
Recently, we covered the top enterprise serverless use cases for AWS Lambda. To refresh our memory, according to the CNCF (Cloud Native Computing Foundation), most commonly AWS Lambda is used for REST APIs, multimedia/image processing, CRON jobs, and stream processing. Today I'd like to cover some more complex ways some of our enterprise customers use Lambdas.
During the AWS re:Invent back in 2017 Raghu Chandra, the Global Delivery Leader for Cognizant Technology Solutions presented the six most popular use cases they implemented with their customers over the years. We're going to look into three of them.

Data lakes
Today, many companies are implementing AWS just for the data lake situation. Amazon S3 provides an optimal foundation for a data lake because of its virtually unlimited scalability.
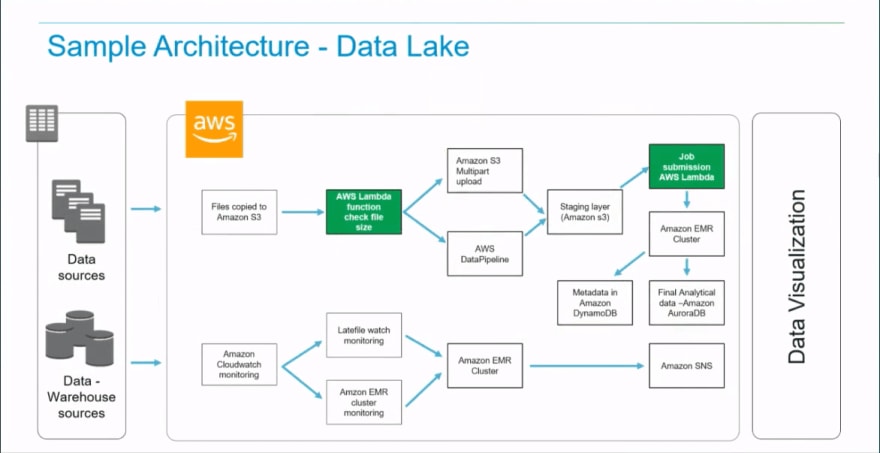
Let's look into the sample data lake's architecture above. When copying the files to the S3 from the on-premises data sources, you would want to set up a Lambda function to check the file size that has just come in before sending it to the staging layer through either DataPipeline or S3 upload. The second lambda will be used to bring up the EMR clusters to process the data to do the normalization and ETL (extract, transform, load) before we persist that into a DynamoDB or AuroraDB.
So a very classic use case -- two lambda functions in a data lake scenario to detect the source file and to work with the EMR clusters or any other ETL jobs that we want to invoke to process the data.
Microservices
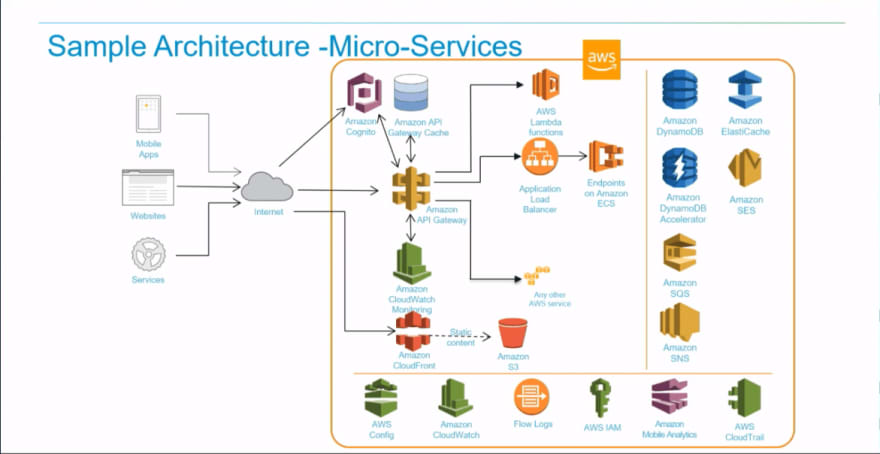
The second sample architectural pattern for enterprises is microservices. Depending on the certain use case, the services can be short running or long running. For a long-running service, you can deploy it onto a container on ECS but for a short running service, you can use the Lambda through an API Gateway. The REST API endpoints can be managed by API Gateway which can invoke those services on Lambda.
Disaster recovery
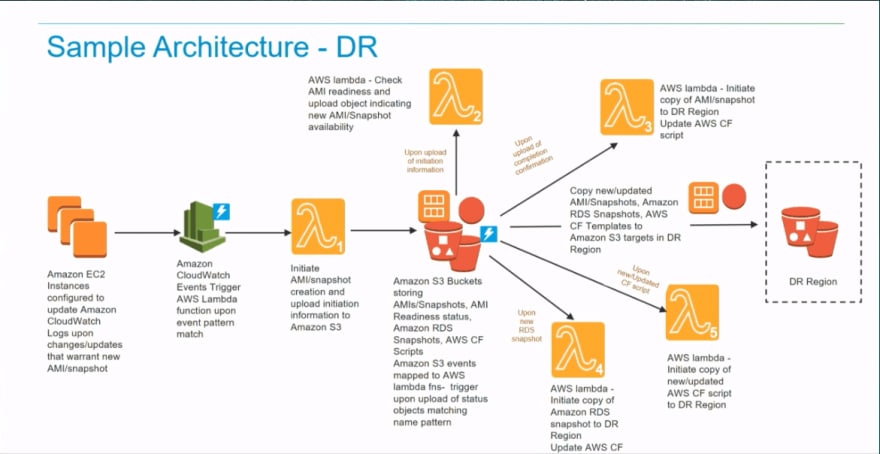
There are several ways to leverage AWS Lambda to construct a DR plan. Often when making changes to primary data center configuration like changing code, jar files or database tables it's recommended to do a backup and restore. Lambdas can be used to automate tasks like EBS snapshot and AMI creation to backup your resources to S3 when configuring EC2 instances. As in every disaster recovery scenario, you would have a primary and a secondary data center, so once the new code is available in S3 you would want to have a Lambda function to copy that code into a secondary data center and to invoke the CloudFormation scripts build the AMI and deploy it on the secondary data center.
So in the fewest possible words, lambda is used to listen to the events of changes in code (in our use case S3) and in a database and to sync both with the secondary data center.
Conclusion
As we know, serverless can never replace the whole stack when dealing with larger enterprises -- it just isn't reasonable, but it can bring a whole lot of value when combining Lambdas and other serverless services with the infrastructure in the right way. To make sure these Lambdas won't fail when doing a critical job, Dashbird can help you to ensure reliability by providing end to end observability into your stack.





Top comments (0)