
This article explains how to download Ollama and deploy AI large language models (such as DeepSeek-R1, Llama 3.2, etc.) locally. Using Ollama—an open-source large language model service tool—you can run powerful open-source AI models on your own computer. We'll provide comprehensive instructions for installation, setup, and most importantly, debugging the API endpoint to enable seamless interaction with your AI models.
Table of Contents
- Step 1: Download and Install Ollama
- Step 2: Install AI Models
- Step 3: Interact with AI Models
- Step 4: Optional - Simplify Workflows with GUI/Web Tools
- Step 5: Debug the Ollama API
Step 1: Download and Install Ollama
- Visit Ollama's official GitHub repository: https://github.com/ollama/ollama
- Download the version corresponding to your operating system (this tutorial uses macOS as an example; Windows follows similar steps).

- Complete the installation.

After installation, open the Terminal (on macOS, press F4 and search for "Terminal"). Enter ollama - if the following prompt appears, installation was successful.

Step 2: Install AI Models
After installing Ollama, download the desired AI model using these commands:
ollama run llama3.2
Available models (replace llama3.2 with your preferred model):
| Model | Parameters | Size | Download |
|---|---|---|---|
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 4 Mini | 3.8B | 2.5GB | ollama run phi4-mini |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Granite-3.2 | 8B | 4.9GB | ollama run granite3.2 |
A progress indicator will appear during download (duration depends on internet speed):

When prompted with "Send a message", you're ready to interact with the model:

Step 3: Interact with Llama3.2
Example interaction (asking "Who are you?"):

- Use
Control + Dto end the current session. - To restart later, simply rerun
ollama run llama3.2.
Step 4: Optional GUI/Web Interface Support
Using a terminal for daily interactions can be inconvenient. For a more user-friendly experience, Ollama's GitHub repository lists multiple community-driven GUI and web-based tools. You can explore these options independently, as each project provides its own setup instructions. Here's a brief overview:
-
GUI Tools
- Ollama Desktop: Native app for macOS/Windows (supports model management and chat).
- LM Studio: Cross-platform interface with model library integration.
-
Web Interfaces
- Ollama WebUI: Browser-based chat interface (run locally).
- OpenWebUI: Customizable web dashboard for model interaction.
For details, visit the Ollama GitHub README.
Step 5: Debug the Ollama API
Ollama exposes a local API by default. Refer to the Ollama API Docs for details.

Below, we will use Apidog to debug the local API generated by Ollama. If you haven't installed Apidog yet, you can download and install it—it's an excellent tool for API debugging, API documentation, API mocking, and automated API testing.
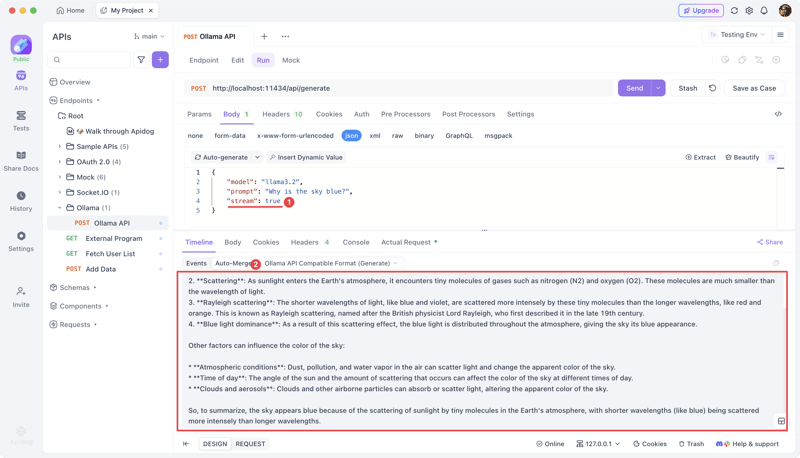
Create a New Request
Copy this cURL command:
curl --location --request POST 'http://localhost:11434/api/generate' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"stream": false
}'
In Apidog:
- Create a new HTTP project.
- Paste the cURL into the request builder.
- Save the configuration.

Send the Request
Navigate to the "Run" tab and click "Send". The AI response will appear.

For streaming output, set "stream": true.

Advanced API Debugging Tips
Here are some additional tips for debugging the Ollama API effectively:
- Check API Status: Verify the Ollama service is running with:
curl http://localhost:11434/api/version
-
Troubleshoot Common Issues:
- Ensure Ollama is running before making API calls
- Check that your model is correctly downloaded (
ollama list) - Verify the port isn't blocked by a firewall
Customize API Parameters: Experiment with these parameters in your requests:
{
"model": "llama3.2",
"prompt": "Write a short poem about coding",
"system": "You are a helpful assistant that writes poetry",
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"max_tokens": 500
}
- Implement Error Handling: Always check for error responses from the API and handle them gracefully in your applications.
Conclusion
This guide covered:
- Ollama installation
- Model deployment
- Command-line interaction
- API testing and debugging with Apidog
You now have a complete workflow for local AI model experimentation, application development, and API debugging. By mastering the Ollama API, you can build sophisticated applications that leverage powerful AI models running entirely on your local machine.



Top comments (0)