
what is the difference between auto machine learning and AWS SageMaker Autopilot?
SageMaker Autopilot uses a transparent approach to AutoML

In nontransparent approaches, as shown in the image below, we don’t have control or visibility into the chosen algorithms, applied data transformations, or hyper-parameter choices. We point the
automated machine learning (AutoML) service to our data and receive a trained model.
This makes it hard to understand, explain, and reproduce the model. Many AutoML solutions implement this kind of nontransparent approach.

as you see, in many AutoML services, we don’t have visibility into the chosen algorithms, applied data transformations, or hyper-parameter choices.
SageMaker Autopilot documents and shares its findings throughout the data analysis, feature engineering, and model tuning steps.
SageMaker Autopilot doesn’t just share the models; it also logs all observed metrics and generates Jupyter notebooks, which contain the code to reproduce the model pipelines, as visualized in the image bellow
The data-analysis step identifies potential data-quality issues, such as missing values that might impact model performance if not addressed. The Data Exploration notebook contains the results from the data analysis step. SageMaker Autopilot also generates another Jupyter notebook that contains all pipeline definitions to provide transparency and reproducibility. The Candidate Definition notebook highlights the best algorithms to learn our given dataset, as well as the code and configuration needed to use our dataset with each algorithm.
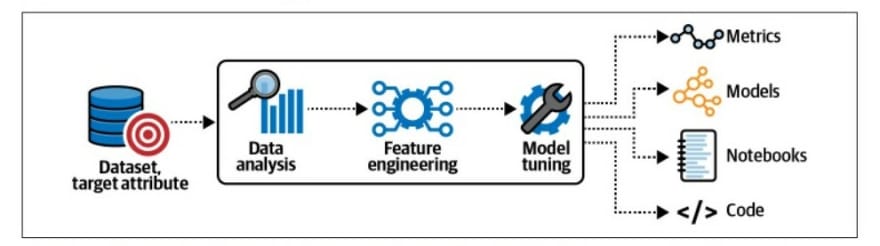
SageMaker Autopilot generates Jupyter notebooks, features engineering scripts, and model code.
Resources :
Data science on AWS Book




Top comments (0)