 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--DKTl4EFh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/9428/0%2AGAOT-Q6MTvfw2W2c)
In a previous post, I wrote about EventBridge Scheduler and how we can use it to build a reminder application. In this article, we’ll explore how scheduling messages in the future can be also an alternative to batch jobs. This approach is sometimes overlooked; it offers advantages such as reducing system load and improving cost efficiency.
To illustrate this pattern, we’ll design a system that needs to execute a task after a specified delay whenever a new item is created in a database. This task could involve operations such as resource creation or resource cleanup.
Here are two approaches to solving this:
- A batch job is triggered on a schedule, this job selects all newly created items that match the creation time criteria and performs the required tasks for each:

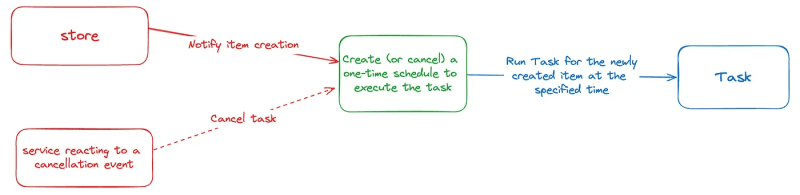
- Or an event-based approach: When an item is created, the system schedules a one-time message for that new item to be triggered in the future. At due time, the message is sent and the associated task is executed:

There are some downsides to using a batch job approach compared to an event-based approach:
Potential delays: Batch jobs run on a fixed schedule, causing tasks to be processed at intervals. This can lead to delays, as some tasks will only be executed after the next batch execution. An event-based approach triggers tasks instantly when execution time criteria is met, ensuring timely execution.
Resource overhead and inefficiency: Depending on how the data is stored, batch jobs can be resource-intensive, particularly when processing a large number of records at once. For example, if the data is stored in a DynamoDB table, it may require scanning the table to find items matching item’s creation time criteria or adjusting the design of the table. This can lead to sub-optimal resource usage. In contrast, an event-based approach distributes the workload more evenly over time and potentially lowering costs by eliminating the need for periodic processing.
⚠️ A word on cancellation on the event-based approach: This pattern can become tricky when handling task cancellations. Possible solutions include adding the ability to delete an existing schedule when a cancellation event occurs or validating in the ‘Run Task’ step whether the scheduled action is still eligible for execution.
Possible implementations
In the example, I’ll use DynamoDB as the storage layer. However, the same principles apply to other storage systems that support item-level change data capture.
❌ Using TTL as a scheduling mechanism
One solution is to leverage DynamoDB’s TTL item expiration. When creating the original item, add an associated item in the same transaction, which we’ll call a ‘signal’. This signal is created with a TTL that matches the desired event date. And then, configure a DynamoDB Stream and subscribe the ‘Run Task’ function to the signal item expiration event.

🛑 There is an issue with this approach: The item expiration and deletion are not guaranteed to be immediate so tasks for these new items might not run exactly at the due time. The DynamoDB TTL docs do not specify a precise timeframe; item expiration can occur within a few days:
](https://res.cloudinary.com/practicaldev/image/fetch/s--DYMCEs-c--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/3876/1%2A9O3YtdYZHHpuagLKWDKi0A.png)
If there are no strict requirements to trigger the task at the exact expected time, this solution can be suitable. It’s a tradeoff.
✅ A better solution
There is a better solution with EventBridge Scheduler and one-time schedules capability:

The ‘Create One-Time Schedule for New Items’ function filters for newly created items in the table’s stream and creates a new schedule for each. While I could have configured the EventBridge Scheduler to directly trigger a Lambda function as the target, this approach might not be suited when dealing with a high volume of events. In some cases, it’s better to use a queue as target and control the ‘Run Task’ function concurrency. This way, the function can process messages at a manageable rate. It’s about finding the right balance between direct invocation and rate control, and depending on the concrete use case at hand.
On a side note, I would have loved to see EventBridge Scheduler as a target of EventBridge Pipes; this could have simplified the solution even further.
Let’s see how to implement this with EventBridge Scheduler. I’ll be using terraform for IaC and Rust for functions code.
Scheduling new tasks
First, I’ll create a dedicated scheduler group to organise all scheduled tasks within a single group:
resource "aws_scheduler_schedule_group" "schedule_group" {
name = "${var.application}-${var.environment}"
}
The ‘Schedule Tasks’ function handles only new items created on the table. We achieve this by using DynamoDB Stream filtering capabilities provided by the event source mapping. As a result, the function will be invoked only when new items are inserted:
resource "aws_lambda_event_source_mapping" "schedule_task_lambda" {
event_source_arn = aws_dynamodb_table.table.stream_arn
function_name = aws_lambda_function.schedule_task_lambda.function_name
starting_position = "TRIM_HORIZON"
function_response_types = ["ReportBatchItemFailures"]
filter_criteria {
filter {
pattern = jsonencode({
eventName = ["INSERT"]
})
}
}
}
To create new one-time schedules on EventBridge Scheduler, this function requires the scheduler:CreateSchedule action on the custom scheduler group, as well as the iam:PassRole action for the role used by the schedule. A role that grants permission to send messages to the Tasks SQS queue:
...
{
Effect = "Allow"
Action = [
"scheduler:CreateSchedule"
]
Resource = "arn:aws:scheduler:${region}:${account_id}:schedule/${aws_scheduler_schedule_group.schedule_group.name}/*"
},
{
Effect = "Allow"
Action = [
"iam:PassRole"
]
Resource = aws_iam_role.scheduler_role.arn
},
...
Zooming in on the ‘Schedule Task’ function code
For each new item, we’ll create a schedule that will trigger once, two hours after the item’s creation time:
async fn process_new_item(
new_item: &SomeItem,
scheduler_client: &aws_sdk_scheduler::Client,
scheduler_group_name: &String,
scheduler_target_arn: &String,
scheduler_role_arn: &String,
) -> Result<(), Error> {
// as an example, we'll configure a one-time schedule two hours after the item was created
let now = Utc::now();
let two_hours_later = now + Duration::hours(2);
let two_hours_later_fmt = two_hours_later.format("%Y-%m-%dT%H:%M:%S").to_string();
let response = scheduler_client
.create_schedule()
.name(format!("schedule-{}", &new_item.id))
.action_after_completion(ActionAfterCompletion::Delete)
.target(
Target::builder()
.input(serde_json::to_string(&new_item)?)
.arn(scheduler_target_arn)
.role_arn(scheduler_role_arn)
.build()?,
)
.flexible_time_window(
FlexibleTimeWindow::builder()
.mode(FlexibleTimeWindowMode::Off)
.build()?,
)
.group_name(scheduler_group_name)
.schedule_expression(format!("at({})", two_hours_later_fmt))
.client_token(nanoid!())
.send()
.await;
match response {
Ok(_) => Ok(()),
Err(e) => {
error!("Failed to create schedule: {:?}", e);
return Err(Box::new(e));
}
}
}
The important bits:
Some parameters are required. When defining the target, you’ll need to provide the message payload and specify the role that EventBridge Scheduler will use to invoke the target as well as the target arn, which is the arn of the SQS queue in this case.
We also need to ensure that the schedule is deleted after the target invocation is successful by using
ActionAfterCompletion::Delete
And since we configured the function response type to ReportBatchItemFailures, here is how process_new_item is called by the function handler:
async fn process_records(
event: LambdaEvent<Event>,
scheduler_client: &aws_sdk_scheduler::Client,
scheduler_group_name: &String,
scheduler_target_arn: &String,
scheduler_role_arn: &String,
) -> Result<DynamoDbEventResponse, Error> {
let mut response = DynamoDbEventResponse {
batch_item_failures: vec![],
};
if event.payload.records.is_empty() {
return Ok(response);
}
for record in &event.payload.records {
let item = record.change.new_image.clone();
let new_item: SomeItem = serde_dynamo::from_item(item)?;
let record_processing_result = process_new_item(
&new_item,
scheduler_client,
&scheduler_group_name,
&scheduler_target_arn,
&scheduler_role_arn,
)
.await;
if record_processing_result.is_err() {
let error = record_processing_result.unwrap_err();
error!("error processing item - {}", error);
response.batch_item_failures.push(DynamoDbBatchItemFailure {
item_identifier: record.change.sequence_number.clone(),
});
}
}
Ok(response)
}
Once new tasks are correctly scheduled, they will be visible on the schedules page in the console:

We can also view the details related to the schedule’s target in the console

When the scheduled task time is due, the message associated with the item, will be sent to the SQS queue and then processed by the ‘Run Task’ function. That’s all 👌 !
Wrapping up
With one-time schedules EventBridge Scheduler enables interesting patterns that can improve application architecture by reducing the overhead associated with batch jobs. But as always, choosing between an event-driven approach or batch jobs depends on your application’s needs and complexity of the use case at hand.
You can find the complete source code, this time written in Rust and Terraform, ready to adapt and deploy 👇
GitHub - ziedbentahar/scheduling-messages-in-future-with-eventbridge-scheduler
Thanks for reading — I hope you found it helpful!





Top comments (0)