
If you are familiar with Docker, Terraform, and the most popular CI platforms (eg: CircleCI, Codeship), you already know the power behind Declarative DevOps. These technologies hide an incredible amount of reuse and detail by supporting simple structured syntax in an easy to create and read YAML file. Need an Ubuntu image? Done. How about a MongoDB instance? You got it. Need to do something completely custom? Got for it.

Automation Makes DevOps Go
I suggest taking a quick read of an article by BMC titled Automate Cloud & DevOps Initiatives Across All Phases. If automation is the orchestration of DevOps, declarative DevOps is its sheet music. It provides a readable format to play out the intent of the composer. Importantly, it simplifies the learning curve of using many traditional tools in the chain. Sure, it takes time to set up all the distinct and disparate pieces, but once it is done, it hums along rather well uninterrupted. It serves the project’s needs. My CI platform orchestrates things and has its own declarative syntax and requirements. Within it, I am able to do custom things to build and test my project, then invoke both my Docker and Terraform declarative requirements.
However, from project to project, nothing is exactly the same. For example, Terraform changes due to cloud provider, CI changes due to tech stack selection, and Docker changes as well. Different URLs and security credentials to connect to certain things, optional use of an artifact repository (like JFrog or Sonatype). The list goes on with a great # of permutations.
A DevOps Project Shortcoming
Again, declarative DevOps it to make life easier. Repeatable, predictable, and fast. Try something. Don’t like it? Make a quick change and try again. It is now a vital part of my development process. I have no interest in returning to how things used to be.
But I don’t get to enjoy the fullest benefits of DevOps and automation without a project. It’s like a factory waiting to receive the raw materials needed to make it actually be a factory. I define a project as a “meaningful code base” along with all the scaffolding required to make the machines in the factory run at least once. Many IDEs and CI platforms produce a simple tech stack specific “Hello World” app and some stubbed out/empty files to get the ball rolling. Forget starting with a fully functioning app. No ready to go Dockerfile, CI YAML file, or Terraform file. These platforms simply do not know enough about a projects requirements to produce a meaningful project.
Before the project starts and hands go to keyboard, there are quite a few things I already know. I “mostly” have my business requirements (these never change, do they…). I know the tech stack I need to leverage. I am directed to use CI platform ABC and cloud vendor XYZ. Finally, I need a Docker image orchestrated on a remote Kubernetes cluster.
If I can describe the project’s requirements then I would like to declare those requirements.
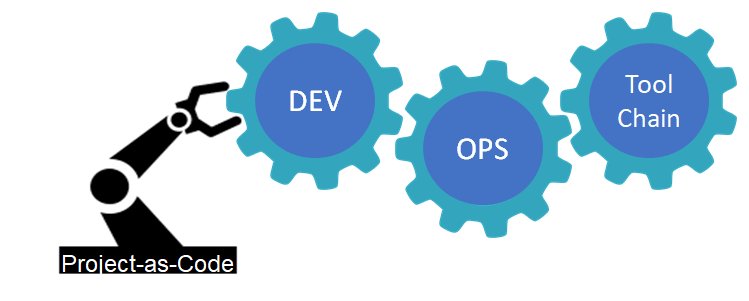
Automating the Automation
We have Container-as-Code with Docker, Orchestration-as-Code with Kubernetes, Infrastructure-as-Code with Terraform, and Pipeline-as-Code with many CI platforms. So why not Project-as-Code?
A single YAML file that turns project declarations into business contextual tech stack specific source code along with CI/container/orchestration config files. That’s a mouthful but worth considering. By infusing the business context it means no more “Hello World”. Instead, start with a deployable application with (likely) 10s to 100s of 1000s of lines of stuff I need and honestly no longer want to write so long as I can edit as required.
Example Project-as-Code YAML
app:
techstack:
id: Angular7MongoDB # options: ASPNETCore, LambdaNoSQL, Lambda, Angular7MongoDB, Django, GoogleFunctions
# SparkMicroWeb, SpringCore, SpringMongoDB, Struts2, Apollo
# To see the list of available tech stacks on a realMethods instance using command:
# realmethods_cli stack_list --output pretty
model:
identifier: shopping-cart.sql # options: Unique id of an existing model or
# full or relative path to a model file of a supported type
# model types: UML, Eclipse Modeling Framework, JSON, SQL Script, JAR, EAR
# To see the list of available model on a realMethods instance using command:
# realmethods_cli model_list --output pretty
#
#
# DevOps Project Creation Options
#
options:
#
# CI/CD parameters
#
cicd:
platform: circleci # options: codeship, circleci,
# jenkins, azure, aws, gitlab,
# bitbucket, buddy, semaphore
AES key: # codeship project key; ex: XKyy2IDcSptIIvMY8KLMVMcxVs+ZK6AyNu1B4Wu1DPY=
#
# Application parameters
#
application:
name: angular7demo
description: Demo Angular7 application generated by realMethods
author: Dev Team
email: xxxx.xxxxxxxxx@xxxxxxxx.com
application logo URL: ./img/turnstone.biologics.png
company name: Turnstone Biologics
version: 0.0.1
#
# Docker parameters
#
docker:
userName: your_docker_user_name
password: your_docker_password
orgName: your_dockerorg_name
repo: your_repository
tag: latest
#
# Git repository parameters
#
git:
name: GitAngularSetting # an arbitrary name
username: your_git_user_name
password: your_git_password:
repository: your_git_repo_name
tag: latest
host: bitbucket.org
#
# HashiCorp Terraform parameters
#
terraform:
inUse: true
provider: aws # options: aws, google, azure, nutanix
region: us-east-1 # options: any cloud provider region
ssh-fingerprint: xxxxxxxxxxxxxxxxx # required by CircleCI for SSH
#
# AWS parameters
#
aws:
key-pair-name: xxxxxxxxxxxx
vpc: xxxxxxxxxxxxx
ec2-instance-type: t2.medium # options: any AWS instance type
access-key: ASSIGN__ON_CICD_PLATFORM_AS_ENV_VARS
secret-key: ASSIGN__ON_CICD_PLATFORM_AS_ENV_VARS
#
# Nutanix parameters
#
nutanix:
inUse: false
userName: xxxxxxxxxxxxxxxxxxxxxxxxx
password: xxxxxxxxxxxxxx
endpoint: xxx.xxx.xxx.xxx
insecure: true
port: xxxxx
clusterId: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
email: dev@realmethods.com
vmUserName: xxxxxxxxxxx
vmPassword: xxxxxxxxxxx
vmHost: xxx.xxx.xxx.3xxx
vmOS: linux # options linux, windows - windows not yet supported
#
# Kubernetes parameters: If not in use, and Terraform
# is in use, physical infrastructure
# will be provisioned on the provider
#
kubernetes:
inUse: true
host: https://xxx.xxx.xxx.xxx
project: xxxxxxxxxxx # assigned project name
region: us-central1-a # options: any provider region
hostTarget: google # option: google, aws, azure, nutanix
username: admin
password: 5UhfcIPAPsiPXklT # generic value
exposeAsService: true
serviceType: LoadBalancer # options: LoadBalancer, NodePort, ClusterIP
useSessionAffinity: true
#
# Artifact repository for build dependencies and binaries
#
artifact-repo:
inUse: false
type: nexus # options: nexus, jfrog
userName: xxxxxxx
password: xxxxxxxx
email: xxxx.xxxxxx@xxxxxxx.com
repoUrl: http://xxx.xxx.xxx.xxx:8081/repository/npm-public
#
# MongoDB parameters - defaults to a local accessible instance
#
# If Terraform is in use, will attempt to instantiate a MongoDB instance via Docker image,
# and use the instance IP address when binding the lambda functions
#
mongodb:
server address: localhost:27017
database name: angular7demo
search size: 10
default collection name: default_collection
auto-increment id name: _id
auto-increment seq name: seq
mongooseHost: http://localhost
mongoosePort: 4000
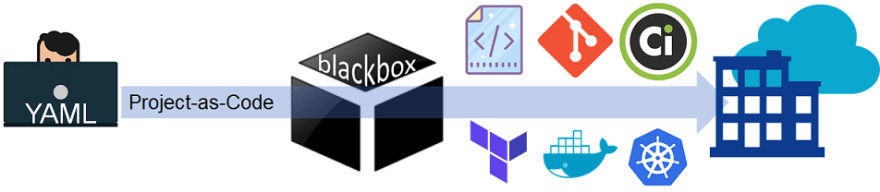
Conclusion
Project-as-Code moves the project starting line out and the overall timeline in. It gives (new) purpose to Sprint Zero. The upfront work required to get it setup (often less than a day) pays massive dividends in saving weeks of time to the first meaningful project commit. Every project has certain things that are more fun to work on than others. I prefer to automate the mundane and predictable (although much needed) to focus on more important dev. You can view a sample generated project here to get an idea of what is possible from a single Project-as-Code YAML file.





Top comments (0)