It is exciting to read the latest research advances in the computational linguistics. In particular, the better language models we build, the more accurate downstream NLP systems we can design.

Having background in production systems I have a strong conviction, that it is important to deploy latest theoretical achievements into real life systems. This allows you to:
- see NLP in action in practical systems
- identify possible shortcomings and continue research and experimentation in the promising directions
- iterate to achieve better performance: quality, speed and other important parameters, like memory consumption
For this story I’ve chosen to deploy BERT — language model by Google — into Apache Solr — production grade search engine — to implement neural search. Traditionally the out of the box search engines are using some sort of TF-IDF — and lately BM25 — based ranking of found documents. TF-IDF for instance is based on computing a cosine similarity between two vector representations of a query and a document. It operates over the space of TFs — term frequencies, and IDFs — inverse document frequencies, which combined tend to favour documents with more signal to noise ratio with respect to an input query. BM25 offers improvements to this model, especially around the term frequency saturation problem. The buzzing topic of these days is neural search as an alternative to TF-IDF/BM25. That is, use some neural model for encoding the query and documents and computing a similarity measure(not necessarily cosine) based on these encodings. BERT is the B idirectional E ncoder R epresentations for T ransformers and in the words of its authors “the first deeply bidirectional, unsupervised language representation, pretrained using only a plain text corpus”. In practice, it means, that BERT will encode the “meaning” of a word, like bank in the sentence “I accessed the bank account” using the previous context “I accessed the” and the next context “account” using the entire information of the deep neural network.
OK, let’s get started!
We will use bert-as-service and Apache Solr 6.6.0. I recommend you to create a virtual environment for your project and perform all installations in it to keep your system-level python clean. Let’s get going with the practical setup:
_# Install tensorflow_
pip install tensorflow==1.15.3
bert-as-service does not work with the latest version of TensorFlow as of this writing (see GitHub issue), but I have tested it to work with 1.15.3.
Next, we will install bert-as-service components — server and client:
pip install bert-serving-server
pip install bert-serving-client
Now we can download the BERT model. You can chose a pre-trained model with parameters you like. I have chosen BERT-Base, Uncased model with 12 layers, 768 dimensions and 110 million parameters. Unzipped, this model occupies 422MB on disk.
Time to launch the BERT server:
bash start\_bert\_server.sh
# As the service starts, it will print its progress.
# Wait until the similar to the following lines appear on the screen:
I:WORKER-1:[\_\_i:gen:559]:ready and listening!
I:WORKER-3:[\_\_i:gen:559]:ready and listening!
I:VENTILATOR:[\_\_i:\_ru:164]:all set, ready to serve request!
This script will launch the server serving the selected model with 2 workers. Each worker seems to load the copy of the model into memory, so depending on the RAM available on your machine you might want to change the number of workers. Just edit the script!
To test the server, we can run a sample BERT client to compute vectors for 3 input sentences:
Bert vectors for sentences ['First do it', 'then do it right', 'then do it better'] :
[[ 0.13186474 0.32404128 -0.82704437 ... -0.3711958 -0.39250174
-0.31721866]
[ 0.24873531 -0.12334424 -0.38933852 ... -0.44756213 -0.5591355
-0.11345179]
[ 0.28627345 -0.18580122 -0.30906814 ... -0.2959366 -0.39310536
0.07640187]]
The code outputs 3 vectors, each with 768 dimensions. This is an important property of BERT: no matter how short or long input sentence or text is, BERT will always output the vector with fixed number of dimensions (in this case 768, but can also be 1024, if you chose BERT-Large, Uncased model).
This sets up the stage for our further experiment with Solr.
Search engine also requires a few configuration steps, so let’s complete them. First we need to enable Solr to understand the vector data type. To achieve this, I have used the following query parser plugin: https://github.com/DmitryKey/solr-vector-scoring (forked). Follow the instructions on the page to configure solrconfig.xml and schema. I have done some modifications to the managed schema file in order to incorporate the abstract URL field — you can find my version of Solr config on GitHub. Next, let’s start Solr with 2G memory:
bin/solr start -m 2g
We can check that Solr has started up correctly by navigating to http://localhost:8983/solr/#/vector-search/query and hitting the button Execute Query. You should see something like this:
{
"responseHeader":{
"status":0,
"QTime":0,
"params":{
"q":"\*:\*",
"indent":"on",
"wt":"json",
"\_":"1597650498814"}},
"response":{"numFound":0,"start":0,"docs":[]
}}
Dataset. This is by far the key ingredient of every experiment. You want to find an interesting collection of texts, that is suitable for semantic level search. Well, maybe all texts are. I have chosen a collection of abstracts from DBPedia, that I downloaded from here: https://wiki.dbpedia.org/dbpedia-version-2016-04 and placed into data/ directory in bz2 format. You don’t need to extract this file onto disk: our code will read directly from the compressed file.
Preprocessing and indexing. Let’s preprocess the downloaded abstracts, and index them in Solr. In preprocessing we will get rid of commented out lines, like:
# started 2016-11-05T13:28:42Z\n
Each abstract starts with two urls:
<[http://dbpedia.org/resource/Austroasiatic\_languages](http://dbpedia.org/resource/Austroasiatic_languages)> <[http://dbpedia.org/ontology/abstract](http://dbpedia.org/ontology/abstract)> "The Austroasiatic languages, in recent classifications synonymous with Mon–Khmer, are a large language family of continental Southeast Asia, also scattered throughout India, Bangladesh, Nepal and the southern border of China. The name Austroasiatic comes from the Latin words for \"south\" and \"Asia\", hence \"South Asia\". Of these languages, only Vietnamese, Khmer, and Mon have a long-established recorded history, and only Vietnamese and Khmer have official status (in Vietnam and Cambodia, respectively). The rest of the languages are spoken by minority groups. Ethnologue identifies 168 Austroasiatic languages. These form thirteen established families (plus perhaps Shompen, which is poorly attested, as a fourteenth), which have traditionally been grouped into two, as Mon–Khmer and Munda. However, one recent classification posits three groups (Munda, Nuclear Mon-Khmer and Khasi-Khmuic) while another has abandoned Mon–Khmer as a taxon altogether, making it synonymous with the larger family. Austroasiatic languages have a disjunct distribution across India, Bangladesh, Nepal and Southeast Asia, separated by regions where other languages are spoken. They appear to be the autochthonous languages of Southeast Asia, with the neighboring Indo-Aryan, Tai–Kadai, Dravidian, Austronesian, and Sino-Tibetan languages being the result of later migrations."[@en](http://twitter.com/en) .
The first link leads to the DBPedia page with the same abstract text and a number of useful external links, like blogposts on the topic — we will index the link into Solr for display purposes. The second link is repetitive across all abstracts, so we will skip it. After some data sampling I have also decided to remove abstracts of 20 words or less: they would usually contain references to disambiguations and not much of substance.
To index the abstracts, execute:
python index\_dbpedia\_abstracts.py
# This will print high-level progress:
parsing data..
indexing docs in solr vector BERT based vectors...
Processed and indexed 500 documents
Processed and indexed 1000 documents
Processed and indexed 1500 documents
Processed and indexed 2000 documents
Processed and indexed 2500 documents
Because one of the most expensive operations is committing into index — which makes indexed documents visible, or searchable — we will do this every 5000 documents. This can be changed in client/solr_client.py by modifying the value of BATCH_SIZE variable.
It takes 1 hour to index 5000 abstracts on my laptop with 2,2 GHz Quad-Core Intel Core i7 and 16G RAM with 2 workers on the server side. Computing:
bzcat data/dbpedia/long\_abstracts\_en.ttl.bz2 | wc -l
5045733
we conclude, that it will take 5045733/5000/24 = 42 days!
This is the first pitfall for deploying the BERT model as is into production: it is way too slow. You can throw more money at it, but a better approach might be to research ways to compact the model through distillation (outside of the scope of this story).
Monitoring is very important for any production grade deployment. The bert-as-service offers you the capability to monitor the service performance via the dashboard/index.html:
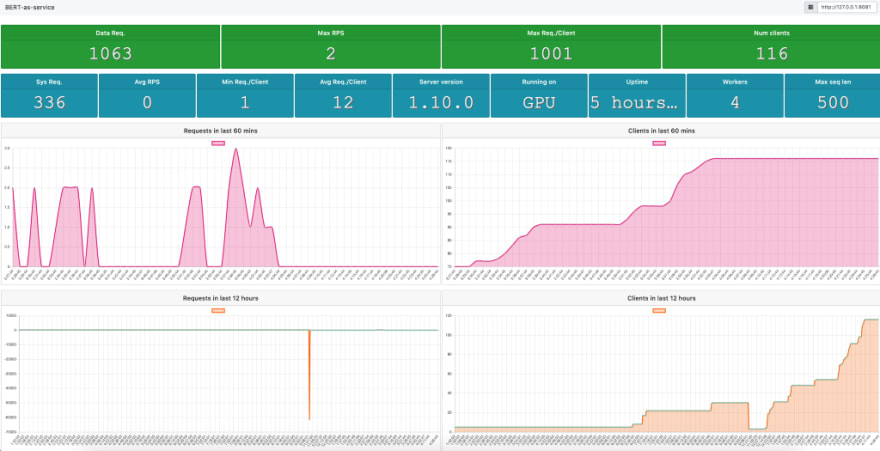
If during processing and indexing you will notice the following response from bert service:
<...>/bert-solr-search/venv/lib/python3.7/site-packages/bert\_serving/client/\_\_init\_\_.py:299: UserWarning: some of your sentences have more tokens than "max\_seq\_len=500" set on the server, as consequence you may get less-accurate or truncated embeddings.
here is what you can do:
- disable the length-check by create a new "BertClient(check\_length=False)" when you do not want to display this warning
- or, start a new server with a larger "max\_seq\_len"
'- or, start a new server with a larger "max\_seq\_len"' % self.length\_limit)
you can try to modify the -max_seq_len=500 parameter value to something larger. However, setting this to 600 or 700 made the service too slow and so I accepted the tradeoff with less accurate embeddings for longer abstracts, that are faster to compute. Again, we are processing abstracts, that can be assumed to be shorter than full articles. The same index_dbpedia_abstracts.py code will output statistics:
Maximum tokens observed per abstract: **697**
Flushing 100 docs
Committing changes
All done. Took: 82.46466588973999 seconds
So you know by how far your configuration of the BERT service is with respect to number of processable tokens. The time it takes to process the data is also a good indicator to look for in improving the performance of the overall system.
Demo. Showing your results in the best possible light is fundamental to communicating your ideas well. For this story I could have used Solr admin page to run a comparative analysis of BERT based neural search versus BM25 ranking. In fact, I do recommend you to familiarize with Solr admin page to explore your data as well as different query and ranking parameters. Let’s take a look at it and run a “computer science” search with BM25 as a ranking function:
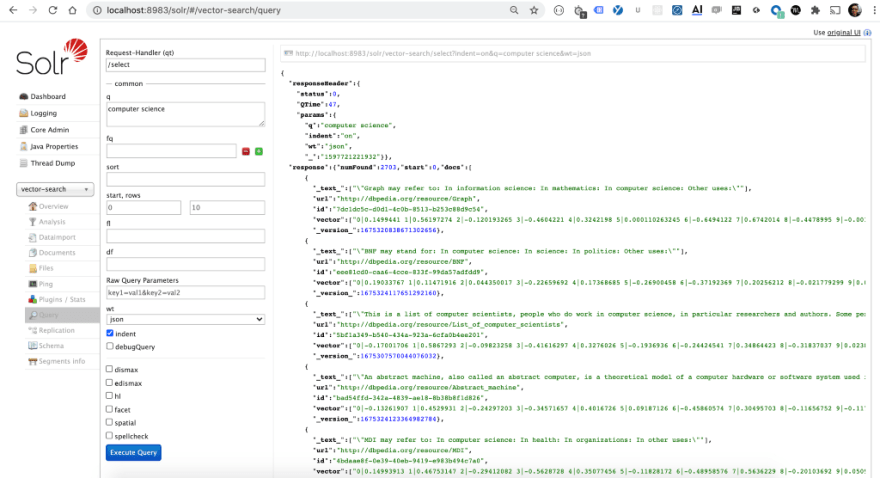
Solr finds 2703 documents, of which top 10 documents ranked by BM25 are shown on the screen in JSON format. You can see the original text of an abstract in the field _text_, and vector representation in the field vector. On top of JSON you can find a URL produced by Solr, used to run your query — you can easily incorporate this URL into your application and parameterize the query. Because it may not be obvious for our users to spot a match within each abstract, we can ask Solr to highlight the matches: tick the hl parameter and configure its parameters in the expanded view:
Let’s rerun the query and scroll to the bottom of the results page:

Neat! Solr has done its best to find and highlight the words from our query by wrapping them into tags. But Solr admin can look a little too technical for your manager or a broader team. Instead, we can use streamlit to build a nice demo.
Let’s do a few comparative searches between BERT based ranking and BM25:
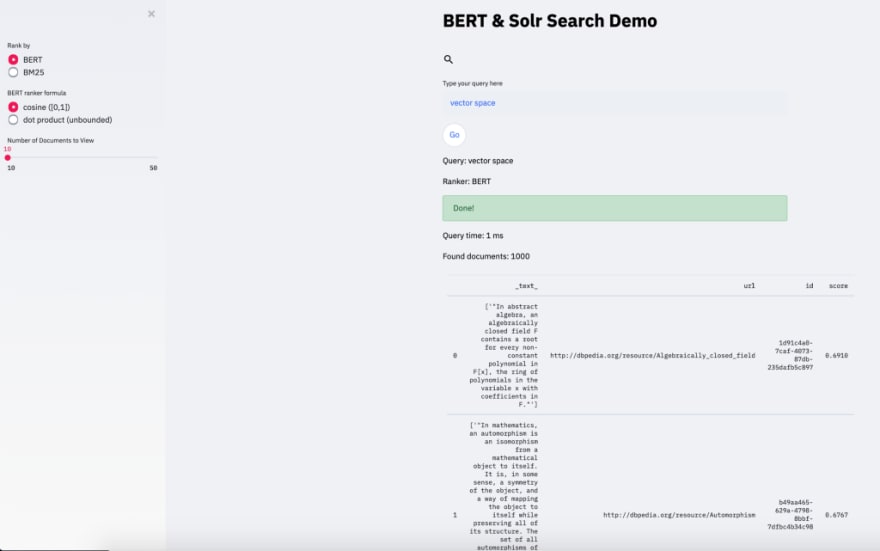
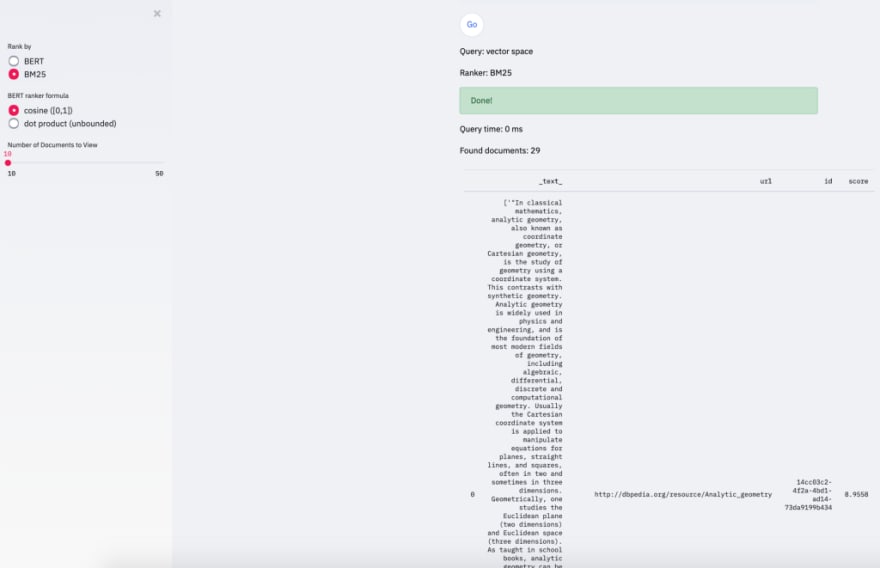
With BERT ranking we can see that first abstracts do not mention the word vector explicitly: there is however a computational semantic connection established with mathematics and hence first few abstracts talk about “abstract algebra”, “automorphism” and “analytic geometry”. BM25 is more keyword oriented approach, and so it makes sure to find only documents with the requested words present: the abstract with “analytics geometry” is picked, because it contains both words “vector” and “space”, albeit in different contexts: “vector or a shape” and “Euclidean space”. BM25 (or TF-IDF) rigor shows in number of documents found: 29 vs 1000. It worth to mention, that BERT ranker always matches entire index of documents — which can be expensive and should be taken care of on the Solr side. There is an entire jira discussion dedicated to this topic: https://issues.apache.org/jira/browse/LUCENE-9004
Let’s make a couple more searches:
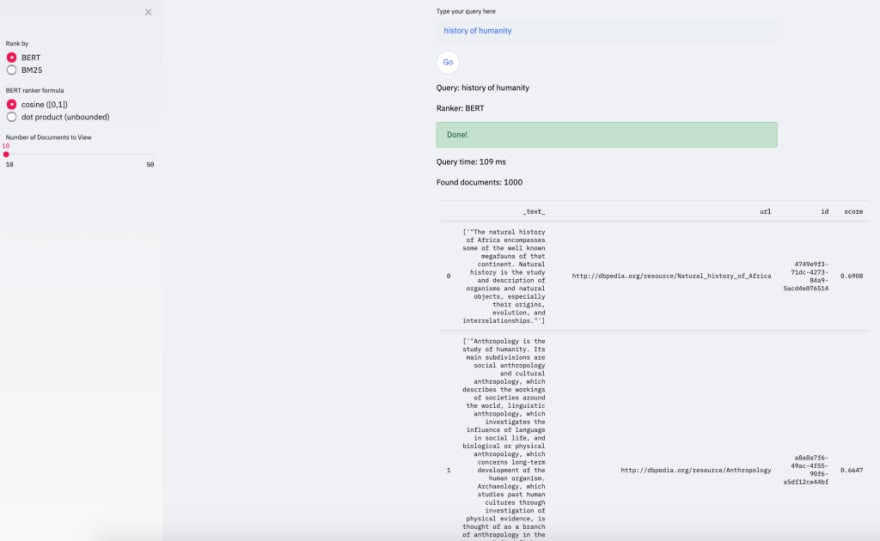
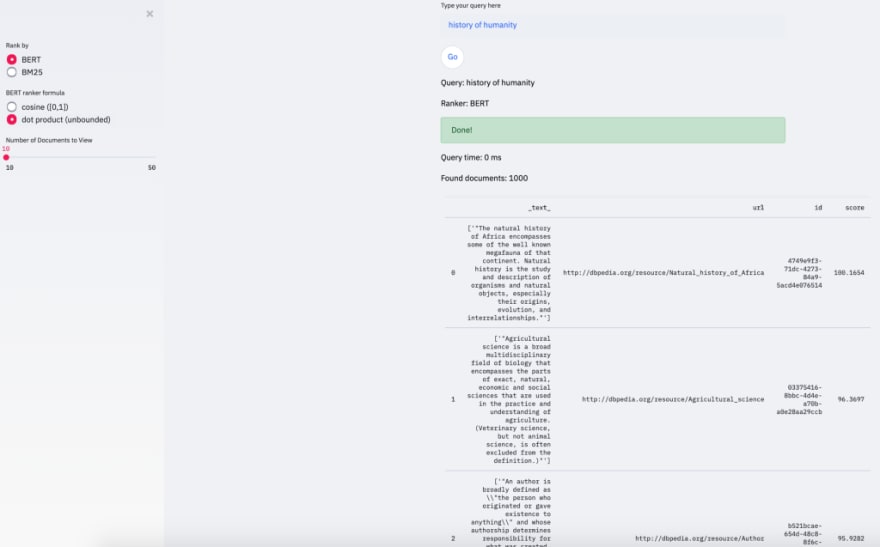
These two searches compare BERT ranker with itself, using different approaches to computing a distance between query and document vectors: cosine similarity and dot product similarity. The top abstract is the same — talking about natural history of Africa (going towards “megafauna” topic, rather than “humanity”). The second document is with dot product is about agricultural science, while with cosine similarity we observe a seemingly more relevant abstract about anthropology.
Conclusions. Using vector space other than traditional TF-IDF / BM25 methods is a promising direction for search and in this story we have taken a peak at how you can incorporate the BERT language model into your Solr powered search engine. On one hand this approach favours recall over precision by matching a lot of documents. But if you apply smart thresholding for cosine similarity values (which are bounded between 0 and 1), you may find semantically more related documents, that might not even contain the searched words verbatim, but will have some synonyms or related sentences, like in the example with “vector space” search.
There is also a concern of speed: BERT based ranker can easily take 5 seconds to match 1000 indexed documents and that can be prohibitively slow. This means, that methods for shrinking the model size (by distillation for instance) should be considered to speed up the inference both during indexing and searching.
I hope you find this story useful for your study of BERT and similar language model architectures and all code used to prepare this story can be found on GitHub.





Top comments (0)