Introduction:
In the rapidly evolving world of data processing, understanding the various architectural approaches is pivotal to choosing the right tools for your specific needs. The three dominant architectures that have emerged—data parallel, task parallel, and agent actor—each offer unique strengths that cater to different types of data workloads.
Data parallel architectures shine when large datasets need to be processed in parallel. This model divides data into smaller chunks, each processed independently but in the same manner on different workers or nodes. Apache Spark, a well-known data processing framework, uses this architecture. Spark's resilience, capacity for handling vast amounts of data, and ability to perform complex transformations make it a favorite in big data landscapes. Bytewax also follows this model with the same transformations happening on each worker, but on different data.
On the other hand, task parallel architectures, as exemplified by Apache Flink and Dask, focus on executing different tasks concurrently across distributed systems. This approach is particularly effective for workflows with a wide variety of tasks that can be performed independently or have complex dependencies. Flink's stream-first philosophy provides robustness for real-time processing tasks, while Dask's flexibility makes it a great choice for parallel computing tasks in Python environments.
Finally, the agent actor architecture, the foundation for Ray, presents a flexible and robust model for handling complex, stateful, and concurrent computations. In this model, "actors" encapsulate state and behavior, communicating through message passing. Ray's ability to scale from a single node to a large cluster makes it a popular choice for machine learning tasks.
As we delve deeper into these architectures in the following sections, we will explore their pros and cons, use cases, and the unique features offered by Spark, Flink, Dask, Ray, and Bytewax. By understanding these architectures, you'll be better equipped to select the right framework for your next data processing venture. Stay tuned!
Data Parallel Architectures
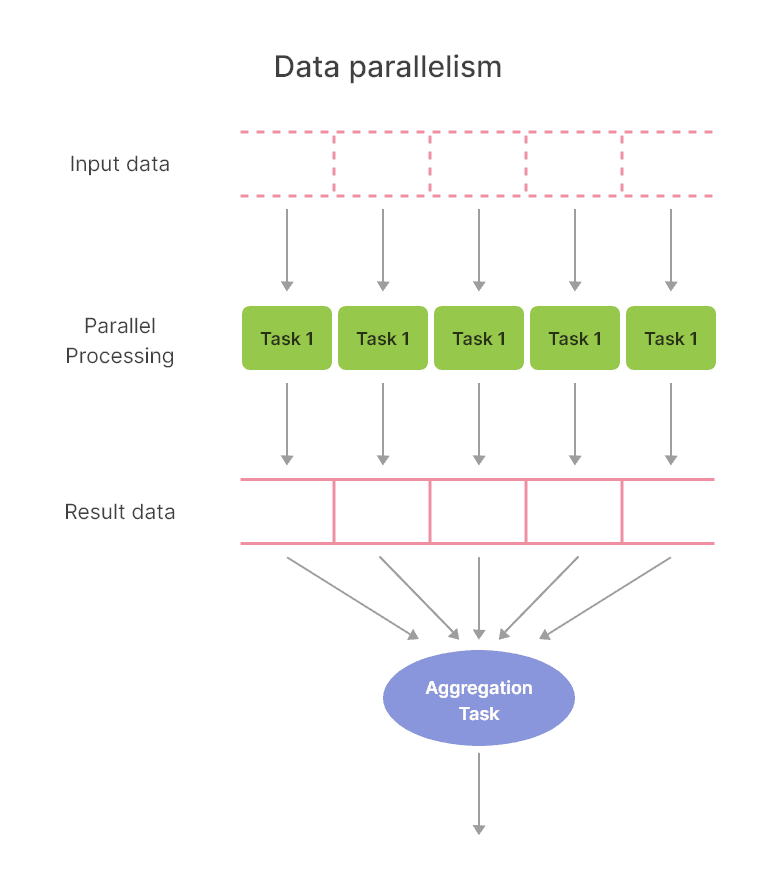
Data parallelism is a form of parallelization that distributes the data across different nodes, which operate independently of each other. Each node applies the same operation on its allocated subset of data. This approach is particularly effective when dealing with large datasets where the task can be divided and executed simultaneously, reducing computational time significantly.
The Mechanism
In data parallel architectures, the dataset is split into smaller, more manageable chunks, or partitions. Each partition is processed independently by separate tasks running the same operation. This distribution is done in a way that each task operates on a different core or processor, enabling high-level parallel computation.
Advantages
- Scalability: Data parallel architectures are designed to handle large volumes of data. As data grows, you can simply add more nodes to the system to maintain performance.
- Performance: The ability to perform computations in parallel leads to significant speedups, particularly for large datasets and computationally intensive operations. Due to the fact that data does not move around as often to different workers, there can also be a performance gain.
- Simplicity: Since the same operation is applied to each partition, this model is relatively simple to understand and implement.
Disadvantages
- Communication Overhead: The nodes need to communicate with each other to synchronize and aggregate results, which can add overhead, particularly for large numbers of nodes.
- Limited Use Cases: Data parallelism works best when the same operation can be applied to all data partitions. It's less suitable for tasks that require complex interdependencies or shared state across tasks. As we have seen with spark though, this is not entirely true.
Best Use Cases
Data parallel architectures excel in situations where large volumes of data need to be processed quickly and in a similar manner. Some of the best use cases include:
- Batch Processing: In scenarios where large amounts of data need to be processed all at once, data parallel architectures shine. This is a common use case in big data analytics, where massive datasets are processed in batch jobs.
- Machine Learning: Many machine learning algorithms, especially those that involve matrix operations, can be easily parallelized. For instance, in the training phase of a neural network, the weights of the neurons are updated based on the error. This operation can be done in parallel for each layer, making data parallelism a great fit.
- High Partitioned Input and Output: Data parallel frameworks excel when the input and output are partitioned in such a way that the workers can evenly match the partitions and redistribution of the data is limited.
- Stream Processing: The data parallelism approach is well suited to stream processing where the same operation is happening to data in real-time.
Apache Spark, a notable data parallel framework, is widely used in big data analytics for tasks like ETL (Extract, Transform, Load), predictive analytics, and data mining. It's particularly known for its ability to perform complex data transformations and aggregations across large datasets.
Bytewax is known for its ability to handle large continuos streams of data and do complex transformations on them in real-time.
As we continue our exploration into the different data processing architectures, we'll see how other approaches handle tasks that might not be as suitable for data parallel processing.
Task Parallel Architectures: Unlocking Concurrent Processing
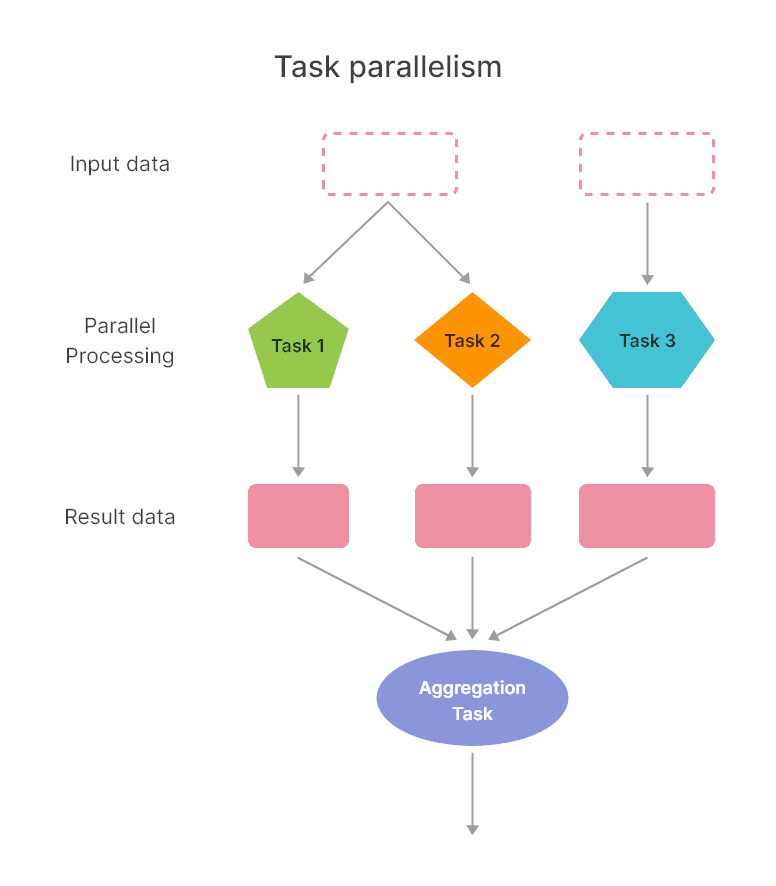 Task parallelism, also known as function parallelism, is an architectural approach that focuses on distributing tasks—rather than data—across different processing units. Each of these tasks can be a separate function or a method operating on different data or performing different computations. This type of parallelism is a great fit for problems where different operations can be performed concurrently on the same or different data.
Task parallelism, also known as function parallelism, is an architectural approach that focuses on distributing tasks—rather than data—across different processing units. Each of these tasks can be a separate function or a method operating on different data or performing different computations. This type of parallelism is a great fit for problems where different operations can be performed concurrently on the same or different data.
The Mechanism
In a task parallel model, the focus is on concurrent execution of many different tasks that are part of a larger computation. These tasks can be independent, or they can have defined dependencies and need to be executed in a certain order. The tasks are scheduled and dispatched to different processors in the system, enabling parallel execution.
Advantages
- Diverse Workloads: Task parallel architectures excel in scenarios where the problem can be broken down into a variety of tasks that can be executed in parallel.
- Flexibility: Since tasks don't necessarily need to operate on the same data or perform the same operation, this model offers a high level of flexibility.
- Efficiency: Task parallelism can lead to improved resource utilization, as tasks can be scheduled to keep all processors busy.
Disadvantages
- Complexity: Managing and scheduling tasks, especially when there are dependencies, can add complexity to the system.
- Inter-task Communication: Tasks often need to communicate with each other to synchronize or to pass data, which can lead to overhead and can be a challenge for performance.
Best Use Cases
Task parallel architectures are best suited to problems that can be broken down into discrete tasks that can run concurrently. This includes:
- Complex Computations: Scenarios where a complex problem can be broken down into a number of separate tasks, such as simulations or optimization problems, are a good fit for task parallel architectures.
- Real-Time Processing On Diverse Datasets: Task parallel architectures are often used in systems that require real-time processing and low latency, such as stream processing systems.
Apache Flink is an excellent example of a system that uses a task parallel architecture. Flink is designed for stream processing, where real-time results are of utmost importance. It breaks down stream processing into a number of tasks that can be executed in parallel, providing low-latency and high-throughput processing of data streams.
Similarly, Dask is a flexible library for parallel computing in Python that uses task scheduling for complex computations. Dask allows you to parallelize and distribute computation by breaking it down into smaller tasks, making it a popular choice for tasks that go beyond the capabilities of typical data parallel tools.
In the next section, we'll explore the agent actor model, a different approach to managing concurrency and state that opens up new possibilities for parallel computation.
Agent Actor Architectures: Pioneering Concurrent Computations
Agent actor architectures introduce a fundamentally different approach to handle parallel computations, particularly for problems that involve complex, stateful computations. This approach build on task parallelism with the addition of an actor. An actor is a computational entity that, in response to a message it receives, can concurrently: make local decisions, create more actors, send more messages, and determine how to respond to the next message received. The agents are then similar to task distributed or functional distributed systems.
The Mechanism
In the agent actor model, actors are the universal primitives of concurrent computation. Upon receiving a message, an actor can change its local state, send messages to other actors, or create new actors. Actors encapsulate their state, avoiding common pitfalls of multithreaded programming such as race conditions. Actor systems are inherently message-driven and can be distributed across many nodes, making them highly scalable.
Advantages
- Concurrent State Management: Actors provide a safe way to handle mutable state in a concurrent system. Since each actor processes messages sequentially and has isolated state, there is no need for locks or other synchronization mechanisms.
- Scalability: Actor systems are inherently distributed and can easily scale out across many nodes.
- Fault Tolerance: Actor systems can be designed to be resilient with self-healing capabilities. If an actor fails, it can be restarted, and messages it was processing can be redirected to other actors.
Disadvantages
- Complexity: Building systems with the actor model can be more complex than traditional paradigms due to the asynchronous and distributed nature of actors.
- Message Overhead: Communication between actors is done with messages, which can lead to overhead, especially in systems with a large number of actors.
Best Use Cases
Agent actor architectures are best suited for problems that involve complex, stateful computations and require high levels of concurrency. This includes:
- Real-time Systems: The actor model is well suited for real-time systems where you need to process high volumes of data concurrently, such as trading systems or real-time analytics.
- Distributed Systems: The actor model can be a good fit for building distributed systems where you need to manage state across multiple nodes, like IoT systems or multiplayer online games.
Ray is an example of a system that employs the actor model. It was designed to scale Python applications from a single node to a large cluster, and it's commonly used for machine learning tasks, which often require complex, stateful computations.
As we've seen, the landscape of data processing architectures is rich and diverse, with each model offering unique strengths and potential challenges. Whether it's data parallel, task parallel, or agent actor, the choice of architecture will depend largely on the nature of the data workload and the specific requirements of the system you're building.




Top comments (0)