If you are a beginner data scientist, chances are you have done a lot of coding and training models on Jupyter notebooks, a powerful tool for rapid prototyping or testing that makes your life easy. Unfortunately, a lot of online courses rarely leave the awesome notebook interface and spoon feed you with the necessary files in one folder where you can access them with one line of code, or if you are following a tutorial you could just copy the pieces where the author downloaded and store the data for analysis/training.
This is all sweet and fine until you face the real world where files are downloaded and combined to be cleaned by no one but you, and if you were like me, putting every thing in the same folder where your code resides, you will get a really messy and unproductive environment. So is there a solution to this? yes there is and it's not that complicated as I thought.
A Little Bit Of Style
Dealing with lots of raw files is not that sweet, you go through a lot of changes and modifications and data cleaning, with small number of files, that's ok. But when you are adding helper text files (dates, prices, brands ..etc) and some old notebook that is useful, your file will grow to something very ugly and unproductive like this mess:
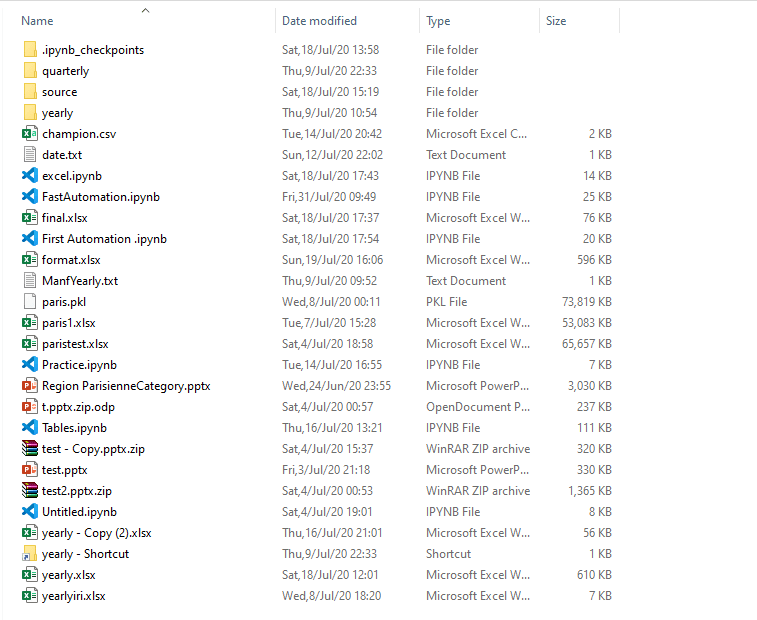
fig. 1 My messy old style
I knew I had to find away to organize this crazy bill of ordered chaos that in one week will be just chaos, but the solution I knew would involve working with filesystem through code, which was something totally foreign to me. So let's imagine that we can deal with filesystem easily (will go through that shortly), how can we get organized?
A nice style that I have seen professionals follow and find it quit generalize-able to different data science projects is very simple yet very effective. The idea is simple, get all related stuff into one folder, and very related stuff to a deeper folder if need, that's it! A good start is to divide your project files into: input and output folders, the input can be divided further into 2 folders, source folder that contains raw dirty files and data folder where the clean stuff your code needs are nicely put in one place, this can be divide further for specific type of data in one folder (e.x., csv files) you get the idea. This is how this looks in practice:
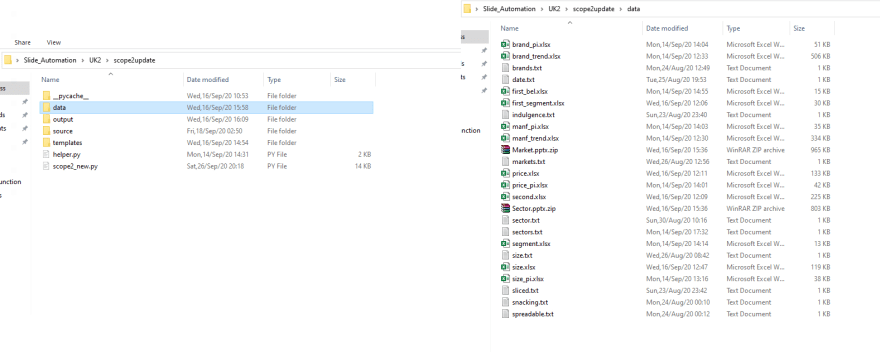
fig. 2 Much better
Think Of A Potato Not A Tree
Potatoes are root vegetables, for the city boys that means the good stuff are found in the roots under the dirt not up on the plant like other vegies. The filesystem is similar to a potato plant, there is one root file at the top and you go down the paths/roots until you reach the file you want:

fig. 3 Potato plant
The downward movement is not the only similarity between the two, if you look at the picture, imagine the far left potato is your file you are currently at, to go to the far right potato, you need to go in the root direction until you find a node (path) that leads to where your target potato, I mean where the file at. Let's say you're at data folder in the previous images, to go to source folder you need to move up to scope2updated then you go to source. That's it just moving up or down, how you ask, this will come next.
Slashes Rook \m/

Slash, A legend
If you only use windows, it's very likely that you never navigated through file using the command line, which what people did (still do) on unix operating systems. The idea is simple, to navigate through the filesystem using command line ( using Python for example) you need to know 3 things:
- Your current location (i.e., which folder are you running your code from) Relative
- Your root file and the big files inside it. Absolute
- Target location. Relative vs Absolute
Relative Path
As this is a general introduction and an icebreaker on the subject, I will cover useful and general information, if you want more you can use these info as a starting point for deeper search.
Relative path is what you need most as a data scientist, you are basically telling your code to use your current location as a pusdo-root folder where you use it as a start to go deeper to wanted folders if you wish. This way once you move your project folder to different devices, the code will run no matter wherever you place your folder in the new filesystem. This current location is expressed as "./" in the path string inside Python path objects. So let's say you want to go to date.txt file in figure 2. the path will be "./data/date.txt".
os.chdir(), os.listdir()
The power of the Relative path truly shins with the filesystem navigation and manipulation methods. Two very useful methods are chdir and listdir -of the os library in Python- short for change directory and list directory respectively. listdir gives you a list of the file/folders names inside your current location -the default- or inside a folder you gave the path to as an argument. chdir changes the default location or focus to a different folder, this can be useful if you want to run the function on different folders -data cleaning for example- smoothly with minimum modifications to the path string.
Relative Home "../"
Relative home is the parent folder hosting your current folder (i.e., the folder that contains your working folder). A good scenario that you may find yourself in: you are inside one folder and want to go up to the parent folder, either to get a file or go back after an os.chdir. This can happen easily using "../" as your path to go back, or add another folder name if you wish to change folders on the same level (think data cleaning).
Working Example
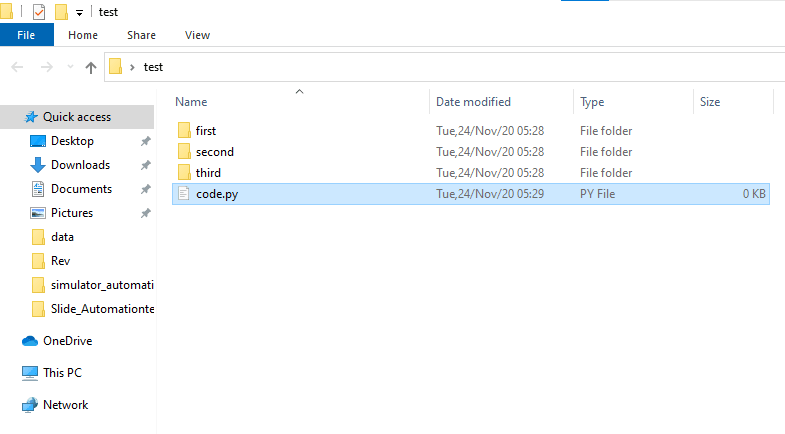
fig. 4
So we are here, we have 3 folders and we want to do some cleaning on their contents. The function/s is same and will follow the same steps, so we only need to change the path then we are good to go.
We start with os.chdir('./first') or os.chdir('first') directly. This will change the working directory to 'first'. After our business is done with 'first', we either can go back to our original starting point and switch to 'second' or switch to second directly as follows: os.chdir('../') >> os.chdir('second') or os.chcdir('../second') directly and so on with other folders.
Absolute Path '/'
We end our discussion with the absolute path, not that common to deal with if you're only doing data science stuff but still, a good to know small detail that you may need someday. The absolute path is the original root where every things falls under, usually you use this address or path if you are working on a system level where you need to access files scattered around the whole computer.
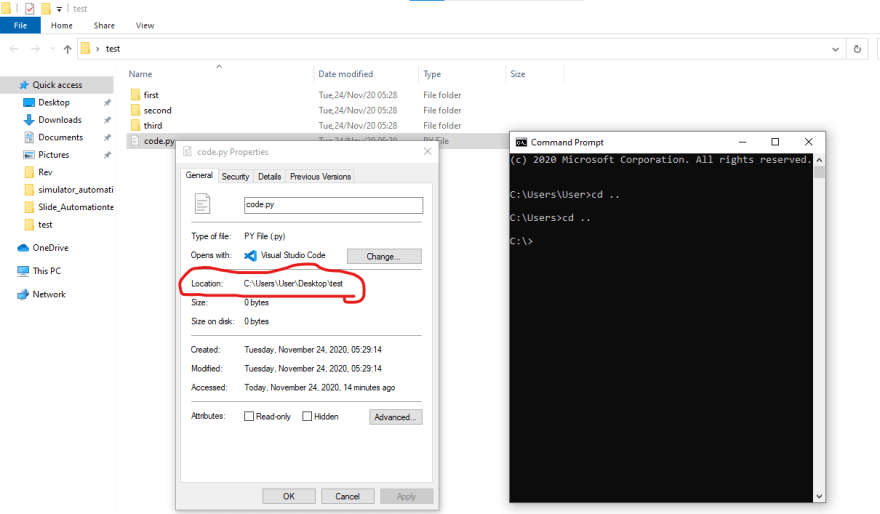
fig. 5
This is the absolute path to the folder test from the working example, notice how the slashes are the other way around in the widows OS. You can get the absolute path of a file or folder in python using the os.path.abspath(path_string).
This is about it folks! Hope you are willing to utilize the power of filesystem in your projects now and you it find as useful as much as I do.



Top comments (0)