Default Ordering On Primary Key
If you have previously worked with MySQL, then you should be familiar with the fact that the primary key of any table is a clustered key by default. The data is physically ordered on the disk using the index and this is why when querying a primary key in MySQL, the data is sorted without having an order by in the query.
MySQL
Let's test our theory with some experiments by running the query below:
-- Create table E1
CREATE TABLE E1 (
empId INTEGER,
name TEXT NOT NULL,
dept TEXT NOT NULL
);
-- Insert sample values
INSERT INTO E1 VALUES (0001, 'John', 'Sales');
INSERT INTO E1 VALUES (0003, 'Ava', 'Sales');
INSERT INTO E1 VALUES (0002, 'Dave', 'Accounting');
-- Select without Order By
SELECT * FROM E1;

Now, let's create a primary key:
-- Add Primary key. This is clustered by default
ALTER TABLE E1 ADD PRIMARY KEY (empID);

As you can see, we didn't include an order by clause in our query, but MySQL still returns rows in the same order.
PostgreSQL
Let's run the same set of queries in PostgreSQL, only on a table with a Primary Key:
-- Similar code to MySQL. Create table and insert sample values.
-- Primary key is added in the Create itself.
CREATE TABLE E1 (
empId INTEGER PRIMARY KEY,
name TEXT NOT NULL,
dept TEXT NOT NULL
);
INSERT INTO E1 VALUES (0001, 'John', 'Sales');
INSERT INTO E1 VALUES (0003, 'Ava', 'Sales');
INSERT INTO E1 VALUES (0002, 'Dave', 'Accounting');
If we run a query like SELECT * (see below), PostgreSQL will not sort data by empId - we must include an ORDER BY clause instead.
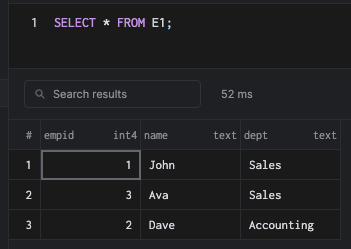

Clustered keys have their own advantages and disadvantages, but there is no default clustered key in PostgreSQL. PostgreSQL gives you the choice to do clustering if required, though.
ACID Compliance Differences
PostgreSQL has default ACID compliance settings which are very different and stricter in nature. Some of them are as follows:
Dirty Read
PostgreSQL has stricter ACID compliance by default. For example, MySQL has an isolation level (Read Uncommitted) which allows dirty reads to happen whereas in PostgreSQL there is no version/level where dirty reading is allowed.
Serializable
To accomplish the serializable isolation level (strongest level), PostgreSQL uses something called memory-based MVCC. This is much faster and generally does not require explicit locks to achieve a serializable level. In comparison, MySQL achieves it with fine-grained locks. In most cases, there is no performance difference, but it has been argued that memory-based MVCC is slightly better and prevents bloat in the main table.
Connections are costly
PostgreSQL follows process-based concurrency and hence opening and closing of connections is not encouraged. This is also the case with many other database systems, but more so in PostgreSQL. Hence, it is recommended to use a connection pool that maintains connections for a longer period, and applications can then open and close connections via this connection pool. We have written about PostgreSQL connection pooling previously, so those who are interested can find the article here:

Postgres Connection Pooling and Proxies
Connection pooling, implementing it in Postgres, and how proxies fit in.
 arctype.com
arctype.com
PostgreSQL Is Not a Single Model Database
Users of PostgreSQL should also note that PostgreSQL is not a single model database. It seamlessly integrates other database patterns/types into the relational model of operation. A lot has been written on this so I will just link the articles here.
JSON

Forget SQL vs NoSQL - Get the Best of Both Worlds with JSON in PostgreSQL
Create a database schema for any situation with the power of JSON.
arctype.com
GIS

Working with geospatial data in Postgres.
PostgreSQL has several extensions so spatial and geometry data can be treated as first-class objects within your PostgreSQL database.
arctype.com
Fuzzy Search

A Handbook to Implement Fuzzy Search in PostgreSQL
Learn about PostgreSQL fuzzy search methods like trigrams, Levenshtein matching, phonetic matching, and more.
arctype.com
Full-Text Search

Probing Text Data Using PostgreSQL Full-Text Search
Learn how to leverage the power of full-text search in PostgreSQL to search through large text content in a fast and accurate way.
arctype.com
Key-Value Store

Fast Key-Value Store With PostgreSQL
Explore Key-Value store features which augments the already fantastic NoSQL tool set that PostgreSQL offers.
arctype.com
These data types also have their own unique index types for faster access. Unlike MySQL which has different engines, PostgreSQL works using the same engine and only the datatypes and index types differ.
Database vs Schema
In PostgreSQL, a database is completely separated from other databases. It is a good practice to keep only one database in a PostgreSQL cluster. If there is a need to logically group tables then that is where the schema comes in.
- A PostgreSQL database is rigidly separate from other databases. A database connection is always opened to one database in the cluster. That connection cannot be reused to connect other databases even within the same cluster.
- Cluster resources are equally shared between different databases in the same cluster.
- Schemas can be reused between different database connections and represent a logical collection of tables.
- Data backup and restoration generally work at the database level with all the schemas self-contained.
These points are important to understand especially for someone coming from a database like MySQL where these terminologies are reversed.
Dialect Differences
Each database out there has its own SQL dialect for many reasons. PostgreSQL has its own dialect which is very close to the ANSI SQL standard. The SQL glossary is listed in the documentation -

PostgreSQL: Documentation: 14: Part II. The SQL Language
To understand what a dialect means and why it matters, we recommend reading the article linked below:
Understanding SQL Dialects
There are numerous SQL dialects instead of one fully implemented SQL standard. In this post we learn about the major ones. Plus lists of all of them.
arctype.com
Open Source & Community Owned
Open source and community-owned are two very different things. Open source depicts the license of the software such as
- Apache.
- BSD.
- MIT.
- GPL.
etc.,
and community-owned means the direction of the evolution and development and enhancement is decided by a volunteer community. A community-owned open source software is much better than an organization-owned open-source software since no company dictates the future of the project. PostgreSQL has a license that is similar to BSD or MIT and is much more permissible than GPL (MySQL License.) For all practical use cases, one does not need to worry about the license of PostgreSQL for most of their work.
There are not many relational databases that satisfy all three of the following commandments:
- The database is open source like PostgreSQL (liberal licensing.)
- The database is community-owned.
- The database comes with extensive user base and adoption.
To me, this is one of the greatest strengths of the PostgreSQL database.
Conclusion
In this blog, we have gone over a couple of features offered by PostgreSQL that are not offered by other database management systems like MySQL.
If we further compare PostgreSQL against MySQL and other database management systems, we would notice that there are a couple more subtle differences including, but not being limited to:
- Vacuum in PostgreSQL vs. Purge in MySQL.
- Processes in PostgreSQL vs. Threads in MySQL. (MySQL uses threads)
- Table inheritance which is present in PostgreSQL, but not present in MySQL.
And a lot more. It is important to understand how any features you've chosen to employ will impact your database infrastructure as a whole as database management systems have been developed for a wide variety of use cases. Avoid comparing features just for the sake of comparing though - these database management systems existed for ages, new features are getting added very frequently and the roadmap is changing rapidly.
As far as PostgreSQL is concerned, keep in mind that while it has its own draw-backs, it's considered one of the most advanced open source database management systems available for use today. It is our responsibility as software engineers to understand all of the tradeoffs posed by the database management system, and make sound decisions. We hope that this article has given you some more insight on what's available in PostgreSQL and thereby allowed you to make informed decisions.





Top comments (0)