Blog written by: Nitin Sharma & Suruchi Shah from Bloomreach, 2015
Introduction
In a multi-tenant search architecture, as the size of data grows, the manual management of collections, ranking/search configurations becomes non-trivial and cumbersome. This blog describes an innovative approach we implemented at Bloomreach that helps with an effective index and a dynamic config management system for massive multi-tenant search infrastructure in SolrCloud.
Problem
The inability to have granular control over index and config management for Solr collections introduces complexities in geographically spanned, massive multi-tenant architectures. Some common scenarios, involving adding and removing nodes, growing collections and their configs, make cluster management a significant challenge. Currently, Solr doesn’t offer a scaling framework to enable any of these operations. Although there are some basic Solr APIs to do trivial core manipulation, they don’t satisfy the scaling requirements at Bloomreach.
Innovative Data Management in SolrCloud Architecture
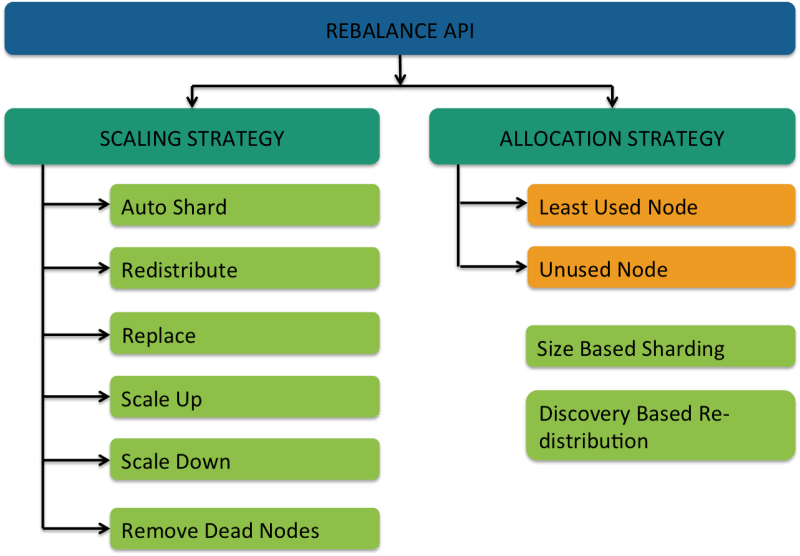
To address the scaling and index management issues, we have designed and implemented the Rebalance API, as shown in Figure 1. This API allows robust index and config manipulation in SolrCloud, while guaranteeing zero downtime using various scaling and allocation strategies. It has two dimensions:
The seven scaling strategies are as follows:
- Auto Shard allows re-sharding an entire collection to any number of destination shards. The process includes re-distributing the index and configs consistently across the new shards, while avoiding any heavy re-indexing processes. It also offers the following flavors:
- Flip Alias Flag controls whether or not the alias name of a collection (if it already had an alias) should automatically switch to the new collection.
- Size-based sharding allows the user to specify the desired size of the destination shards for the collection. As a result, the system defines the final number of shards depending on the total index size.
- Redistribute enables distribution of cores/replicas across unused nodes. Oftentimes, the cores are concentrated within a few nodes. Redistribute allows load sharing by balancing the replicas across all nodes.
- Replace allows migrating all the cores from a source node to a destination node. It is useful in cases requiring replacement of an entire node.
- Scale Up adds new replicas for a shard. The default allocation strategy for scaling up is unused nodes. Scale up also has the ability to replicate additional custom per-merchant configs in addition to the index replication (as an extension to the existing replication handler, which only syncs the index files)
- Scale Down removes the given number of replicas from a shard.
- Remove Dead Nodes is an extension of Scale Down, which allows removal of the replicas/shards from dead nodes for a given collection. In the process, the logic unregisters the replicas from Zookeeper. This in-turn saves a lot of back-and-forth communication between Solr and Zookeeper in their constant attempt to find the replicas on dead nodes.
- Discovery-based Redistribution allows distribution of all collections as new nodes are introduced into a cluster. Currently, when a node is added to a cluster, no operations take place by default. With redistribution, we introduce the ability to rearrange the existing collections across all the nodes evenly.
Figure 1: Rebalance API overview
Scenarios
Let’s take a quick view at some resolved uses cases using the new Rebalance API.
Scenario 1: Re-sharding to meet latency SLAs
Collections often grow dynamically, resulting in an increased number of documents to retrieve (up to ~160M documents) and slowing down the process. In order to meet our latency SLAs, we decide to re-shard the collection. The process of increasing shards, for instance from nine to 12, for a given collection, is challenging since there is no accessible method to divide the index data evenly while controlling the placement of new shards on desired nodes.
- API call
- End Result: As observed in the diagram below, adding a shard doesn’t add any documents by default. Additionally, the node on which the new shard resides is based on the machine triggering the action. With the Rebalance API, we automatically distribute the documents by segmenting into even parts across the new shards.
Figure 2: Auto-Sharding to an increased number of shards.

Scenario 2: Data Migration from node to node.
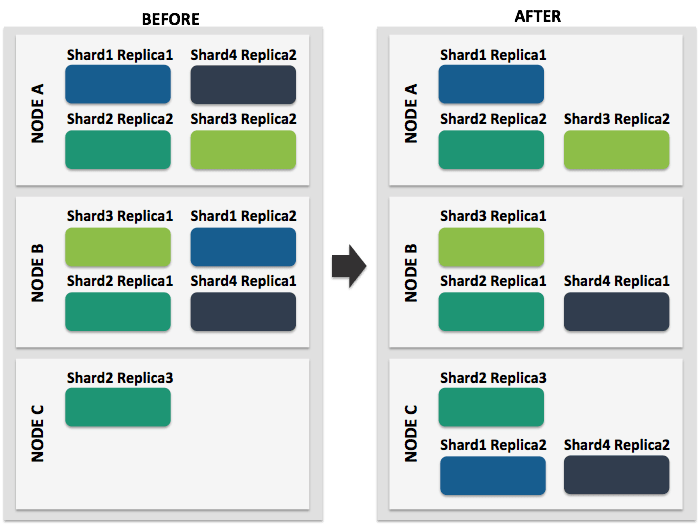
We have two nodes, one of them is out or dead and we want to migrate the replicas/cores to a different live node. OR we encounter an uneven number of replicas on a set number of nodes, leading to a skewed distribution of data load, and we need to redistribute it across nodes.
- API Call:
- End Result: As observed in the diagram below, the BEFORE section demonstrates the uneven distribution of replicas/cores across the three nodes. Upon calling the REDISTRIBUTE strategy, we divide the replicas/cores across all nodes evenly.
Figure 3: Redistributing replicas/cores across the nodes.
Scenario 3: Dynamic Horizontal Scaling
Dynamic Horizontal Scaling is very useful when, for instance, we have two cores for a collection and want to temporarily scale up or scale down based on traffic needs and allocation strategy.
API Call: http://host:port/solr/admin/collections?action=REBALANCE&scaling_strategy=SCALE_UP &num_replicas=2&collection=collection_name
End Result: We observe in the diagram below that when new replicas are added, they have to be added one at the time, without control over node allocation. Furthermore, only the index files get replicated. According to the new Rebalance API, all the custom configs are replicated in addition to the index files on the new replicas where the nodes are chosen based on the allocation strategy.
Figure 4: Scaling up both shards by adding 2 replicas each

The chart below compares the states gathered from running tests to calculate the average time to split indexes using various approaches. It is important to note that while the second method only accounts for index distribution, the REBALANCE API (third and fourth) methods also include replication of custom configs.
As we notice in the table below, the Bloomreach Rebalance API performs much better, compared to the first two methods in terms of time. Furthermore, we parallelized the split and sync operation by making the Rebalance API more efficient as demonstrated in the fourth method (for collections over 150M it gives 95% savings in auto-sharding compared to re-indexing).

Conclusion
In a nutshell, Bloomreach’s new Rebalance API helps scaling SolrCloud architecture by ensuring high availability, zero downtime, seamless shard management and by providing a lot more control over index and config manipulation. Additionally, this faster and more robust mechanism has paved the way to automated recovery by allowing dynamic resizing of collections.
And that’s not all! We have implemented the Rebalance API in a generic way so that it can be open sourced. So stay tuned for more details!




Top comments (0)