
Code Review Doctor is a static analysis tool integrated into GitHub. Normally it suggests fixes in PRs - but during integration testing of new checks we run the checks against 666 open source GitHub repositories to ensure the quality of the checks (including weeding out false positives before our users see them).
During the integration testing this week we found 24 bugs in big open source projects, which we raised and helped fix over the course of a very busy day of managing tickets and PRs. Here's the most interesting ones:
- Sentry
- Tensorflow
- Pydata's xarray
- Google's V8
- PyTorch
- PyTorch again
- Pytorch the third
- rapidpro
- django-colorfield
- django-helpdesk
The checks
A common thread is all the issues relate to commas: either too many commas or too few commas:
Too many commas
Typo accidentally adding a comma to end of a value, turning it into a tuple

Too few commas
Accidentally missed comma from string in list/tuple/set, resulting in unwanted string concatenation.
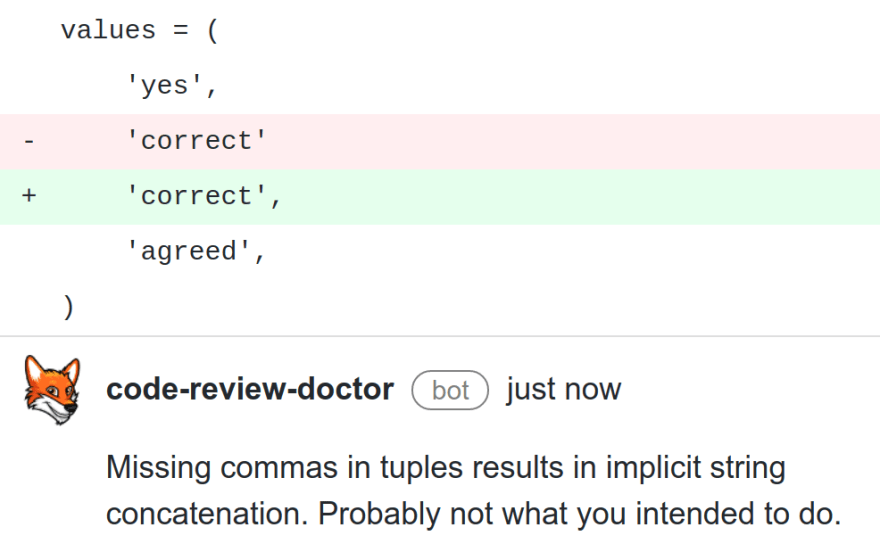
Accidentally missed comma from 1 element tuple, making it a str instead of a tuple.

The main difficult bit with this check was reducing false positives. Syntactically there is no difference between a missing comma in a list and implicit string concatenation done on purpose. Indeed, when we first wrote the checker we found that 95% of the "problems" were actually false positives: there are perfectly cromulent reasons a developer would do implicit string concatenation spanning multiple lines:
- User agent string
- file path
- URL
- CSV file contents
- Very long message
- HTML
- Sha hash
- SQL
- JSON
After checking the 666 codebases we understood the key drivers of false positives and added allowances for implicit string concatenation for those types of data. After we gave allowances for these valid reasons to do implicit string concatenation the false positive rate went down to negligible non-annoying level.
How common?
After running those three new checkers against the 666 repositories we found that almost 5% of repositories had one of these three bugs, and most of them were "big" well known and well-used projects with many contributors and very robust code review processes. This highlights that for manual processes like code review to detect 100% of bugs 100% of the time then 100% of humans must perform 100% perfectly during code review 100% of the time. See the cognitive dissonance? We do code review because we expect human error when writing the code, but then expect no human error when reviewing the code. There are just some things a human can do well, and there are some things a bot can do better. Noticing commas in the wrong place is one of those things. For example:

Can you see the problem? Line 572 has implicit string concatenation!
It's missing a commas, so should be
'"()<>[]:,;@\\"!#$%&\'-/=?^_{}| ~.a"@example.org', '" "@example.org',
I'm not surprised that was missed by a human!
The impact
Some of the missing commas have little to no impact, but some are rather impactful. Take the Sentry one as an example:
Notice the missing comma in the list:

There is a comma missing between "releases" and "discover" resulting in the two being implicitly concatenated together to form "releasesdiscover".
The impact is the test requesting "/releasesdiscover" which does not exist, and so instead of "/releases" and "/discover" being tested, instead the 404 page is tested. That means for all we know, the organisation switcher on /releases and /discover could be broken. There is some poor dev out there maintaining the organisation switcher relying on this test and using it as a quality gate to give them confidence they have not broken the product but the test is not really working. It's these kind of things that can harm a nights sleep! It ain't what you don't know that gets you into trouble. It's what you know for sure that just ain't so.
Protecting your codebase
Add Code Review Doctor to GitHub and avoid problems like these being merged as Code Review Doctor will automatically suggest the fix for these kind of issues right inside your PR.






Top comments (0)