
Developers are the chefs and data is our ingredient. With MongoDB’s flexibility and power as our tools, we will be creating great digital experiences like dining at a fine restaurant. For those who are willing to investigate its possibilities, this database, renowned for its adept handling of intricate data structures, presents an abundance of options.
Why go with MongoDB? It is the foundation of innovation because it enables scalability to meet the ups and downs of digital demands and real-time data manipulation. We can create masterpieces out of raw data thanks to MongoDB’s comprehensive tools, which range from dynamic updates that perfectly season our datasets to precise indexing that effortlessly sorts through data.
We’ll cover a wide range of typical problems that developers run into in MongoDB, offering advice and solutions that turn these roadblocks into stepping stones. A sample of the typical issues we will cover is as follows:
- Schema Design Dilemmas And Data Modeling Mysteries : It might be challenging to find the ideal balance between being too flexible and too strict. We’ll go over techniques for building efficient schemas that support expansion and change, making sure our database architecture adapts smoothly to the demands of our application.
- Performance Pitfalls : Our data feast can become a famine due to slow queries. We’ll examine how big document volumes, poor indexing, and unoptimized query patterns can all lead to performance degradation, and more significantly, how to resolve these problems.
- Aggregation Agonies : Although MongoDB’s aggregation framework is a useful tool, using it incorrectly can cause issues. We’ll break down how to build pipelines that are effective and powerful, simplifying aggregate procedures.
- Concurrency Conundrums : It takes skill to manage concurrent operations in MongoDB, particularly in high-volume settings. We’ll look at trends and best practices to guarantee data integrity and efficiency when several processes are accessing or changing data at once.
- Scaling Scares : Your data and traffic will increase along with your application. There are difficulties when scaling vertically (larger servers) or horizontally (sharding). We’ll go over how to scale your MongoDB deployment efficiently so that it can keep up with your expanding needs.
Schema Design Dilemmas in MongoDB:
Achieving the ideal balance in MongoDB schema design is similar to choosing the right ingredients for a recipe; too much or too little of any one ingredient can ruin the entire flavour. Let’s look at this using our Resturant that focuses on various relationships inside the database and highlights typical errors, their repairs, and the reasoning behind the solutions selected.
Let’s call it, “Mr Byte,” needing a schema to represent foods, categories, and reviews efficiently.
Common Mistakes in Modeling
Over-Embedding Documents : Initially, developers might embed categories and reviews directly within each food document. While embedding can enhance read performance, it makes updates cumbersome and can quickly bloat the document size.
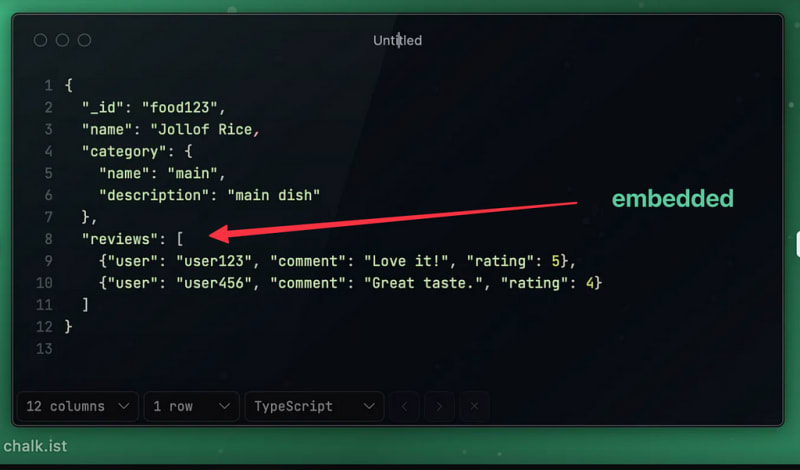
Ignoring Data Access Patterns : Queries that are not optimised for data access may result in inefficiencies. It is not optimal to insert reviews directly into food doc if they are regularly accessed separately from food details.
The Fixes:
Balanced Document Design : To avoid deep nesting, keep everything in balance. For data that is always changing or expanding, such as reviews, use references. If the category data is largely static, keep closely linked data that is read together incorporated, such as food information and categories.

Why? This format keeps evaluations easily managed and expandable while enabling efficient readings of items and their categories together. It keeps food doc from being too long and makes independent review access easier.
Schema for Data Access Patterns : Consider how your application will access the data while designing your schema. It is typical for Mr Byte to access food details without reviews; nevertheless, when reviews are needed, they must be swiftly retrieved.
Why? By optimising for typical access patterns and lowering the overhead associated with reading product details, this method makes sure the application stays responsive even as the volume of data increases.
Understanding Different Relationships
- One-to-One (Food to Category): In this simple example, we presume a meal belongs to one category, even though one-to-many relationships are more typical for categories. For efficiency, this is modelled as an embedded connection because category data is generally static and doesn’t change frequently.
- One-to-Many (Food to Reviews): This is a classic case where the possibly high and increasing number of evaluations per product makes reference desirable. Scalability is ensured by allowing reviews to be added, altered, or removed without changing the product document.
Why These Choices?
Knowing the data access patterns and growth goals of the application is critical to deciding whether to embed or reference. Fast read access and atomicity are provided by embedding for closely related, infrequently changing material. But for data that is frequently updated and expands dynamically, referencing is essential to maintaining the database’s scalability and efficiency.
By giving careful thought to these factors, we may create a schema that satisfies present needs while also being flexible enough to accommodate upcoming modifications, guaranteeing the stability, responsiveness, and scalability of Mr Byte database architecture. This careful approach to schema design is what makes a good database great — perfectly customised to the particular tastes and requirements of its application.
Performance Pitfalls:
Any delay can result in a backup and convert a data feast into a famine in the busy kitchen of “Mr Byte” where orders (queries) come in and go out at breakneck speed. Let’s cut through the problems that can impede the gastronomic (data) flow, such as incorrect indexing, huge document files, and suboptimal query patterns.
High Traffic In Our Restaurant:
Mr Byte experiences slow response times during peak hours, particularly when customers browse menus (food), search for foods, and read reviews.
Common Mistakes
Improper Indexing : Just like forgetting to preheat the oven, not indexing or poorly indexing fields queried often can lead to slow searches.

Without an index on category, MongoDB must perform a collection scan.
Large Document Sizes : Compiling documents that are too large is similar to trying to manage an overstuffed sandwich. Large documents can cause read operations to lag, especially if they contain extraneous embedded data.
Unoptimized Query Patterns: Asking too many questions is like cutting with a dull knife. For instance, retrieving complete documents when just a few fields are required, or failing to use query operators to effectively filter data.
Understanding Query Optimization
It is critical to make sure that data can be accessible quickly and effectively in the high-speed environment. We improve the application’s responsiveness to user interactions by optimising its performance with the implementation of these patches. This guarantees the platform’s scalability as it expands and improves the user experience for customers.
Tricks And Tips For Fast Queries:
Mr Byte is now big, with multiple restaurants
Indexing for Performance : Optimizing query performance for frequently accessed restaurant menus based on cuisine type and ratings.

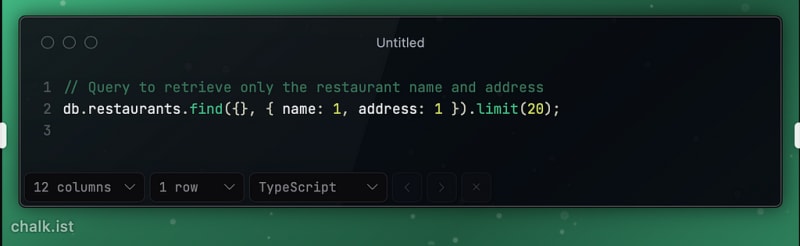
Projection to Reduce Network Overhead: Retrieving only the necessary fields, such as name and address, for a list of restaurants.
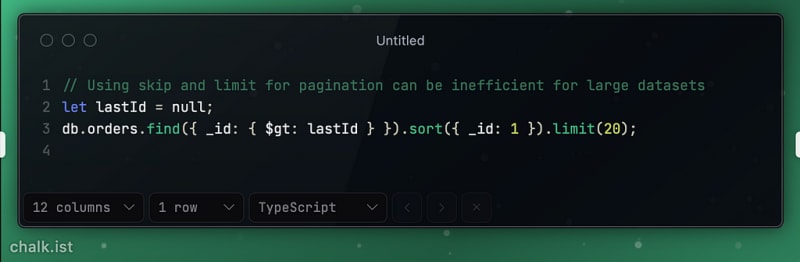
Efficient Pagination: Implementing efficient pagination for a large list of restaurant orders.
Aggregation for Complex Queries: Calculating the average meal cost per cuisine across all restaurants.

Use of $geoNear for Location-based Queries: Finding nearby restaurants within a certain radius.

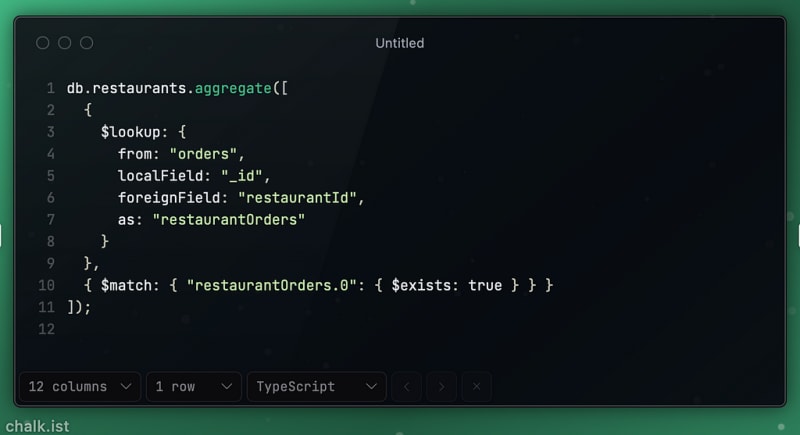
Optimizing $lookup for Joining Collections: Joining restaurants with their orders while minimizing performance impact.
Avoiding $where and JavaScript-based Queries: Filtering restaurants by a complex condition without using $where.
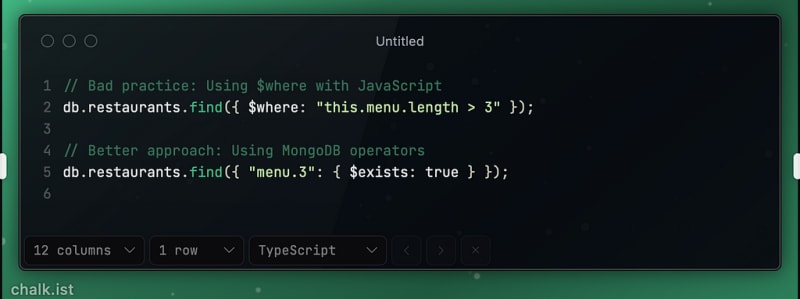
Pre-aggregating Data: Keeping track of the number of orders per restaurant to avoid counting each time

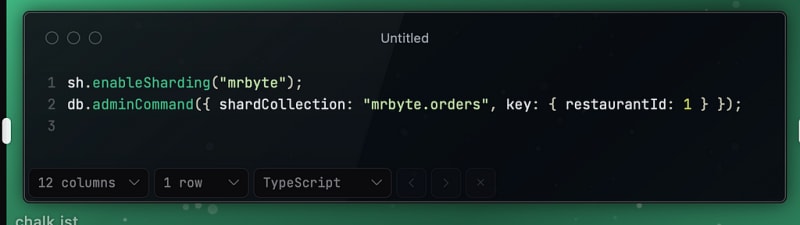
Sharding for Horizontal Scaling: Distributing the orders collection across multiple servers to handle large datasets efficiently.
Using Partial Indexes: Creating an index on orders that are still open.

Utilizing $facet for Multiple Aggregations in a Single Query: Executing multiple aggregation operations in a single query to get various statistics about restaurants.

Optimizing Sort Operations: Sorting operations on large datasets.

Use of Write Concerns for Performance Tuning: Adjusting write concerns for operations where immediate consistency is not critical.

Understanding these sophisticated MongoDB tips will guarantee that database stays responsive and effective, much like a skilled chef understands how to run a successful restaurant. We may make sure that the database supports the expansion of the restaurant chain without sacrificing speed or efficiency by carefully selecting indexing strategies, optimising data retrieval, and knowing the subtleties of MongoDB’s operations. These cutting-edge methods — whether they be through clever scaling strategies, effective data retrieval methods, or strategic indexing — are what makes you a remarkable chef.





Top comments (0)