Phase 0: BASH
BASH
In the early days, our configuration where written in BASH scripts. But the POSIX compliance nightmare meant that these BASH or Shell or Fish or whatever shell your OS is on became a nightmare to debug and extend. !#/usr/bin/sh should have been the norm, but alas here we are trying to mitigate this disaster by creating an abstraction on top of OS.
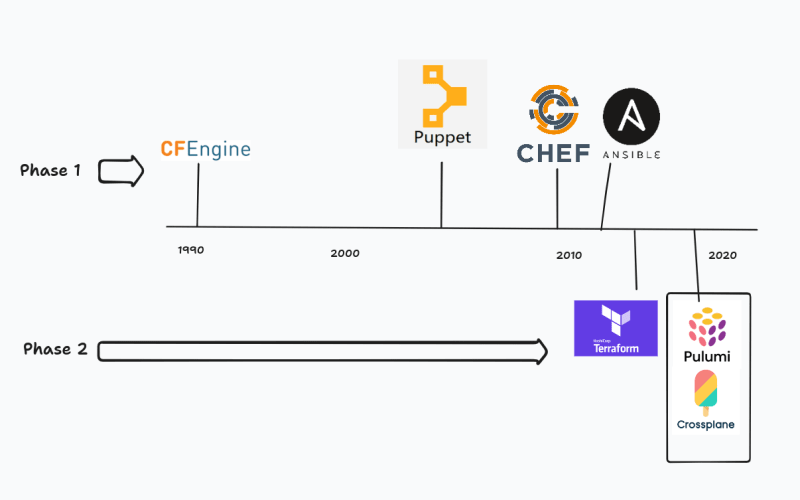
Phase 1: CFEngine and the rest
1990s brought in the abstraction of OS-based IaC tools. it started with CFEngine as a side project by Mark Burgess (Post doctorate student) to automate the workstations at his university. This sparked configuration management tools such as Chef, Puppet, Ansible etc. in the late 2000s to early 2010s The above just gives a timeline of when these were created. These were fantastic tools at the time, when people rented servers but not from the cloud giants such as AWS, Azure, (probably GCP) etc. When the clouds came in, there seemed to be a shift in IaC to have tools which
Interacted with the cloud providers
No have a vendor-lockin
That is when tools such as Terraform came which provided an abstraction over the cloud providers.
Before we go further, we need to understand the pure basics of IaC tools. Before the event we need to see what IaC tools are not. IaC tools are not:
Programming languages: Terraform has custom DSL, Chef has Ruby DSL, Ansible is YAML-based, and Puppet has its own IaC DSL called Puppet Code. So there is nothing common between them.
Target systems: Chef/Puppet/Ansible are built to configure servers and not cloud configurations; while Terraform, Crossplane, Pulumi were built to provision cloud servers.
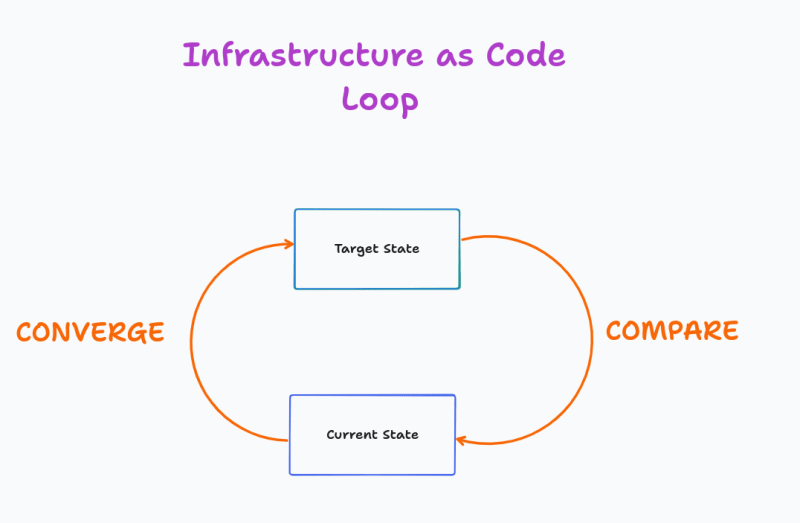
So what exactly is IaC's core value? It is creating a state machine with 2 states (Current and Target); and 2 interactions (Coverge and Compare).
We also need to add schema constructs to see what the IaC needs, as well as some sort of type-checking on what values can be passed. We'll discuss other aspects such as this in the Cue Section
IaaS, PaaS, FaaS
Apart from the traditional cloud; there was also a burst of different runtimes in the 2010s. There was OpenShift, Cloud Foundry, Kubernetes, OpenStack. All these tools required a way to be configured in its way. Mostly there was a YAML was the go-to to describe the metadata for the infrastructure to be deployed
YAML enters the chat
However due to issues with readability and lack of extendibility; there was a shift in the industry to create an abstraction that will also work in a multi-cloud environment. Whilst the first-age IaC tools (Chef, Ansible etc.) were great for creating server resources; they became a laggard in the scheme of cloud providers. The abstraction that seemed to work for most folks is YAML. Yes, YAML is far from perfect. Indentation issues are just the tip of the iceberg. Did you know of the Norway problem?!
Yeah, writing NO can break the YAML parser.
It is great for readability but a very nice way to "shoot into your foot by CTRL-C and CTRL-V". Not just IaC, but your environment variables, and properties.yaml are also IaC code which are usually key-value pairs. If these are copy pasted without having any validation logic; then you will have a nice surprise waiting for you when you deploy your code to higher environments.
Phase 2: Terraform and modern IaCs
Terraform, Crossplane and Pulumi are great tools for writing IaC. But the issue it writing your adapter for your custom Infrastructure for your specific company can be a blocker in incorporating tools.
Pulumi is a programmatic IaC tool where you can write your IaC code in Javascript, Go etc
Crossplane is a new way of writing IaC. It is not a simple CLI tool like Terraform. It is a control plane that always observes the infrastructure.
CUE: A guardrail to write custom configurations

Any IaC, deployed anywhere needs some basic principles.
Schemas: Schemas are required to validate the structure of your config file. If you are deploying to Cloud Foundry; need to validate your
manifest.ymlfile, in K8s you configure yourkubectlfile. All these tools bring the onus of correctness to the developer without providing any structured knowledge within the code on how to write these YAML configurations.Type-checking and constraints: Having a way to restrict the config value to a certain range of values is a very basic human error. A rule on incrementing the version for every release or not adding an absurdly high storage value to reduce costs are things etc.. should not be a checklist but a validation step during in order to commit the code.
Overlays or Schema Import: Have a way to extend the schema (either externally via schema import or internally within the config file using overlays.)
Cue: History
Cue was a project started by Marvel Lohuizen who worked primary at Borg (Kubernetes equivalient at Google) on the Borg Config Lang.
Its goal is to provide a declarative approach to configuring things based on rules on those data. For example, you want to configure your IP address to a range of subnets only.
Example: Cue Vet
Problem Statement: You want to make sure your S3 Buckets are deployed to an EU region only (for GDPR reasons) and you need to deploy to a specific folder my-compliant-product-folder ; and you have a YAML which is custom to your infrastructure. What would you do?
Write BASH scripts? Too much headache and different OSes (macOS, Windows, Linux, Alpine, FreeBSD) will make this script fragile like a ice sheet.
Write a python validator? Maybe, but that is time spent on creating a framework/DSL in which you are not an expert in.
Enter Cue,
Your bucketSchema.cue file:
id: stringtype: "s3" | "minio"region: "es-east-2" | "eu-west-1"
Your YAML:
id: Rg98GoEHBd4type: s3region: us-east-2
Your cue vet command
cue vet bucketSchema.cue bucketPolicy.yaml region: 2 errors in empty disjunction:region: conflicting values "eu-east-2" and "us-east-2": ./bucketPolicy.yaml:4:9 ./bucketSchema.cue:6:9region: conflicting values "eu-west-1" and "us-east-2": ./bucketPolicy.yaml:4:9 ./bucketSchema.cue:6:23
Oh wait, you put a us instead of an eu; and you have deployed to US; hence making you non-compliant!
Good thing we ran that vet command. We can fix it by changing our YAML config.
id: Rg98GoEHBd4type: s3region: eu-east-2
Run this and you can see no more errors. This simple construct can make us engineer not go into CtrlC-CtrlV mistakes
For more info on Cue; I would suggest their doc and this video
Its many other use cases include
Data Validation
Policy checking
Cross-language test generation
Cue is able to export schema to OpenAPI definitions or even protobufs!


Top comments (0)