
In diesem Artikel lernst du die Grundlagen, Herkunft und Phasen von Infrastructure as Code kennen. Darüber hinaus zeigen wir dir kleinere Codebeispiele, um einen ersten Eindruck der verschiedenen Tools zu geben und somit deine Hemmschwelle zur Nutzung auf ein Minimum zu reduzieren. Durch den gewonnenen Überblick wirst du problemlos das richtige Tooling für dein Projekt zusammenstellen können, versprochen!

Die manuelle Konfiguration von Server-Landschaften stellt IT-Fachkräfte vor mehrere Herausforderungen, zum Beispiel aufgrund der immer weiter ansteigenden Komplexität und der damit verbundenen Anforderungen an IT-Infrastruktur.
Der Infrastructure as Code (IaC) Ansatz bietet eine Alternative, in dem Server zum Beispiel durch maschinenlesbare Skripte provisioniert, konfiguriert und gemanagt werden.
IaC lässt sich als die formale Beschreibung von Infrastrukturen wie beispielsweise Server, Datenbanken, Netzwerkkomponenten usw. definieren. Zudem lässt sich der Infrastructure as Code Ansatz mittels einer Vielzahl von Software Tools / Frameworks umsetzen.
HINWEIS: Aufgrund der Tatsache, dass man alleinig mit dem Thema “Was ist und was umfasst IT-Infrastruktur” diverse Bücher füllen könnte, haben wir uns dazu entschlossen, in diesem Artikel stark vereinfacht den Blick auf Server als Platzhalter von Infrastruktur zu richten. Dabei spielt es keine Rolle, ob es sich um einen Bare-Metal-, containerisierten oder virtualisierten Server handelt.
Woher kommt Infrastructure as Code?
„Nur wer die Vergangenheit kennt, kann die Gegenwart verstehen und die Zukunft gestalten“ – August Bebel
Lass uns 15-20 Jahre in der Zeit zurückreisen und einen Blick auf Softwarefirmen wie Adobe, Atlassian oder Facebook werfen. Aus der heutigen Sicht sehr erfolgreiche Unternehmen. Doch auch diese haben einmal klein angefangen. Um ihre digitalen Produkte verkaufen zu können, betrieben sie erst einzelne Server und kamen mit wenig Hardware aus. Nach und nach wurden daraus kleinere Rechenzentren. Zunächst selbst betrieben, kaufte man sich später die Verwaltung und Hardware von anderen Dienstleistern ein. Mit den Jahren wuchs die Serverlandschaft in den Rechenzentren stetig weiter, um einen stabilen Betrieb für wachsende Nutzerzahlen gewährleisten zu können. Man unterschätzt vollkommen, wieviele Server nötig sind. So verkündete Facebook 2009, gerade 5 Jahre nach Start ihres sozialen Netzwerkes, dass sie mehr als 30.000 Server betrieben!
Provisionierung, Konfiguration & Deployment war mal ziemlich langsam
Selbst wenn eine Firma lediglich einige Dutzend Server bereitstellen muss, kommt es schnell zu organisatorischen Herausforderungen. Dies beginnt damit, dass beim Hochskalieren neue Server-Hardware bestellt und in den Serverräumen verbaut werden muss. Dazu gehört auch die Anbindung ans Netzwerk. Dank Cloud-Providern, wie beispielsweise AWS, Azure oder Google, ist dies heute mit einem geringeren Aufwand verbunden. Server sind schon Minuten nach der Bestellung über das Internet erreichbar. Ebenso können sie direkt konfigurativ an virtuelle Netzwerke, Loadbalancer, etc. … angebunden werden.
Doch nach dem Bereitstellen des blanken Servers ist man noch nicht fertig. Üblicherweise muss jeder Server zweckgebunden eingerichtet werden: Die Konfiguration beinhaltet zum Beispiel Benutzerverwaltung oder die Installation von Abhängigkeiten, wie Laufzeitumgebungen und sonstige Arbeiten, die später für den Betrieb der Software notwendig sind.
Ist ein Server einmal bereit, kann die eigentliche Software installiert werden. Ein solches Deployment passiert heute auch meist automatisch. Zumindest hat die DevOps-Bewegung klar gemacht, dass solche Prozessschritte idealerweise vollautomatisiert ablaufen sollten.
Das sind keine einmaligen oder seltenen Tätigkeiten. Bei einer größeren Landschaft werden ständig alte Server entfernt, neue hinzugefügt oder bestehende angepasst. So entsteht ein fast natürlicher Lebenszyklus von Servern.
Automatisierung gegen Fehler und Configuration Drift
Bei jedem neuen Server werden die oben beschriebene Schritte abgehandelt. Doch der Betrieb der „alten“ Server sowie die Weiterentwicklung der Produkte soll natürlich weitergehen. Durch den erheblichen Mehraufwand kann es ohne IaC dazu verführen, an Stelle eines neuen Servers, alte Server zu modifizieren oder zweckzuentfremden. Dabei kann es leicht passieren, dass aus einer „Testmaschine“ eine neue „Produktiv-Instanz“ gemacht wird. Manchmal müssen auch ganz dringend Laufzeitumgebungen verändert oder generell ein anderes Tooling installiert werden.
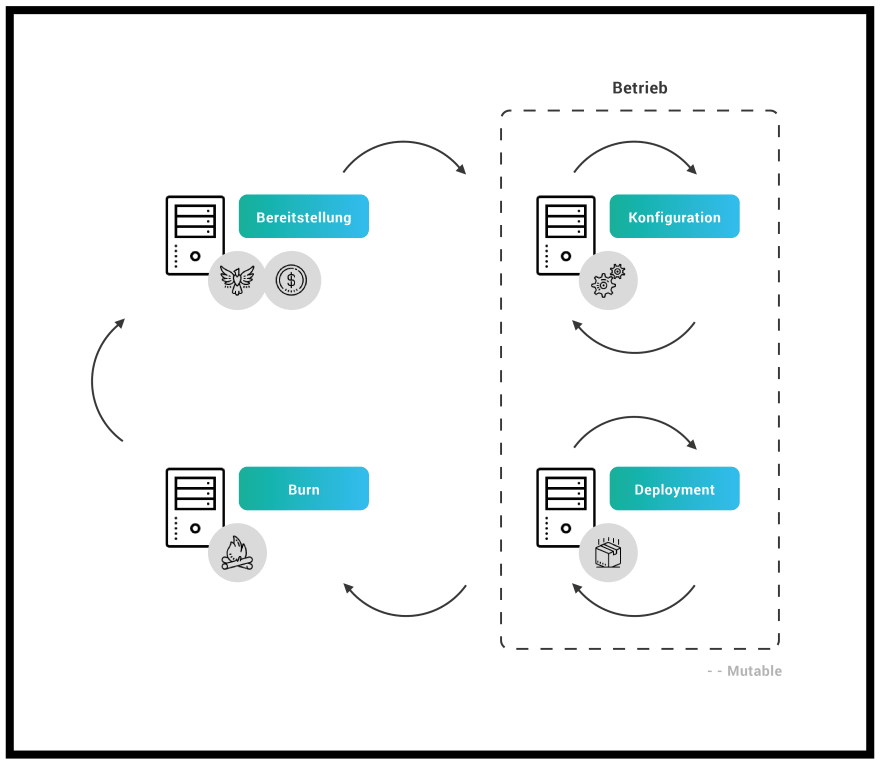
Solche nicht dokumentierten Ad-Hoc Änderungen führen langfristig immer zu Problemen. Man redet hierbei von einem „Configuration Drift“, also von dem Zeitpunkt, ab dem man von der Standardkonfiguration des Servers abweicht. Durch die lange Laufzeit der Server sammeln sich nach und nach immer mehr Altlasten an. Schritt für Schritt mutieren diese Server zu sogenannten Snowflake-Servern – jeder ein Unikat und damit fast unmöglich zu warten:
„The result is a unique snowflake – good for a ski resort, bad for a data center.“ – Martin Fowler
Aufgrund dieser Tatsache etablierte sich das Phoenix-Server-Pattern, welches diesem Umstand ein Ende setzen will. „Wie der Phoenix aus der Asche“, soll ein Server virtuell abgebrannt und in regelmäßigen Abständen neu aufgesetzt werden:
„A server should be like a phoenix, regularly rising from the ashes“ – Martin Fowler
Doch auch dies wäre ohne Automatisierung der Infrastruktur äußerst aufwendig. Früher versuchte man noch die Automatisierung mit Shell-Skripten abzubilden. Schnell wurde jedoch klar, dass diese Scripte durch ihre oftmals hohe Komplexität und die dadurch schlechte Portierfähigkeit auf die verschiedensten Serversysteme nicht das Mittel der Wahl sein konnten. 1993 dann wurde mit dem Projekt „CFEngine“ das erste IaC Tool entwickelt. CFEngine bietet eine vom Betriebssystem unabhängige Schnittstelle und abstrahiert damit die Unterschiede der verschiedenen Linux Distributionen. Mit seiner deklarativen und domänenspezifischen Beschreibungssprache vereinfacht das Tool die Konfiguration von Servern ungemein. Heute existieren viele ähnliche Lösungen, wie die nachfolgende Grafik beispielhaft zeigt:

All diese Tools versuchen durch die Automatisierung von Infrastruktur unter Zuhilfenahme von Prinzipien und Praktiken aus der Softwareentwicklung, dieses komplexe Unterfangen zu vereinfachen, zu beschleunigen und wartbar zu machen. Dabei spezialisieren sich die Tools auf verschiedene Phasen, welche wir dir nachfolgend genauer erläutern.
Die verschiedenen Phasen
Wenn man IaC anwendet, unterscheidet man zwischen zwei Phasen. Jede Phase deckt bestimmte Arbeiten ab:
- Initiale Setup Phase
- Provisionierung der Infrastruktur
- Konfiguration der Infrastruktur
- Initiales Installieren von Software
- Initiale Konfiguration von Software
- Maintaining Phase
- Anpassen der Infrastruktur
- Entfernen und Hinzufügen von Komponenten
- Software Updates
- Rekonfiguration von Software
Um es ein wenig zu abstrahieren, reden wir nachfolgend vom initialen Infrastruktur- sowie vom initialen Applikations Setup und deren Managements. Dies deckt dann die beiden Phasen komplett ab. Je nach Betrachtungsweise und Tool liegt eher die Infrastruktur- oder die Applikationsseite im Fokus. Docker beispielsweise wird vermehrt als eine Art Deployable verwendet, als wirklich als eine Infrastrukturkomponente, weswegen es im nachfolgenden Bild auf der rechten Seite angesiedelt ist. Die Grafik kann je nach Betrachtungswinkel immer wieder anders aussehen und repräsentiert derzeit nur unsere Sichtweise.
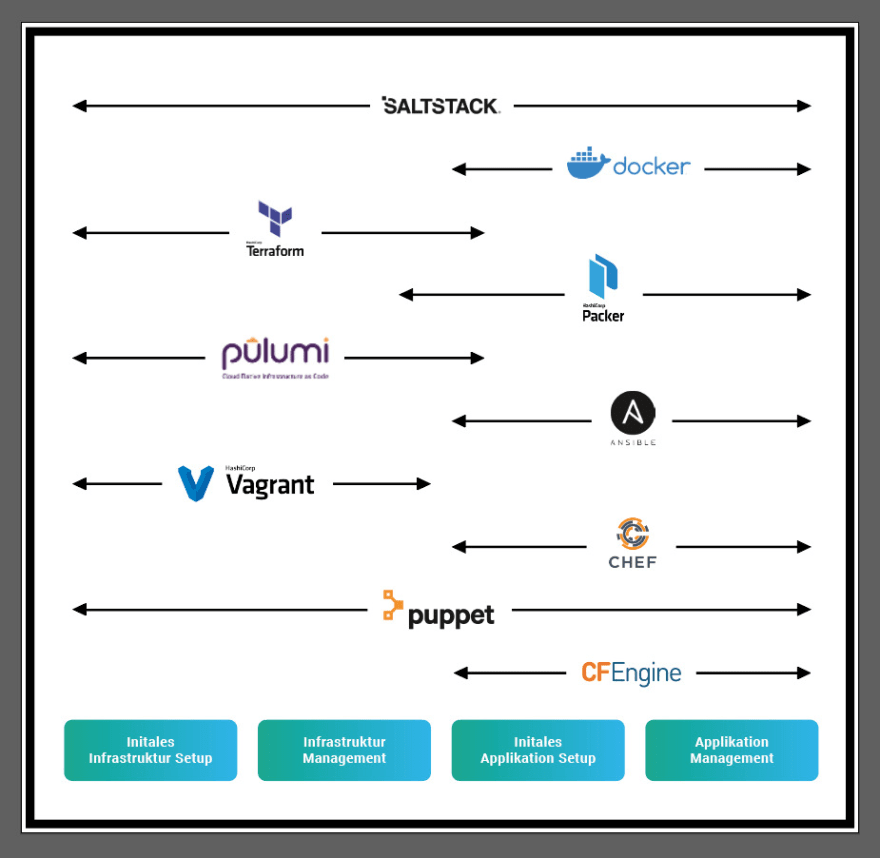
Die verschiedenen Arten von IaC
Es existieren die verschiedensten Arten von IaC. Jede bringt spezifische Vor- und Nachteile mit sich und so ist es je nach Anwendungsfall abzuwägen, welche Art von IaC gerade den größten Mehrwert generieren kann. Nachfolgend stellen wir dir die häufigsten Arten vor und reichern diese mit einem kleinen Codesnippet an.
Scripte
Der einfachste Weg, etwas zu automatisieren, ist das Schreiben eines Scripts. Dabei werden die Teilschritte, der sonst manuell durchgeführten Aufgabe, in der bevorzugten Skriptsprache abgebildet und danach in der Zielumgebung ausgeführt. Das nachfolgende Bash-Script installiert einen Webserver und startet diesen.
#!/bin/bash
# Update Package Manager
sudo apt-get update
# Install Apache
sudo apt-get install -y apache2
# Start Apache
sudo service apache2 start
Beliebte Skriptsprachen:
Konfigurations-Management Tools
Konfigurations-Management Tools sind dafür konzipiert, Software auf vorhandenen Servern zu installieren und zu verwalten. Hier ist zum Beispiel eine Ansible-Rolle, die denselben Apache-Webserver, wie das obige Bash-Skript, konfiguriert:
- hosts: apache
sudo: yes
tasks:
- name: install apache2
apt: name=apache2 update_cache=yes state=latest
Beliebte Konfigurations-Management Tools:
Templating Tools
Eine Alternative zu Konfigurations-Management Tools sind Templating Tools, wie Docker, Packer und Vagrant. Anstatt eine Reihe von Instanzen zu starten und sie durch Ausführen desselben Codes auf jedem einzelnen zu konfigurieren, besteht die Idee hinter Templating-Tools darin, ein Abbild zu erstellen. Diese „Momentaufnahme“ des Betriebssystems, der Software und jeglicher Dateien kann so als eigenständiges Artefakt in Form eines Images ausgeliefert werden. Hier ein Beispiel eines Dockerfiles als Template für ein Ubuntu-basiertes Image für einen Webserver:
FROM ubuntu:latest
RUN apt-get -y update && \
apt-get install -y apache2
ENTRYPOINT ["/usr/sbin/apache2"]
CMD ["-D", "FOREGROUND"]
Orchestrierungs-Tools
Templating Tools eignen sich hervorragend für die Erstellung von VMs und Containern, aber wie kannst du diese effizient verwalten? An dieser Stelle kommen Tools wie Kubernetes, Amazon ECS, Docker Swarm oder Nomad ins Spiel. Da diese Tools sehr komplex sind und eine enorme Bandbreite an Funktionalität mit sich bringen, werden wir an dieser Stelle nicht tiefer auf die Funktionsweise eingehen. So kann das Verhalten eines Kubernetes-Clusters durch Code definiert werden. Das umfasst beispielsweise wie deine Docker-Container ausgeführt, wie viele Instanzen vorgehalten und wie bei einem Rollout vorgegangen werden soll.
Provisioning-Tools
Provisioning-Tools wie Terraform, AWS CloudFormation und Pulumi sind hauptsächlich für die Beschreibung und Erstellung von Cloud-Infrastruktur gedacht. Tatsächlich kannst du mit ihnen nicht nur Server, sondern auch Caches, Load Balancer, Firewall-Einstellungen, Routing-Regeln und so ziemlich jeder andere Aspekt einer IT-Infrastruktur erstellen. Oft greifen Konfigurations-Management oder Templating-Tools und Provisionierungs-Tools ineinander. So kann Terraform beispielsweise eine VM erstellen, die anschließend mit Puppet bespielt wird.
Fazit
Die Wahl zur passenden IaC Toolchain ist nicht einfach, da es keine pauschalen Antworten darauf gibt oder geben kann. Die Vorteile eines etablierten Konfigurations-Management-, Provisionierungs- und/oder Orchestrierungs-Tools sind nicht von der Hand zu weisen. Während der IaC-Ansatz seine Vorteile fast immer ausspielen kann, lohnt es sich bei kleinen Projekten nicht immer gleich zum mächtigen Orchestrierungs-Tool zu greifen. Hast du das Ziel klar definiert und möchtest eine der oben genannten Arten von IaC einführen, so kannst du dich gut an den Anforderungen des Gesamtzieles entlanghangeln und dann das richtige Tool-Setup zusammenstellen.
Mit diesem Überblick sollte es dir auf jeden Fall leichter fallen, die richtige Wahl für dein Projekt zu treffen. Sollten Fragen offen geblieben sein, dann stell diese doch bitte gleich in den Kommentaren. Gerne kannst du auch dein derzeitiges Setup in den Kommentaren vorstellen, wir sind sehr gespannt, welche und vorallem warum du auf folgendes Setup setzt.





Top comments (0)