
TLDR — This post explains how the Shapely value from coalition theory and political science can be used to help detect bias in AI with examples of how to get started with the Azure Interpretability Toolkit.
To get started with the some of the examples in this a post a free Azure subscription can be created with the link below.
Create your Azure free account today | Microsoft Azure
The Unintended Consequences of Bias In AI
At its best, AI advances society through critical high-impact applications such as Heathcare, Security and Self Driving Cars. However at its worst AI can amplify existing societal biases with unintended consequences, such as ethnic, gender or racial discrimination.

Many AI algorithms work well because they are designed to uncover subtle relationships in data. Even if explicitly removed from training data features such as ethnicity, gender or race, AI models can still learn bias through over-fitting on highly correlated features and missing information.
As AI becomes increasingly democratized with tools such as Azure AutoML, that train AI models without the need for data scientists to write AI code, the implications of Bias on production AI is more relevant than ever.
If you are interested in getting started with AutoML check out the following documentation.
What is automated ML / AutoML - Azure Machine Learning
In the following sections we will discuss how the shapely value from coalition theory can be used to help detect bias in AutoML models.
What is Coalition Theory?
A coalition is a group of different organizations or people who agree to act together to achieve a common goal. Coalition theory is a subset of game theory that analyzes how and why coalitions are formed.

Often coalition governments are formed between different political parties with overlapping objectives in parliamentary governments. In England, Israel and Finland, for example, each party receives a number of mandates and the coalition with most mandates gets to form the government.
One of the major questions raised by coalition theory is:
If a coalition is formed, what is the fair reward share that each member of the coalition receives?
While it may be tempting to divide the spoils evenly, this question is harder to answer than it seems at first glance. For:
- Not every member of a coalition contributes the same number of mandates to a coalition.
- Not all the mandates that each member contributes to a collation are independent.
For example in a parliamentary system while one party might only contribute a few mandates to a coalition, since the given party may care about different core issues than the rest of the coalition their party’s votes may determine the election outcome. In the United States this is often observed through elections where voters in key swing states may have more influence on the outcome of an election.
The question of how to fairly divide a the rewards of a coalition can be addressed with the Shapely Value.

What is a Shapely Value?
In coalition theory, the Shapley value represents the fair payoff that each member of a coalition should receive relative to the value they provide to a coalition.
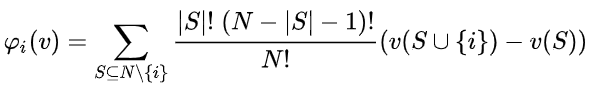
The shapely value for an member of a collation is calculated as a weighted average of their marginal contribution across all possible collations.
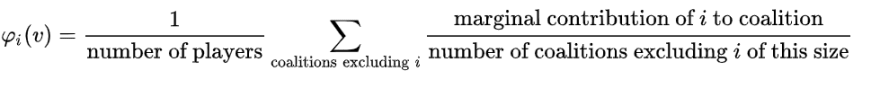
If the math doesn’t yet make sense don’t worry I will link to a great post by Edden Gerber at the end of the article that is well worth a read.
What does Parliamentary Politics have to do with interpreting AI?
The Shapley value is not limited just to politics and government. In AI, Shapley values can help quantify the individual contribution of a input feature, member of an ensemble model, or row of a data set on the outcome, and we can then use this to better interpret why a model makes a given decision.
In the Shapley value of a feature can be expensive to compute. Calculating a features Shapley value requires iterating through the marginal impact of every feature, in every possible feature combination.
Therefore estimates of the Shapley values are usually calculated using the Open Source SHAP package.
SHAP still still requires a lot of computation, this is one of the key advantages of cloud scale compute and where the Azure ML Interpretability Package can help.
Azure ML Interpretability package
The Azure ML Interpretability package provides direct support for the SHAP package. The package can be integrated with both AutoML and Custom Azure ML models to provide better insight into the impact each feature has on a given outcome, which can be used to better identify bias.

Model interpretability in Azure Machine Learning service - Azure Machine Learning
To recap we’ve explored the challenges of bias in AI, discussed parliamentary coalition theory and shown how the Shapely value can be applied with Azure Machine Learning to increase the interpretability of AI. Below I’ve listed a bunch of relevant resources and next steps for applying these learnings to your own AI models.
Next Steps and Resources
AutoML and Azure Interpretablitly Package
Shapley Values
- 5.9 Shapley Values | Interpretable Machine Learning
- A new perspective on Shapley values: an intro to Shapley and SHAP
Microsoft’s commitment to combating Bias in AI
FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
About the Author
Aaron (Ari) Bornstein is an avid AI enthusiast with a passion for history, engaging with new technologies and computational medicine. As an Open Source Engineer at Microsoft’s Cloud Developer Advocacy team, he collaborates with Israeli Hi-Tech Community, to solve real world problems with game changing technologies that are then documented, open sourced, and shared with the rest of the world.





Top comments (0)