
I’ve recently been working with the t3-stack, which relies on tRPC for the API and React-Query for the front end requests and Prisma for the CRUD operations. All fully type safe! More info about t3-stack here.
Infinite queries is a pattern that has always caught me because it requires handling correctly the api requests with caching and fetch-more strategies, which correctly implemented saves us of excessive API requests while providing a great UX.
However, this pattern is not usually simple to implement and the existing documentation can’t be very specific due to its advanced use cases. There’s also only limited existing implementations/examples around.
Luckily, React-Query + tRCP + Prisma makes this implementation super simple with the useInfiniteQuery method.
My implementation was for a carousel that displayed a card with products for an ecommerce website. However, infinite queries can be used in several other cases like table pagination, scrolling down, search bars with dropdowns, and more.
Ok, enough talking. Let’s code!
I expect you to already have your t3-stack app already configured — including routers.
I want to fetch all the products or a set of products by their category ids from the Product table.
The Prisma Product model
model Product {
id String @id @default(cuid())
name String
description String
discount Float
categoryId Int
category Category @relation(fields: [categoryId], references: [id])
price Float
image String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
Now we’ll add the query that enables the useInfiniteQuery hook in the tRPC product router.
import { z } from 'zod';
import { t } from '../trpc';
export const productRouter = t.router({
// ... other routes
// get an array of products
// for infinite scroll
getBatch: t.procedure
.input(
z.object({
limit: z.number(),
// cursor is a reference to the last item in the previous batch
// it's used to fetch the next batch
cursor: z.string().nullish(),
skip: z.number().optional(),
categoryId: z.number().optional(),
})
)
.query(async({ ctx, input }) => {
const { limit, skip, categoryId, cursor } = input;
const items = await ctx.prisma.product.findMany({
take: limit + 1,
skip: skip,
cursor: cursor ? { id: cursor } : undefined,
orderBy: {
id: 'asc',
},
where: {
categoryId: categoryId ? categoryId : undefined,
},
});
let nextCursor: typeof cursor | undefined = undefined;
if (items.length > limit) {
const nextItem = items.pop(); // return the last item from the array
nextCursor = nextItem?.id;
}
return {
items,
nextCursor,
};
}),
)
});
So what’s going on here?
First we’ll see the standard input validation with zod. Nothing new. However we can notice three unusual properties for this query.
-
limit: Basically that’s the number of elements that we’ll fetch per query. -
cursor(optional): This is a flag that will be used as a reference for fetching the next batch of items. This flag will be updated at every fetchNextPage request (we’ll be there in a moment). We don’t have to pass this variable but it needs to be declared in the object. -
skip(optional): If you want to skip some initial items. E.g. skip=4will skip the first 4 items from the filtered elements from the list.
This Prisma documentation page contains a great explanation for pagination based fetching in case you want more context.

Pagination (Reference)
Prisma Client supports both offset pagination and cursor-based pagination. Learn more about the pros and cons of different pagination approaches and how to implement them.
 prisma.io
prisma.io
I’ve added an optional categoryId property to the schema. You can add your own logic for filtering based on this one.
Next the query.
-
take: basically as its name says grabs the limit plus one more element. That extra element will be used as the cursor. -
cursor: this cursor will be automatically set by the last query and will be undefined in the first batch. -
orderBy: not much to say, we are ordering in an ascending direction. -
where: for the optional categoryId filtering.
Finally, the nextCursor variable.
If the response from the Prisma query is bigger than the limit it means that there are more items to be fetched. That’s why we took limit+1 elements.
We remove that last element with pop()from the items array and take that element id for our next cursor. This last item will be removed from the items array.
Ok, the router request — procedure — is ready. We’ll do the front end request now.
In our component
const [page, setPage] = useState(0);
const { data, fetchNextPage } = trpc.product.getBatch.useInfiniteQuery(
{
limit: 4,
categoryId: category?.id, // this is optional - remember
},
{
getNextPageParam: (lastPage) => lastPage.nextCursor,
}
);
const handleFetchNextPage = () => {
fetchNextPage();
setPage((prev) => prev + 1);
};
const handleFetchPreviousPage = () => {
setPage((prev) => prev - 1);
};
// data will be split in pages
const toShow = data?.pages[page]?.items;
toShow will use the page state to know what item’s we’ll show. How? check data before we’ve made any fetchNextPagerequest yet:

As you can see, the pages property is an array of objects with items and nextCursor, where the nextCursor is the id of the immediate element after the last element for items.
If we call handleFetchNextPage which increases the page count and calls fetchNextPage we’ll get this response — supposing that there are more items to be fetched — items.length > limit

and so on, until we got out of items — for this example — in page 3
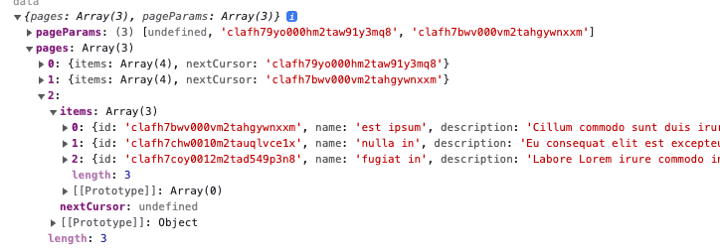
Finally, items.length (3) is not bigger than the limit (4), therefore nextCursor is undefined and fetchNextPage won’t have any effect.
This is how my simple Carousel UI looks like in case you are curious.
I use the pokemon API for the images 🙂.
Page 1:

Page 2:

Page 3:

If you check your console in the browser or in your terminal you’ll see that there are no more requests made once you’ve fetched the total of the items. You can navigate forward and backwards and the data will be cached. Awesome!
If you want to see my full implementation you can go to my repo
And also find more information in:





Top comments (0)