
Cover image from Google Blog.
Google DeepMind has officially introduced Gemma 3, the latest iteration of its open-source language model series. This release brings significant improvements, including multimodal capabilities, extended context lengths, and enhanced multilingual performance. With sizes ranging from 1 billion to 27 billion parameters, Gemma 3 is designed for efficient deployment on consumer-grade hardware while delivering state-of-the-art performance. It also outperforms Llama3-405B, DeepSeek-V3 and o3-mini in human preference evaluations on the LMArena leaderboard.
Key Features of Gemma 3 🔥
1. Multimodal Capabilities
One of the biggest additions to Gemma 3 is vision understanding. Unlike previous versions, Gemma 3 can process images through a custom SigLIP vision encoder. This encoder converts images into a fixed-size vector representation that the language model interprets as soft tokens.
- Efficiency Boost: Instead of processing every pixel, Gemma 3 condenses vision embeddings into 256 vectors.
- Flexible Resolution: Uses a Pan & Scan (P&S) method, inspired by LLaVA, to process high-resolution images and non-square aspect ratios efficiently.
- Applications: Ideal for image captioning, document understanding, and visual question answering.
2. Long Context: Up to 128K Tokens
Gemma 3 significantly increases its context length compared to previous versions, supporting up to 128,000 tokens (except the 1B model, which supports 32K tokens). Handling such long contexts efficiently requires key architectural optimizations:
- Hybrid Attention Mechanism: Implements a 5:1 ratio of local-to-global attention layers, reducing memory usage while maintaining performance.
- Memory Optimization: Adjusts KV-cache memory to prevent the typical memory explosion seen in long-context models.
- RoPE Scaling: Increases RoPE (Rotary Position Embeddings) base frequency from 10K to 1M for global attention layers.
3. Architecture & Efficiency Improvements
- Grouped-Query Attention (GQA): Enhances inference speed while reducing memory footprint.
- QK-Norm for Stability: Replaces soft-capping with QK-Norm for more stable training.
- Quantization Aware Training (QAT): Provides int4, int8, and float8 quantized versions to optimize memory usage.
4. Enhanced Multilingual Support
Gemma 3 enhances its multilingual capabilities by revisiting its training data mixture and adopting the Gemini 2.0 tokenizer:
- Expanded Vocabulary: Supports 262K token entries for better non-English language processing.
- Balanced Data Strategy: Uses an improved language distribution technique to avoid overfitting to English.
- Better Handling of Non-English Scripts: Works well with languages that require byte-level encoding.
5. Instruction-Tuned Models (IT) with SOTA Performance
The instruction-tuned (IT) models of Gemma 3 undergo an advanced post-training pipeline, incorporating knowledge distillation, reinforcement learning (RLHF), and dataset filtering.
- New Post-Training Approach: Leverages BOND, WARM, and WARP techniques for instruction tuning.
- Mathematics & Reasoning Boost: Outperforms prior models on math, code, and reasoning benchmarks.
- Reduced Hallucinations: Implements in-context attribution techniques to minimize factual errors.
Performance Benchmarks 📊
Gemma 3 achieves impressive results across various AI benchmarks:
| Benchmark | Gemma 3 27B | Gemma 2 27B | Improvement |
|---|---|---|---|
| MMLU-Pro | 67.5% | 56.9% | ✅ +10.6% |
| LiveCodeBench | 29.7% | 20.4% | ✅ +9.3% |
| Bird-SQL (dev) | 54.4% | 46.7% | ✅ +7.7% |
| FACTS Grounding | 74.9% | 62.4% | ✅ +12.5% |
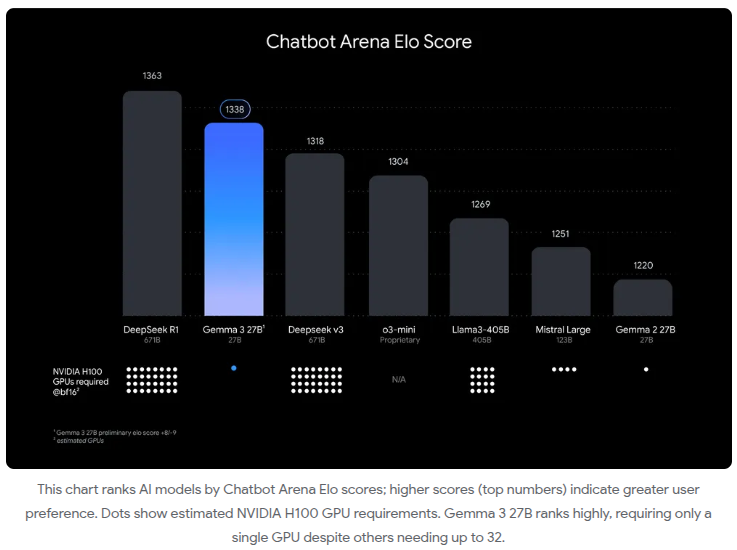
LMSYS Chatbot Arena Ranking 🏆
Gemma3-27B-IT ranked #9 globally in the LMSYS Chatbot Arena, achieving an Elo score of 1338. This puts it ahead of:
- DeepSeek-V3 (1318)
- LLaMA 3 70B (1257)
- Qwen2.5-72B (1257)
Why Gemma 3 is Important
Gemma 3 sets a new benchmark for open-source AI by combining multimodal capabilities, efficient long-context processing, and enhanced multilinguality. Unlike larger proprietary models, Gemma 3 can run efficiently on consumer hardware, making it an excellent choice for:
- Developers building chatbots, coding assistants, and research tools.
- Researchers looking for an open-source model with cutting-edge performance.
- AI Enthusiasts exploring multimodal interactions and instruction tuning.
In conclusion…
Gemma 3 is a major step toward open AI innovation. With its improved efficiency, multimodal reasoning, and long-context abilities, it's clear that Gemma 3 is one of the best open models available today (we'll see about tomorrow...).
Read the full research paper:
https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf
What do you think about Gemma 3? Drop your thoughts in the comments! 👇

Top comments (12)
wow, this benchmark is crazy. from what i heard it is about gemini-1.5 level but open source?
Yep, the model has performance near
gemini-1.5I think, and it can run easily on a single GPU, which is a great advantage for local models!I ran the 1 billion parameter model on my laptop at about 20 TPS (my laptop is weak) and for a 1b model is does really good.
1 billion sounds really big lol, idk if i can run that
1b is actually fairly small. 70b is really large, and 671b is massive (for example, DeepSeek or ChatGPT).
ok, maybe i will try it :D
Awesome! I'd recommend Ollama for running it.
ollama.com
It makes it pretty easy to run it in your terminal.
will do
Curious what you all think!
good post :)
Thank you! ❤️
The information is good
Awesome, thanks for reading 🙌