
Spring Batch is a Lightweight, compressive batch framework which is used to perform ETL tasks on bulk of data easily.
E- Extract
T-Transform
L-Load
It’s not a scheduler, but it is intended to work with scheduler. It can be used to load data from file to database , or read data from database, process it to give a different output and store them in a separate database. Basically it’s for large datasets or high volume of data.
Let’s dive into spring batch architecture.It mainly has 3 components.
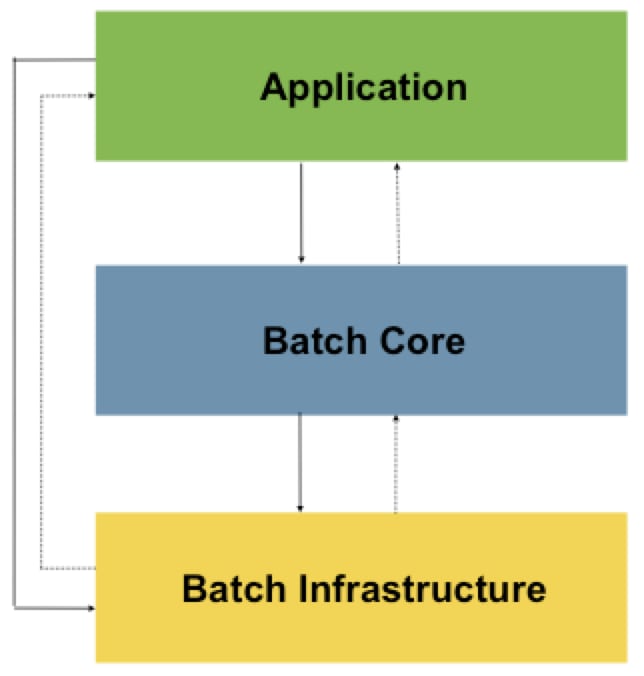
Application — It contains batch jobs, code written by developers, APIS, etc.
Batch Core — It contains the core classes needed to launch and control the batch job i.e JobLauncher, Job, Step, JobExecution etc.
Infrastructure — It contains readers and writers, services which will be used by developers to code the batch job i.e ItemReader, ItemWriter, ItemProcessor etc.
Batch Processing Strategies
1.Normal processing in batch window
It is for simple batch processors. When application is updating the data, no other batch jobs or online users should be able to access it. This is the assumption. Single commit can be done at the end of the batch job.
2. Concurrent batch/Online Processing
This is used in cases where both the batch job and online users can use the data simultaneously. But the online user should not lock the data. Physical locking can be minimised by optimistic Locking and pessimistic locking approach. Commit is done at the end of few transactions each. Thus at a time only a small partition of data might not be available for other processes.
Optimistic locking
The usecase is at a given point the probability that both app and online users are updating the data is very less. Thus timestamp column is added into the table. When starting the batch job, it is noted down and while updating the data after processing it ,it checks the same timestamp in the where clause. It updates the data only if both the timestamp match. If the timestamp doesn’t match, it won’t update the data.
eg: UPDATE TABLE T1 SET C1 = ABC WHERE TIMESTAMP =T1
where T1 is timestamp which was read initially before starting the processing.
_Pessimistic locking
_
The usecase for it is when it’s highly likely that both app and online users are updating data at the same time. Physical/ logical locks need to be retrieved in these cases. Separate lock column can be maintained where when one user access the data, the lock is set true for the record and if some other user tries to access the same data at same time, he/she won’t be able to access it because of the lock.
3. Parallel Processing
It refers to multiple batch jobs running in parallel. Thus less time consumed. It can’t share the resources between each other[ 2 jobs running in parallel]. Data partitioning can be an option here. We can use multiple threads to process in parallel.We can also use control table which contains details of all shared resource and mentions if it is being used by some other application. Thus the same resource won’t be processed multiple times.
Cons — Control table can itself become a critical resource
4.Partitioning
It allows multiple versions of a batch application to run concurrently. Reduces elapsed time taken by long batch jobs. Database data/input data will be split, which allows the application to work on each data set independently.
Partioning != partioning the db [not necessarily]
Application should be flexible enough to decide the number of partitions. Automatic and user controlled config should can also be considered. It depends on the application developer writing the code.
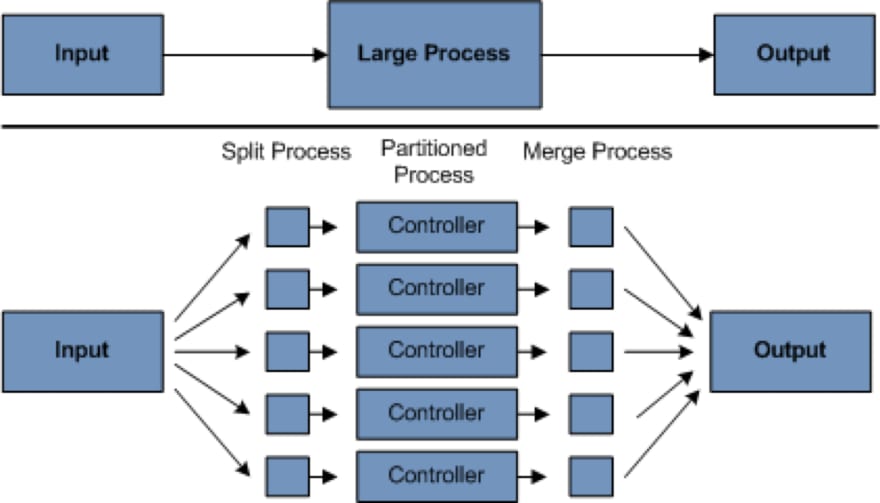
Here in this diagram you can see that the input in split into multiple parts and is given to the controller. Thus these can run in parallel and the results are then merged to get the final output.
These are few partitioning approaches as well.
- Fixed and even break up of record set where the input data will be split evenly thus each job batch will get same number of records.
- Break up by a key column where the data will be split based on a column be it a date range or some id.
- Break up by Views refers to breaking the record set into views.
- Extract table to a flat file refers to extracting table records and exporting to a flat file based on size of file.
If you prefer watching video , you can follow this link🦋.
So now you know what to do. If you found this useful, you know what to do now. Hit that ❤️ button and follow me to get more articles and tutorials on your feed.❤❤






Top comments (0)