Introduction
In healthcare, developing accurate models can be difficult due to the low amount of data and privacy constraints. Federated learning (FL) addresses this by allowing data analytics and modeling to take place without sharing data outside of the premises.
As data science projects become more complex, Machine Learning Operations (MLOps) have become essential for improving the efficiency, quality, and speed of machine learning models. However, applying MLOps to FL comes with new challenges, such as privacy and security, data heterogeneity, communication, and reproducibility.
In this blog post, we'll explore how NVFlare and MLFlow were used to track experiments in a federated learning setup while applying MLOps best practices.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Healthcare use case
This is a hypothetical use case where a Research Centre is trying to develop a coronary disease prediction model, for this, it trains on data from three independent hospitals, the distribution of patients in each hospital is different, and unbalanced.

The architecture of our framework is composed of one Research Centre (server) where all the research orchestration will take place, and three Hospitals (clients) that contain the patient's private data on which the model will train locally.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Challenges
The successful implementation of a federated learning project can be challenging, and our project was no exception. We encountered several obstacles that required innovative solutions. Some of the primary challenges we faced are:
- Technology: Federated learning technology is still experimental and developing, resulting in a lack of standardization and best practices for building an end-to-end scalable solution. Although several promising solutions can be implemented, time constraints must be considered.
- Privacy and Security: Sensitive patient data is involved, and it is essential to protect it throughout the entire process. Strict access policies and communications must be implemented to ensure that only authorized entities can access it, creating a more complex and restrictive environment to work in.
- Data Heterogeneity: The data of different hospitals may follow different distributions, which can make the global training harder. Also, data from various hospitals may be in different formats and sizes, making it challenging to ensure consistency and comparability across datasets. Data quality and cleaning must be configured in a central repository and implemented locally.
- Data Exploration: Due to privacy concerns, data can only be explored globally by using aggregated information about all the samples. Noise is added to avoid possible data leaking. Reproducibility and Experimentation: The distributed nature of federated learning makes it challenging to track local experiments and link them to the general parameters of each run. NV Flare and MLflow were used to track changes to code and configurations to ensure reproducibility and experimentation.
- Model and Validation Aggregation: The models trained on client nodes need to be aggregated to create a global model, which can be challenging when dealing with different architectures, parameters, and hyper-parameters. NV Flare solves this problem by using a centralized configuration file.
- Trust and teamwork: Collaboration between teams is critical for the successful implementation of federated learning, as no single entity has complete control over all the resources required to perform an experiment. <!--kg-card-end: markdown--><!--kg-card-begin: markdown--> ## Federated learning Framework
We decided to use NVFlare and MLFlow due to the fact that they are widely used and they both have good documentation.
- NVIDIA Federated Learning Application Runtime Environment (NVFlare) is a domain-agnostic, open-source SDK/platform designed to address the challenges of Federated Learning. It supports different ML/DL workflows (PyTorch, TensorFlow, Scikit-learn, XGBoost, etc.); It is a combination of two algorithms, the Nesterov's Accelerated Gradient Descent (NAG) algorithm and the Variance-Reduced Stochastic Gradient Descent (VR-SGD) algorithm. The NAG algorithm is used to reduce the training convergence time, while the VR-SGD algorithm is used to reduce the variance of the gradients across the different data sources.
- ML Flow is an open-source platform for managing the complete machine learning lifecycle, including experimentation, reproducibility, and deployment. It allows us to track experiments, reproduce results, and manage models in a consistent and scalable way. <!--kg-card-end: markdown-->

The experiment metrics and parameters are tracked by ML Flow while the FL Process is running.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
NV Flare features
The current NVFlare project has 3 main features which can be executed as jobs:
- Federated statistics
- Federated model training
- Federated model explainability <!--kg-card-end: markdown--><!--kg-card-begin: markdown--> #### Federated Statistics
Data analytics and explorative statistics is a crucial part for every data related project. Due to the sensitive nature of medical data we can’t simply combine datasets of different hospitals in one place to explore the data. The federated statistics feature is here to give some insights about the data of all hospitals without sharing individual data points.
NVIDIA FLARE built-in federated statistics operator was used to generate global statistics based on the local client side statistics
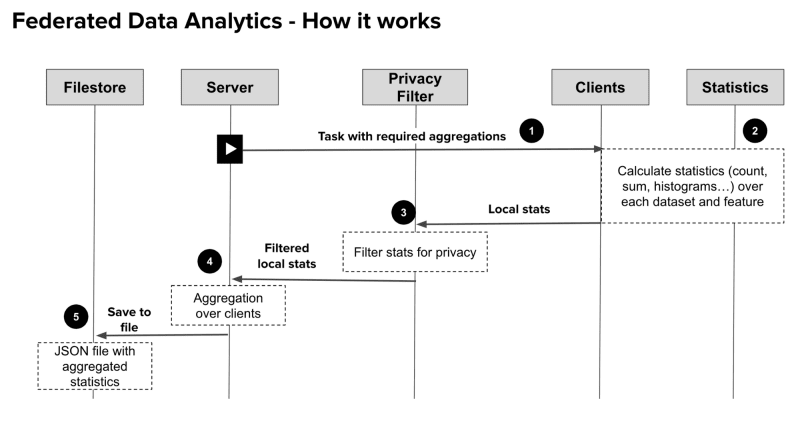
The steps for a federated statistics job are the following:
- The server assigns a task to the client specifying which stats need to be calculated with additional information (ex. number of bins the histograms will contain).
- The client calculates the desired statistics on their data. In our case, the count, mean, sum standard deviation and histogram for every feature is computed.
- These local statistics go through a privacy filter configured by the hospitals. These filters ensure the security rules for data privacy. E.g. Histogram bins containing only 1 data point are removed as these could help retrieve individual data points.
- The statistics of each individual hospital are aggregated to obtain the global statistics.
- Finally the server stores this data into a JSON file that is stored in the research center (Server node). This file is used later on to update the SQL database
Users can access the aggregated information through a user-friendly dashboard, which is explained at the end of this blog post. The dashboard provides an intuitive interface for users to explore and interpret their local model as well as the federated model, enabling efficient analysis and informed decision-making.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Federated model training
This is the main feature of the project. Each one of the hospitals owns a specific local dataset which cannot be explicitly shared. Thus, the datasets cannot be simply combined in order to train a single global model. We tackle this issue using Federated Learning, training local models for each hospital and aggregating their weights into a global model. The steps can be described as following:
- Initialize the global and local models
- For each training epoch: a. Update the local models’ weights according to each local dataset b. Aggregate the local weights according to the aggregation strategy c. Update the global model and reinitialize each local model with the global weights <!--kg-card-end: markdown-->

The model currently in use is SGD Linear Regression Classifier of scikit-learn. The same model is used for all the global and local instances. The training method is Batch Gradient Descent, which means that for each epoch the local weights are updated according to only 1 training sample. There seems to be no mechanism in scikit-learn to do mini batch gradient descent, which means updating the weights using multiple samples for each epoch.
The weights aggregation method that we currently use is FedAvg, which is the pioneering FL algorithm. The aggregation is performed in a weighted averaging manner that makes nodes with more data having more weight in the newly aggregated model.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Federated model explainability
Model explainability is often a very desirable feature, especially in medical applications. In our case we want to observe the importance of each input feature of the model. The current version of NVFlare doesn’t provide the feature of model explainability, so it had to be developed by us.
The two main requirements are for this feature to be:
- Model agnostic: Since the classifier will change as the project evolves we avoided model specific methods, such as visualizing the Logistic Regression weights.
- Handling the data in a Federated way: Explainability methods often need to be tuned or tested on a specific dataset. Because of the sensitive nature of medical data we can’t simply combine datasets of different hospitals.
The explainability method that we used for this use case is SHAP.
SHAP is a perturbation based approach to compute attribution, based on the concept of Shapley Values from cooperative game theory. This method involves taking random permutations of the input features to calculate their effect on the model output. This is desirable because we want our model to be treated as a black box, without paying attention to the internal model workings.
In our case, where we need a global explainer, SHAP builds a weighted linear regression by using the data and predictions. It computes the variable importance values based on the Shapley values from game theory, and the coefficients from a local linear regression.
In a nutshell, this feature uses SHAP to calculate the local importance values, and then aggregates them globally using NVFlare. In a Federated Learning setting, SHAP needs to be tuned and evaluated on the hospitals’ data, while avoiding the combination of all the hospital data in one place.
Our code computes the importance values in the hospital nodes, using the global model and the local data. These importance values are sent to the main node, where they are averaged. The communication between the main node and the hospital nodes is handled by NVFlare, as in the Federated Statistics module.
The feature importance plot, just like the Federated Statistics plots, is integrated into the project’s dashboard.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Execution of the jobs
The current setup uses configuration YAML files to set the job arguments. Starting from a basic default file, new YAMLs are created for each one of the 3 different jobs. Detailed execution steps can be found in the NVFlare README file of the project.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Future contributions
There are additional ideas that would be impactful for the project if implemented:
K-fold Cross Validation
Currently we can’t control the training/validation pipeline enough, in order to perform K-fold CV. Developing this feature would be useful, especially in similar cases of data scarcity.
At the moment, validation is done on the hold-out validation set of each hospital. For each hospital we apply a 60%, 20%, 20% split for training, validation and testing.
As we described above, in the end of each training epoch the global model weights are sent to every hospital’s local model. Before moving to the next epoch, each hospital locally runs validation on its own validation set. All the validation metrics are logged through MLFlow.
Further model exploration
There definitely are more models that could be used in the experimentation phase. Tree-based models could be the next step, since they are extensively covered by scikit-learn. Further development for their weight aggregation would be needed as well.
Aggregation strategy exploration
FedAvg has a naive form of aggregation that may lead to suboptimal solutions. The data samples on each participating node are usually not independent and identically distributed (non-IID), which leads to serious statistical heterogeneity challenges. In this case we observe the phenomenon of “client-drift”, where local client models move away from globally optimal models.
This is why experimenting with additional methods, such as Scaffold and FedOpt , would be valuable. These methods improve the convergence during FL optimization, resulting in better model performance and shorter training times.
Scaffold tries to tackle the issue of “client-drift” when the data is heterogeneous (non-IID). The new proposed algorithm uses control variates (variance reduction) to correct for the “client-drift” in its local updates.
FedOpt focuses on adaptive optimization for FL. Federated versions of adaptive optimizers, such as Adam and AdaGrad, are proposed in order to improve convergence. The FedOpt paper claims significantly better results than Scaffold and FedAvg in FL training.
The above methods would need to be developed in PyTorch, since scikit-learn doesn’t allow a more low-level interaction with the model’s optimizer.
Inference
After the Federated Training job has been completed, the final global model is saved. To make this model useful for the hospitals we have to think about how the inference part will take place.
The simplest solution would be just providing the global model file, for the hospitals to use individually. Each hospital would download the global model locally, and their dedicated hospital Engineers would create a local API.
What we propose, though, is the development of a global framework, provided from the research center to the hospitals.This API would enable every hospital to load the remote global model, which has already been trained, and run predictions locally using the provided methods.
In this way, we ensure that data privacy is maintained, since patient data is never sent outside the hospital. Furthermore, each hospital doesn’t need a significant engineering team, since the framework has already been developed by the research center.
Further exploration of NVFlare explainability bug
In the final stages of testing the Federated Explainability feature we noticed that NVFlare was failing to do the aggregations correctly. While examining the output file produced by the job, we noticed that hospitals 1 and 2 weren’t taken into account. After debugging we found out that this was a bug in NVFlare and not in our modules.
It seems like this problem occurs because hospitals 1 and 2 need more time (2-5 extra seconds) for the SHAP value calculations, since they have more available data. We tackled this bug by using Python’s time.sleep(), and standardizing the run time to 30 seconds for every node of this job.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
MLOps
The integration of MLOps with FL enables the streamlined progression of machine learning models from development to production. This is crucial since it optimizes the resources and enhances the overall quality of the final product.

The following are the main MLOps features that allows us to implement a successful ML workflow:
Reproducibility: One of the convenient features of MLflow is its ability to handle the entire process of packaging the model. We utilized this functionality to locally register the model whenever a hospital validates it at each epoch. The model files, along with the configuration and environment, are stored in the blob storage of the corresponding hospital while the logs of the metrics and parameters are stored in the Azure SQL database of the research center.
Versioning: In a federated learning use case, version control poses significant challenges due to multiple dimensions that need to be tracked, such as the framework, aggregation method, model version, and aggregation strategy implemented by the research center. Since our current solution only allows the use of a single framework and aggregation method, we have opted to simplify versioning by using calendar-based versioning. Each trained model will be tagged with a version number in the format "year.month.version." With each iteration of the process, the version number will be increased by 1 and reset at the beginning of each month.
Testing: By leveraging MLflow to track the evolution of metrics, we can ensure a seamless continuity of the process and avoid deploying underperforming models. The ability to monitor performance is also incorporated into the Power BI dashboards, providing accessible performance tracking.
Deployment: Deployment isn’t part of our solution. We wanted to give the hospitals complete freedom to choose the model that best suits their needs. In order to do that, we provide the hospitals with access to the models and let them decide whether or not they will use them in deployment.
Monitoring: Monitoring encompasses both data drift and performance tracking. While each hospital is responsible for monitoring data drift independently, we offer a dashboard that aids in visualizing and gaining insights into the data. Performance monitoring can also be carried out using the available Power BI dashboards. However, since hospitals have the freedom to choose their preferred model, they should implement some monitoring measures on their own.
Automation: The federated model training, described previously, is completely automated by the use of several CI/CD pipelines, implemented in Github actions. This includes a pipeline that sets up the required infrastructure (storage accounts, virtual machines, virtual networks, …), one that is responsible for setting up the NVFLARE network and, finally, one responsible for running the jobs on the NVFLARE network.
The division into three distinct steps (with distinct workflows) allows for easy retraining if e.g. only the model code changes or redeploying the NVFLARE setup without having to go through the long process of setting up the infrastructure again. These pipelines can either be triggered manually or automatically. The latter is currently implemented so they run either if their respective code is changed during a push or if the preceding workflow completed running. In the future these automatic runs would include a manual approval step to prevent accidental loss of data.
For further information on how to implement ML Flow in NV Flare, refer to this example in the GitHub repository.



The complete integration of MLOps best practices with MLflow within NVflare is not very straightforward. We identified three main downsides that need to be taken into account:
- Model registration: As the server part is used solely for orchestration purposes and is not used to execute any code related to model registration, there is no clean way to register the aggregated model.
- Aggregated performance: The aggregated model cannot be evaluated on a dataset containing the data from all the hospitals at once. Therefore an agreement has to be done concerning how the aggregated performance will be calculated.
- Experiments structure: MLflow doesn’t allow you to have a several layer file structure which can be a limitation for the organization of the experiments. <!--kg-card-end: markdown--><!--kg-card-begin: markdown--> ## User-friendly Dashboard
NVIDIA FLARE generates local statistics about the hospital data and aggregate them into Federated statistics. These statistics are stored by the server in a json file. For an user-friendly use, the statistics are shown in a PowerBI dashboard together with model training metrics and features explainability. The visual below explains the workflow to create the dashboard.

The Power BI dashboard is connected to the Azure SQL database so an update in the SQL database will automatically update the Power BI dashboards. Some features available in the dashboard are:
- The training plots of the global models and its progress for each hospital dataset.
- Explainability of the features of the global model.
- The feature distribution of the local hospital dataset and the global dataset.
- Looking at each specific feature; the mean, standard deviation and sum of the training and testing set of each hospital data and the global data.
Below we can see how this feature appears in the dashboard:

Request access for RAFL-MODEL and RAFL-DATA
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Conclusion
NV Flare is a reliable and efficient solution that effectively addresses the challenges associated with Federated Learning, including Privacy and Security, Data Heterogeneity, Communication, and Orchestration. In addition to that, It also offers capabilities for Federated Statistics and Model Explainability. By integrating ML Flow with NV Flare, the traceability part of MLOps can be applied to Federated Learning, enabling us to keep track and enhance our models. Furthermore, NV Flare supports other MLOps solutions. With the incorporation of GitHub actions, CI/CD pipelines can be implemented into the final product, providing an end-to-end solution for Federated Learning with MLOps.
<!--kg-card-end: markdown--><!--kg-card-begin: markdown-->
Links
NV Flare: https://nvflare.readthedocs.io/en/main/index.html
ML Flow: https://mlflow.org/
Github repository: https://github.com/datarootsio/federated-learning-project/
You might also like
[
Cloud-native framework for federated learning, designed with privacy and security at its core - Dishani Sen, Eya Akrimi
In the roots academy session of March 2023, a group of Data & Cloud engineers and ML engineers collaborated together to deliver a cloud-native framework for healthcare data analysis, designed with privacy and security at its core; federated learning framework for healthcare. In this blog, we introd…


[
Federated Learning - a tour of the problem, challenges and opportunities - Raul Jimenez Maldonado, Omar Safwat
The majority of machine learning algorithms are data hungry, the more the datawe feed our models, the better they learn about the world’s dynamics. Luckilyfor us, data is everywhere in today’s world, dispersed over the differentlocations where they were collected. Examples of this is the user da…

](https://dataroots.io/research/contributions/federated-learning/?ref=dataroots.ghost.io)





Top comments (0)