Step-wise Composing Larger Queries from Smaller Queries
Recently I was asked “Could we get some numbers on cohorts of users commenting on a welcome thread?” Sure thing!
I chose to write up the following post to “show my work” and demonstrate how one might iterate through SQL.
Establishing the Entity Relationship Model
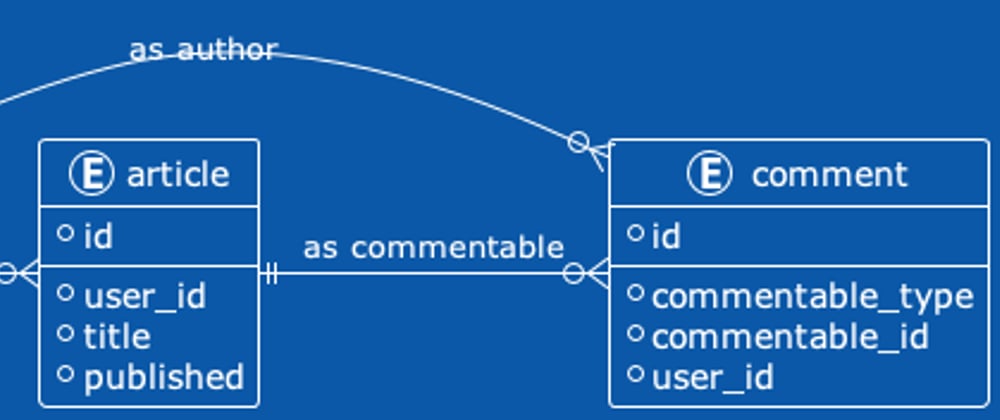
When I’m writing SQL, I tend to start with a relationship diagram of the tables. This helps me understand how I’m going to join and select records; In this case we’re working with 3 tables.
Below is an abbreviated summary of the Ruby on Rails classes and their relationships.
class User
has_many :articles
has_many :comments
end
class Article
belongs_to :user
has_many :comments, as: :commentable
end
class Comment
belongs_to :commentable, polymorphic: true
belongs_to :user
end
And for those of you who prefer an Entity Relationship Model (ERM) of the three data models.

I’m going to tackle this in two segments:
- Getting a Sense of the Scope of the Query and the Expected Numbers
- Creating the Cohort Query Guided by the Previous Work
Getting a Sense of the Scope of the Query and the Expected Numbers
My goal in this leg of the journey is to get a sense of the numbers. I’m not going to show any of the actual resulting data queryied.
With diagram in hand, let’s go find the users who are writing posts that start with “Welcome Thread -v”.
SELECT DISTINCT user_id
FROM articles
WHERE published = true
AND title LIKE 'Welcome Thread - v%'
In the above the title LIKE 'Welcome Thread - v%' is the equivalent of all titles that start with “Welcom Thread -v”.
The query returned one result; user_id of XXX (e.g. thepracticaldev).
Alright, we now are going to make sure things look right in the articles.
SELECT id, title, published_at::date AS publication_date
FROM articles
WHERE title LIKE 'Welcome Thread - v%'
AND published = true
AND user_id = XXX
ORDER BY published_at DESC
A quick scan of the result set from the above query shows what looks like a weekly cadence of posting the welcome article.
Let’s set the above aside and look at the users.
To keep things simple, let’s work with one “cohort”. The following query finds non-spam users who registered within the last 7 days.
The query excludes spammers. By convention, we change spammer’s usernames to begin with “spam_”. Woe is the person who chooses “spam_” as part of their username.
SELECT id, created_at::date AS created_date
FROM users
WHERE created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%')
Now let’s find the comments’s that these users have written.
SELECT comments.id, comments.article_id
FROM comments
-- Use the subquery of users to limit comments to only those commenters --
WHERE comments.user_id IN (
SELECT id
FROM users
WHERE created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%')
)
And let’s see how many of those were on a welcome thread. I’m not checking which welcome thread nor am I only counting one comment per user.
Again, the purpose of this phase is to help me understand the shape of the data. About how many articles and comments should I expect.
SELECT COUNT(id)
FROM comments
WHERE comments.commentable_type = 'Article'
-- Use the subquery of articles that are only welcome threads --
AND comments.commentable_id IN (
SELECT id
FROM articles
WHERE title LIKE 'Welcome Thread - v%'
AND published = true
AND user_id = XXX)
-- Use the subquery of users to limit comments to only those commenters --
AND comments.user_id IN (
SELECT id
FROM users
WHERE created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%'))
Let’s refactor this to give us comment counts and number in this cohort:
SELECT COUNT(id) AS commented_on_welcome_thread, (
SELECT COUNT(id)
FROM users
WHERE created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%')) as cohort_size
FROM comments
WHERE comments.commentable_type = 'Article'
-- Use the subquery of articles that are only welcome threads --
AND comments.commentable_id IN (
SELECT id
FROM articles
WHERE title LIKE 'Welcome Thread - v%'
AND published = true
AND user_id = XXX)
-- Use the subquery of users to limit comments to only those commenters --
AND comments.user_id IN (
SELECT id
FROM users
WHERE created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%'))
The above counts the number of comments these new users left on the welcome articles. I found my way through the relationships of comments, articles, and users.
I’m not a fan of the duplication of SELECT … FROM users; but can refactor. More importantly, the above query is not answering the actual question.
Creating the Cohort Query Guided by the Previous Work
I need to shuffle some things around. I know how the total number of comments, articles, and number of comments for this most recent cohort.
Let’s make this a “user centered” query; I think that will help us out even more.
The following query uses two LEFT OUTER JOIN declarations. Let’s walk through that just a bit, as I switched how I was implementing the queries.
SELECT DISTINCT users.id AS user_id, articles.id AS article_id
FROM users
LEFT OUTER JOIN comments ON comments.user_id = users.id
AND comments.commentable_type = 'Article'
LEFT OUTER JOIN articles ON comments.commentable_id = articles.id
-- Only include articles that are welcome threads --
AND articles.title LIKE 'Welcome Thread - v%'
AND articles.published = true
AND articles.user_id = XXX
-- Only include recently registered users --
WHERE users.created_at::date > NOW()::date - INTERVAL '7 day'
AND username NOT LIKE ('spam_%')
In the above, we have two fields in our result set: user_id and article_id. In using those two LEFT OUTER JOIN statements, we’re doing the following:
Give me all users (e.g. every row in the result set will have a non-nil value in the user_id column). If they commented on a welcome article, provide that article_id; otherwise leave that row’s article_id nil.
Again, you can see the “bones” of the previous queries but we’re approaching this query in a different manner.
At this point, I’m fairly confident I have what I need to explore writing a cohort analysis query. I haven’t done that yet, so I look for examples and to Blazer’s Cohort Analysis documentation.
I need a user_id, conversion_time, and cohort_time. Below is the query I settled on.
In this case, I want the first time a user comments on any welcome thread to be the “time of conversion”; hence the MIN(comments.created_at) AS conversion_time portion of the select clause.
And because I’m using the MIN() aggregate function, I need to specify an aggregate function for the other returned column names (e.g. users.id and users.created_at); I use GROUP BY function to aggregate those columns.
/* cohort analysis */
SELECT users.id AS user_id,
MIN(comments.created_at) AS conversion_time,
users.created_at AS cohort_time
FROM users
LEFT OUTER JOIN comments ON comments.user_id = users.id
AND comments.commentable_type = 'Article'
LEFT OUTER JOIN articles ON comments.commentable_id = articles.id
AND articles.title LIKE 'Welcome Thread - v%'
AND articles.published = true
AND articles.user_id = XXX
WHERE users.created_at BETWEEN
date_trunc('month', now() - interval '7' month)
AND date_trunc('month', now())
GROUP BY users.id, users.created_at
As a note, when writing these cohort queries, if you run it without saving you won’t see the tabular cohort data but will instead see a result set with the three columns in the SELECT statement.
Conclusion
This walk through went down a few pathways, but I feel it was a worthwhile journey to help share a more detailed approach for writing and composing SQL.





Top comments (0)