
I was 12 years old when I first heard about SQL triggers. My brother, Jonathan, had just begun his software career at a startup. Jonathan came home one day frustrated by a database full of convoluted SQL triggers.
With my only programming experience being recreating my favorite video game in VB6, I had little consolation to offer.
Fast forward 16 years, and now I can see from my brother’s perspective. In the world of open source start-up style full-stack development (think Django, Rails, Javascript, PHP, MySQL, Postgres..), ORMs are very popular and features like SQL triggers are far less conventional.
But there is still value with SQL triggers. During my time working on custom ERP-like software, SQL triggers were an invaluable tool. When building highly data oriented software, especially when the data is of financial nature and accuracy is of high demand, you're more likely to see data being manipulated at a lower level, in a more direct way.
This article contains all the information I wish I could have shared with my brother on how to effectively use SQL triggers.
Table of contents
- What is a SQL Trigger?
- How to Create a SQL Trigger - Syntax
- Postgres Trigger Example 1: Creating a Time Clock
- Postgres Trigger Example 2: Creating an Audit Table
- Additional Considerations for Triggers
What is a SQL Trigger?
SQL Triggers, also called Database Triggers, allow you to tell your SQL engine (for these examples, Postgres) to run a piece of code when an event happens, or even before the event.
In Postgres, you delineate the code to run by creating a function whose return type is trigger. In some other engines like MySQL, the code block is a part of and inside the trigger.
Before I discuss what the different event types are and the specific syntax for creating a trigger, why would you want to use a database trigger?
Advantages of using SQL Triggers
Maintaining data integrity
Database triggers have a variety of uses and are an excellent tool to marshal strict data integrity. Alternate solutions like Django's model hooks may fail if you have other application servers or users accessing the database who aren't aware of the specific business logic coded in your application.
Separating business logic
Coding critical business logic within the application code also presents problems when the business logic is updated. If you had a business requirement to multiply an incoming number by 10, and you wanted to revise this logic to multiply the number by 20, changing the logic in SQL would guarantee that every piece of data from that exact deploy time on would be affected by the new logic.
The SQL server acts as a single point of truth. If the logic is implemented on multiple application servers, you can no longer expect a clean, definitive change in behavior.
Atomic transactions
Natural atomicity is another desirable feature bundled with triggers. Since the event and the trigger function are all part of one atomic transaction, you know with absolute certainty that the trigger will fire if the event fires. They are as one, in perfect SQL matrimony.
How to Create a SQL Trigger - Postgres Syntax
Here are the components to creating a trigger for your database:
- Trigger Event Type
- Before or After the event
- Effect of the Trigger
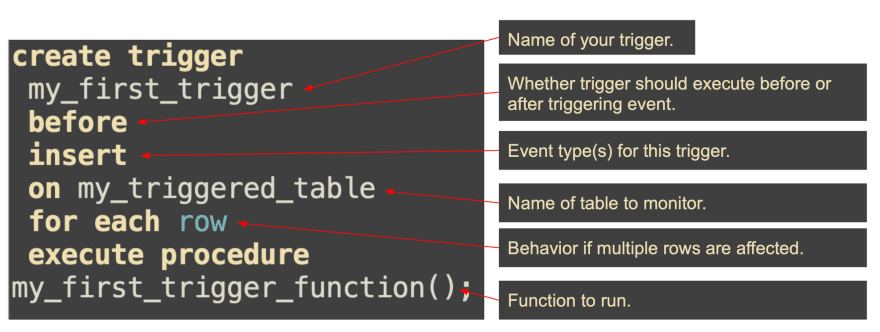
Trigger event types
Database triggers will monitor tables for specific events. Here are some examples of different events that can activate a trigger:
- Changing data:
INSERT,UPDATE,DELETE
A database trigger can also list more than one of these events.
If UPDATE was one of the listed events, you can pass in a list of columns that should activate the trigger. If you don't include this list, updating any column will activate it.
Trigger BEFORE or AFTER
A trigger can run either BEFORE or AFTER an event.
If you want to block an event like an INSERT, you will want to run BEFORE. If you need to be sure the event actually is going to occur, AFTER is ideal.
Effect of the trigger
A trigger can run either per row, or per statement. Let's say you run a single UPDATE statement that changes 5 rows in a table.
If you specify FOR EACH ROW in the trigger, then the trigger will run 5 times. If you specified FOR EACH STATEMENT, then it would only run once.
And of course we can't forget the actual code to run when the trigger is activated. In Postgres, is placed in a function and separated from the trigger. Separating the trigger from the code it runs creates cleaner code and allows multiple triggers to execute the same code.
Postgres Trigger Example #1: Creating a Time Clock
A time clock records when an employee comes and leaves from work and calculates his/her total hours worked. Let's create an example time clock and look at how we can use triggers to prevent employees from inputting invalid data.
Setting up the DB schema
The design of this schema treats each punch in and out as separate events. Each event is a row in the time_punch table. Alternatively, you could also make each employee" shift" an event and store both the punch in and punch out time in one row.
In a future post I’ll do a deep dive on how to define a strong database schema. Sign up for Arctype and get SQL/database guides and tips sent straight to your inbox!
For this example I've gone ahead and defined the schema for our tables. The code below creates an employee and time_punch table and inserts some time punch data for a new employee, Bear.
create table employee (
id serial primary key,
username varchar
);
create table time_punch (
id serial primary key,
employee_id int not null references employee(id),
is_out_punch boolean not null default false,
punch_time timestamp not null default now()
);
insert into employee (username) values ('Bear');
insert into time_punch (employee_id, is_out_punch, punch_time)
values
(1, false, '2020-01-01 10:00:00'),
(1, true, '2020-01-01 11:30:00');
Bear has clocked in at 10:00am and out at 11:30am (long day at work). Let's write a SQL query to calculate how long Bear has worked.
Take a pause here and think about how you would solve this given our schema and using only SQL.
Using SQL to calculate time worked
The solution I decided on looks at each "out" punch and matches it with its preceding "in" punch.
select tp1.punch_time - tp2.punch_time as time_worked
from time_punch tp1
join time_punch tp2
on tp2.id = (
select tps.id
from time_punch tps
where tps.id < tp1.id
and tps.employee_id = tp1.employee_id
and not tps.is_out_punch
order by tps.id desc limit 1
)
where tp1.employee_id = 1
and tp1.is_out_punch
time_worked
-------------
01:30:00
(1 row)
In this query I select all the out punches, then I join them to the closest preceding "in" punch. Subtract the timestamps, and we get how many hours Bear worked for each shift!
One of the issues with this schema is that it is possible for you to insert several "in" or "out" punches in a row. With the query we’ve created, this would introduce ambiguities that could lead to inaccurate calculations and employees getting paid more or less than they should.
SQL INSERT BEFORE trigger example - preserving data integrity
We need something to prevent the in/out pattern from being interrupted. Unfortunately check constraints only look at the row being inserted or updated and cannot factor in data from other rows.
This is a perfect situation to use a database trigger!
Let's create a trigger to prevent an INSERT event that would break our pattern. First we'll create the "trigger function". This function is what the trigger will execute when the event type is detected.
A trigger function is created like a regular Postgres function, except that it returns a trigger.
create or replace function fn_check_time_punch() returns trigger as $psql$
begin
if new.is_out_punch = (
select tps.is_out_punch
from time_punch tps
where tps.employee_id = new.employee_id
order by tps.id desc limit 1
) then
return null;
end if;
return new;
end;
$psql$ language plpgsql;
The new keyword represents the values of the row that is to be inserted. It also is the object you can return to allow the insert to continue. Alternatively, when null is returned this stops the insertion.
This query finds the time_punch before and ensures its in/out value is not the same as what's being inserted. If the values are the same, then the trigger returns null and the time_punch is not recorded. Otherwise, the trigger returns new and the insert statement is allowed to continue.
Now we'll link the function as a trigger to the time_punch table. BEFORE is crucial here. If we ran this trigger as an AFTER trigger it would run too late to stop the insertion.
create trigger check_time_punch before insert on time_punch for each row execute procedure fn_check_time_punch();
Let's try to insert another "out" punch:
insert into time_punch (employee_id, is_out_punch, punch_time)
values
(1, true, '2020-01-01 13:00:00');
Output:
INSERT 0 0
We can see from the output that the trigger prevented the insertion of two subsequent out punches for the same employee.
It is also possible to raise an exception from the trigger so that your application (or person running the SQL query) receives a failure notice instead of the insert count simply being 0.
Postgres Trigger Example #2: Creating an Audit Table
Accurately storing employee punch data is critical for businesses. This type of data often ends up directly translating to an employee's salary, and on the other end, a company's payroll cost.
Because of the importance of this data, let’s say the company wants to be able to recreate all the historical states of the table in the event that an irregularity is discovered.
An audit table accomplishes this by keeping track of every change to a table. When a row is updated on the main table, a row will be inserted into the audit table recording its past state.
I will use our time_punch table to demonstrate how to create an automatically updating audit table using triggers.
Create the audit table
There are several ways to keep an audit or history table. Let's create a separate table that will store the past states of time_punch.
create table time_punch_audit (
id serial primary key,
change_time timestamp not null default now(),
change_employee_id int not null references employee(id),
time_punch_id int not null references time_punch(id),
punch_time timestamp not null
);
This table stores:
- Time the punch was updated
- Employee who updated it
- ID of the punch that was changed
- Punch time before the punch was updated
Before we create our trigger, we first need to add a change_employee_id column to our time_punch table. This way the trigger will know which employee made every change to the time_punch table.
alter table time_punch add column change_employee_id int null references employee(id);
(An alternative solution without adding any columns to time_punch could be to revoke update permission on this table, and force users of this database to use a custom function like update_time_punch(id, change_user_id, ...))
SQL UPDATE AFTER trigger example - inserting data
After an update happens to our time_punch table, this trigger runs and stores the OLD punch time value in our audit table.
create or replace function fn_change_time_punch_audit() returns trigger as $psql$
begin
insert into time_punch_audit (change_time, change_employee_id, time_punch_id, punch_time)
values
(now(), new.change_employee_id, new.id, old.punch_time);
return new;
end;
$psql$ language plpgsql;
create trigger change_time_punch_audit after update on time_punch
for each row execute procedure fn_change_time_punch_audit();
The NOW() function returns the current date and time from the SQL server's perspective. If this were linked up to an actual application, you'd want to consider passing in the exact time the user actually made the request to avoid discrepancies from latency.
During an update trigger, the NEW object represents what values the row will contain if the update is successful. You can use a trigger to "intercept" an insert or update by simply assigning your own values to the NEW object. The OLD object contains the row's values pre-update.
Let's see if it works! I have inserted a second user named Daniel who will be the editor of Bear's time punches.
select punch_time
from time_punch
where id=2;
punch_time
---------------------
2020-01-01 11:30:00
(1 row)
I'm going to run the query below twice to simulate 2 edits that increase the time by 5 minutes.
update time_punch set punch_time = punch_time + interval '5 minute', change_employee_id = 2 where id = 2;
And here is the audit table, reflecting the past punch times:
change_time | username | punch_time
----------------------------+----------+---------------------
2021-01-06 20:10:56.44116 | Daniel | 2020-01-01 11:35:00
2021-01-06 20:10:55.133855 | Daniel | 2020-01-01 11:30:00
Additional Considerations for Triggers
There are a few things to be wary of with database triggers:
- Maintaining triggers over time
- Connected trigger logic
- Developer expertise
Maintaining triggers over time
Business logic in application code is naturally documented as it changes over time by way of git or another source control system. It's easy for a developer to see some logic in a codebase and do a quick git log and see a list of changes.
Managing changes over time with SQL triggers and functions is more complicated, less standardized, and requires more thought and planning.
Connected trigger logic
Triggers can also set off other triggers, quickly complicating the results of what could appear to be an innocent INSERT or UPDATE. This risk is also inherent in application code with side effects.
Developer expertise
Awareness of triggers is also far lower among some developer circles so introducing them increases the investment in training that will be required for new developers to successfully work on your project.
SQL can initially be a clumsy and frustrating language to learn as many of the patterns you learn to build a query are "inside out" from how you'd extract data in a procedural language.
Using Triggers to Level Up Your SQL Game
I hope that these examples have helped you develop a better understanding of database triggers. I have had great successes using triggers for data problems where traceability, consistency, and accuracy are paramount.
Making the decision to introduce triggers to your application is one that should be made after careful thought - and I for one hope you get an opportunity to implement and explore one of SQL's most fun and intriguing features!
If you're interested in continuing to improve your SQL skills, consider checking out Arctype. Arctype is a modern SQL editor designed to simplify the process of working with databases and SQL. Join our growing community and download Arctype today.





Top comments (0)