
TLDR
I've listed 23 python hacktoberfest issue that helps developers to contribute to opensource projects.
For new opensource contributors, finding a good place to start can often be difficult. The process of sifting through repositories and identifying issues that are suitable for new contributors is time-consuming and frustrating.

To help you start contributing here, I have curated 23 issues.
Let's check them out!
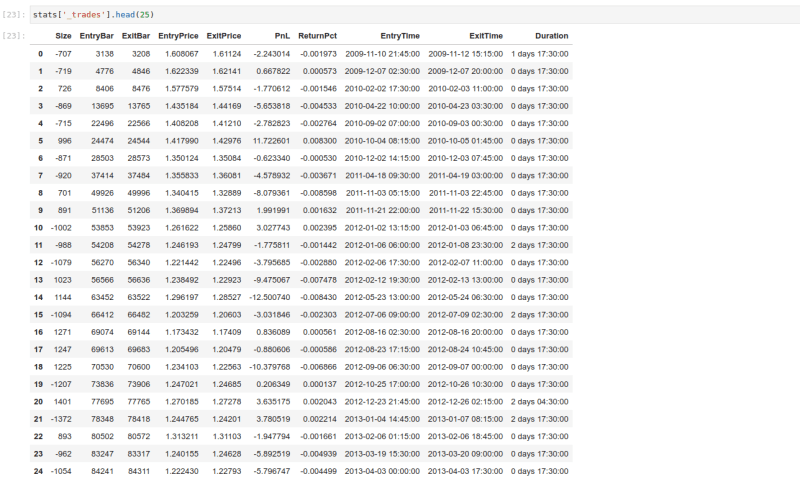
1) Question - add columns to output of bt.run()
Repo : https://github.com/kernc/backtesting.py
 Question - add columns to output of bt.run()
#1033
Question - add columns to output of bt.run()
#1033

Hi,
Great package for backtesting! One question - is it possible to add additional columns to the output of the backtest (such as the indicator values) at the time of the trades? Alternatively, getting the indicator values output for each bar would also be helpful. I could hack it to do it but wondered if there was an easy way.
For example, adding additional columns for each trade with the value of each indicator?
Thanks so much for the great package,
2) Parsing error on Duckdb QUALIFY
Repo : https://github.com/sqlfluff/sqlfluff
Parsing error on Duckdb QUALIFY
#5051

This ticket requests several things. Checked when they are done
- [x] Union all by name: https://duckdb.org/docs/sql/query_syntax/setops#union-all-by-name
- [ ] Pivot: https://duckdb.org/docs/sql/statements/pivot
- [ ] Exclude: https://duckdb.org/docs/sql/expressions/star.html#exclude-clause
- [ ] Replace: https://duckdb.org/docs/sql/functions/char.html
- [ ] Qualify: https://duckdb.org/docs/sql/query_syntax/qualify.html
- [X] // is integer division: https://duckdb.org/docs/sql/functions/numeric.html
Search before asking
- [X] I searched the issues and found no similar issues.
What Happened
This is a valid duckdb query
with
source as (
select * from {{ source('danish_parliament', 'raw_aktoer_type') }}
qualify row_number() over (partition by id order by opdateringsdato desc) = 1
),
renamed as (
select
id as actor_type_id,
type as actor_type,
opdateringsdato as updated_at
from source
)
select * from renamed
I get an unparseble error using both dbt and jinja templater.
Expected Behaviour
Should be able to be parsed and not return error
Observed Behaviour
sqlfluff lint models\staging\stg_actor_types.sql
=== [dbt templater] Sorting Nodes...
20:35:22 [WARNING]: Configuration paths exist in your dbt_project.yml file which do not apply to any resources.
There are 1 unused configuration paths:
- models.danish_democracy_data.intermediate
=== [dbt templater] Compiling dbt project...
=== [dbt templater] Project Compiled.
== [models\staging\stg_actor_types.sql] FAIL
L: 6 | P: 5 | PRS | Line 6, Position 5: Found unparsable section: 'qualify
| row_number() over (partition by ...'
How to reproduce
- save the sample sql into file example.sql
- use the sample .sqlfluff file
- Run sqlfluff lint against example.sql
Dialect
DuckDB
Version
sqlfluff, version 2.2.0
Configuration
.sqlfluff
[sqlfluff]
dialect = duckdb
templater = dbt
runaway_limit = 10
max_line_length = 80
indent_unit = space
exclude_rules = RF05
[sqlfluff:indentation]
tab_space_size = 4
[sqlfluff:layout:type:comma]
spacing_before = touch
line_position = trailing
[sqlfluff:rules:capitalisation.keywords]
capitalisation_policy = lower
[sqlfluff:rules:aliasing.table]
aliasing = explicit
[sqlfluff:rules:aliasing.column]
aliasing = explicit
[sqlfluff:rules:aliasing.expression]
allow_scalar = False
[sqlfluff:rules:capitalisation.identifiers]
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.functions]
capitalisation_policy = lower
[sqlfluff:rules:capitalisation.literals]
capitalisation_policy = lower
[sqlfluff:rules:ambiguous.column_references] # Number in group by
group_by_and_order_by_style = implicit
.sqlfluffignore
reports
target
dbt_packages
macros
extract-load
.dbtenv
.vscode
logs
Are you willing to work on and submit a PR to address the issue?
- [X] Yes I am willing to submit a PR!
Code of Conduct
- [X] I agree to follow this project's Code of Conduct
3) Specify Example Caching Directory
Repo : https://github.com/gradio-app/gradio
Specify Example Caching Directory
#5781

- [x] I have searched to see if a similar issue already exists.
Is your feature request related to a problem? Please describe.
Would be great to specify the directory gradio uses to cache examples. This would allow developers to save the cache to persistent storage on HF Spaces.
Describe the solution you'd like
Support specifying the cached directory via environment variable and a parameter in the examples class.
Additional context
Add any other context or screenshots about the feature request here.
4) Nits on the Getting Started page
Repo : https://github.com/gradio-app/gradio
Nits on the Getting Started page
#5778
- [x] I have searched to see if a similar issue already exists.
There are too many separate concepts in the "Sharing Your App" section of the getting started guide.

My Recommendation:
-
Mounting within another...should be under theSharing Your AppHeader - Pull
Authenticationinto another section and includePassword Protected...andOAuthinto that section -
Accessing the Network Requestfeels pretty random here. Maybe move toKey Features? -
Securityshould pulled out into its own section. -
Api Usageshould be pulled out into its own section.
5) [Integration] Integrate Lindorm with MindsDB
Repo : https://github.com/mindsdb/mindsdb
[Integration] Integrate Lindorm with MindsDB
#7887

The goal of this issue is to build a new handler that will connect MindsDB to Lindorm database from Alibaba.
Resources 💡
🏁 To get started, please refer to the following resources:
-
📚 Building Data Handler docs: This documentation will guide you through the process of building a custom handler for MindsDB. It contains essential information on the handler structure, methods, and best practices.
-
👉 ChromaDB: This existing handler connects MindsDB with ChromaDB.
-
You can find more examples of MindsDB's data handlers here.
Next Steps 🕵️♂️ 🕵️♀️
- You can familiarize yourself with Lindorm.
- Create a new handler that connects MindsDB to Lindorm.
- Implement the core features mentioned above.
- Thoroughly test the integration to ensure proper functionality.
- Submit a pull request with the new Lindorm Integration handler.
The PR should include the implementation of the Lindorm handler and unit tests.
📢 Additional rewards 🏆
Each data integration brings 2️⃣ 5️⃣ : points for SWAG and entry into the draw for a 👇 :
- 💻 Razer Blade 16 Laptop
- 👕 🐻 MindsDB Swag ℹ️ For more info check out https://mindsdb.com/hacktoberfest/ 👈
6) FolderBase Dataset automatically resolves under current directory when data_dir is not specified
Repo : https://github.com/huggingface/datasets
FolderBase Dataset automatically resolves under current directory when data_dir is not specified
#6152

Describe the bug
FolderBase Dataset automatically resolves under current directory when data_dir is not specified.
For example:
load_dataset("audiofolder")
takes long time to resolve and collect data_files from current directory. But I think it should reach out to this line for error handling https://github.com/huggingface/datasets/blob/cb8c5de5145c7e7eee65391cb7f4d92f0d565d62/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py#L58-L59
Steps to reproduce the bug
load_dataset("audiofolder")
Expected behavior
Error report
Environment info
-
datasetsversion: 2.14.4 - Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.17
- Python version: 3.8.15
- Huggingface_hub version: 0.16.4
- PyArrow version: 12.0.1
- Pandas version: 1.5.3
7) Create a Stimulus controller w-init to support initial classes
Repo : https://github.com/wagtail/wagtail
🎛️ Create a Stimulus controller `w-init` to support initial classes
#11071

Is your proposal related to a problem?
We have a small bit of JS that adds the class 'ready' to the body element when the DOM has loaded, this is useful for a few things such as styling elements as hidden until we know the JS is ready.
This pattern is used in a few places, such as the side panel JS where we want the panels to be hidden until we know the logic of the JS is loaded.
I propose a simple Stimulus solution to this that's similar to x-init and x-cloak from Alpine.js - where we use a controller to trigger this behaviour.
Describe the solution you'd like
- Create a new controller
InitControllerthat adds initial classes and also removes some classes based on data attributes when the JS is ready. - Use this new controller in
wagtail/admin/templates/wagtailadmin/skeleton.html - Remove our jQuery approach to this in
client/src/entrypoints/admin/core.js - The controller will be pretty simple but can be enhanced later for other usages such as the side panel when that work is being done.
- Testing is a must, remember that Jest
await jest.runAllTimersAsync();is your friend, seeclient/src/controllers/CloneController.test.jsfor some examples of tests that use this. - nice to have - Remove the initial-class code from the
RevealController- this is actually not required and better served with this generic approach when it comes time.
About timing & usage
Stimulus will connect controllers progressively based on the order of the data-controller and all controllers connect async, but as a microtask. This is slightly before a setTimeout would fire (it's a bit nuanced).
This gives us the ability to order our controllers in a way that the w-init will be last and hence will do its classes changes last.
<body data-controller="w-other w-init" data-w-init-ready-class="ready">
In the above code, w-other will connect first, w-init second.
Rough implementation
Here's a proposed implementation, it has ready and remove classes and the ability to configure the delay, default will be no delay except for the microtask / Promise resolving.
import { Controller } from '@hotwired/stimulus';
import { debounce } from '../utils/debounce';
/**
* Adds the ability for a controlled element to add or remove classes
* when ready to be interacted with.
*
* @example
* <div class="hide-me" data-controller="w-init" data-w-init-remove-class="hide-me" data-w-init-ready-class="loaded">
* When the DOM is ready, this div will have the class 'loaded' added and 'hide-me' removed.
* </div>
*/
export class InitController extends Controller<HTMLElement> {
static classes = ['ready', 'remove'];
static values = {
delay: { default: -1, type: Number },
};
declare readonly readyClasses: string[];
declare readonly removeClasses: string[];
declare delayValue: number;
/**
* Allow for a microtask delay to allow for other controllers to connect,
* then trigger the ready method.
*/
connect() {
Promise.resolve().then(() => {
this.ready();
});
}
ready() {
// if below zero (default) resolve immediately instead of using a setTimeout
const delayValue = this.delayValue < 0 ? null : this.delayValue;
// remember to call the result of `debounce` immediately, it returns a promise that can be used to dispatch a helpful event & allow this controller to remove itself
debounce(() => {
this.element.classList.add(...this.readyClasses);
this.element.classList.remove(...this.removeClasses);
}, delayValue)().then(() => {
this.dispatch('ready', { cancelable: false });
this.remove();
});
}
// To avoid this controller hanging around when not needed, allow it to remove itself when done
remove() {
const element = this.element;
const controllerAttribute = this.application.schema.controllerAttribute;
const controllers =
element.getAttribute(controllerAttribute)?.split(' ') ?? [];
const newControllers = controllers
.filter((identifier) => identifier !== this.identifier)
.join(' ');
if (newControllers) {
element.setAttribute(controllerAttribute, newControllers);
} else {
element.removeAttribute(controllerAttribute);
}
}
}
Describe alternatives you've considered
- We keep this logic ad-hoc in various bits of JS and avoid a generic solution.
Additional context
- This further enables us to move away from
core.jsbeing a grab-bag of ad-hoc jQuery - This enables additional prep for the Panels migration #10168
- See Alpine.js
x-init&x-cloakfor inspiration on the usage https://alpinejs.dev/directives/init & https://alpinejs.dev/directives/cloak - See HTMX's approach to generic 'load' events - https://htmx.org/docs/#events
8) Add "How to Install Gradio" in the docs page or Quickstart guide
Repo : https://github.com/gradio-app/gradio
Add "How to Install Gradio" in the docs page or Quickstart guide
#5444

- [X] I have searched to see if a similar issue already exists.
Is your feature request related to a problem? Please describe.
I wanted to Install gradio in my laptop(OS: Windows 10). As per the quickstart guide, it is showing to just write pip install gradio . I tried that, but after installing many packages, got an error:(screenshot attached)
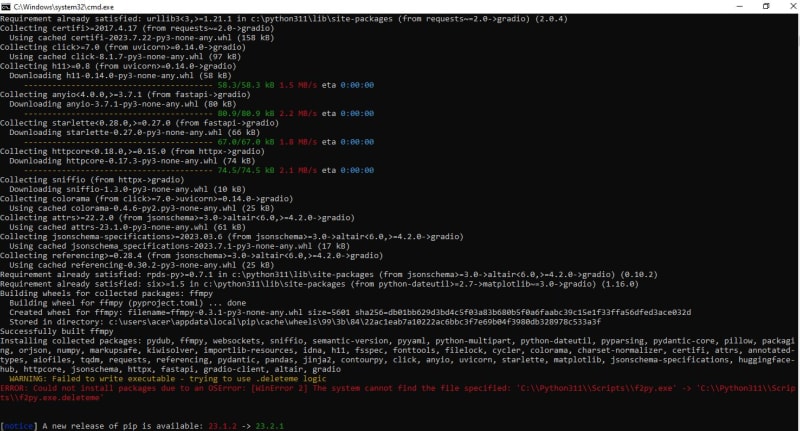
Describe the solution you'd like
I would like to see a "How to install guide" on the guides page or the quickstart guide page. Like, if the Windows users are facing this issue, or is it common for all. I saw a solution for the same error in the Streamlit app website, as they have a specific guide/instructions to install Streamlit in the virtual environment. Searched in the Gradio Website to see the same, but couldn't find it. I really want to install gradio and work on a ML Project.
Additional context
I would like to share the screenshot of the Streamlit installation page if it's allowed to.

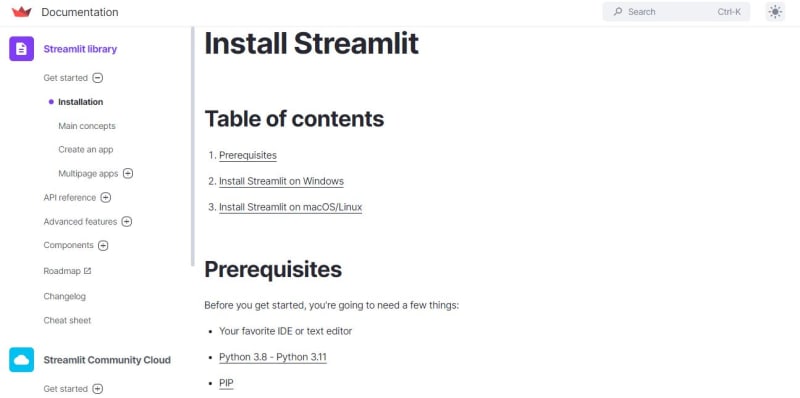
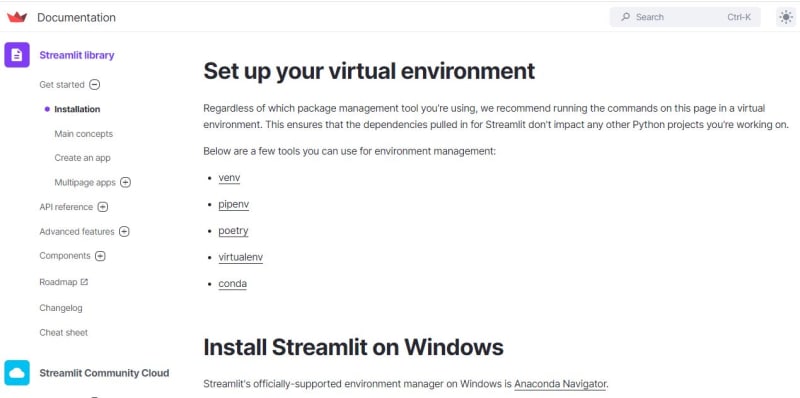
9) Stripe] Implement INSERT, UPDATE, and DELETE for the Payment Intents table
Repo : https://github.com/mindsdb/mindsdb
[Stripe] Implement INSERT, UPDATE, and DELETE for the Payment Intents table
#7874
MindsDB integrates with Stripe, so you can fetch data from Stripe and use it to make relevant predictions and forecasts with MindsDB.
Resources
Familiarize yourself with the existing Stripe integration: https://github.com/mindsdb/mindsdb/tree/staging/mindsdb/integrations/handlers/stripe_handler
Steps to Follow
The task is to extend this implementation to include the INSERT, UPDATE, and DELETE commands for the Payment Intents table.
📢 Additional rewards 🏆
Each integration extension brings 15+ points for SWAG and entry into the draw for a 👇 :
ℹ️ For more info check out https://mindsdb.com/hacktoberfest/ 👈
Please note that this issue is for first-time contributors to MindsDB
10) [REF-552] Reflex prints warning about Node binary not found
Repo : https://github.com/reflex-dev/reflex
[REF-552] Reflex prints warning about Node binary not found
#1778

Running reflex init inside a fresh python:3.11 docker contain prints the following warning twice
Warning: The path to the Node binary could not be found. Please ensure that Node is properly installed and added to your system's
PATH environment variable.
Which doesn't really make sense, because then it goes and bootstraps a version of node, which it then proceeds to use.
This warning should only be displayed if node is not installed, and Reflex is unable to bootstrap a version.
Present in 0.2.7a3
From SyncLinear.com | REF-552
11) Enhancement: Addition of a "UserFeedback" tool
Repo : https://github.com/TransformerOptimus/SuperAGI
Enhancement: Addition of a "UserFeedback" tool
#532

SuperAGI is built with a variety of tools that an agent can utilize based on its evaluation of the current situation. However, there is a gap when it comes to dynamic user interaction. This issue proposes the addition of a UserFeedback tool which the agent could invoke when it requires more information or guidance from the user.
In its current state, SuperAGI allows for different operational modes, such as "God Mode" for fully autonomous operation, and "Restricted Mode" which seeks user permissions before executing any tool. The UserInteraction tool would add a new dimension to this, allowing the agent to operate autonomously (like "God Mode") while also having the capability to actively seek user input at key milestones or decision points.
This would provide a more dynamic interaction model, enabling the agent to adapt to changing requirements or unexpected scenarios more effectively. It would also enhance the agent's ability to align with user expectations and objectives, making it a more versatile and useful tool for developers. The proposed UserInteraction tool could be integrated into the existing SuperAGI framework and made available for the agent to select as needed, just like the other tools currently at its disposal.
12) TypeError: Cannot read properties of undefined (reading 'split')
Repo : https://github.com/oppia/oppia
TypeError: Cannot read properties of undefined (reading 'split')
#18836

This error occurred recently in production:
TypeError: Cannot read properties of undefined (reading 'split')
at C.isLocationSetToNonStateEditorTab (router.service.ts:214:60)
at Je.<anonymous> (exploration-editor-page.component.ts:311:31)
at Generator.next (<anonymous>)
at exploration_editor.e5d90c2ddba5e4a20ea3.bundle.js:3987:43001
Where did the error occur? This error occurred in the exploration editor page.
Frequency of occurrence Add details about how many times the error occurred within a given time period (e.g. the last week, the last 30 days, etc.). This helps issue triagers establish severity. 2 times in 2 days.
Additional context
This errored occurred when the user was viewing the URL /create/XXX?story_url_fragment=YYY&topic_url_fragment=ZZZ&classroom_url_fragment=math&node_id=node_3#/.
General instructions for contributors In general, the procedure for fixing server errors should be the following:
- Analyze the code in the file where the error occurred and come up with a hypothesis for the reason.
- Based on your hypothesis, determine a list of steps that reliably reproduce the issue (or confirm any repro instructions that have been provided). For example, if your hypothesis is that the issue arises due to a delay in a response from the backend server, try to change the code so that the backend server always has a delay, and see if the error then shows up 100% of the time on your local machine.
- Explain your proposed fix, the logic behind it, and any other findings/context you have on this thread. You can also link to a debugging doc if you prefer.
- Get your approach validated by an Oppia team member.
- Make a PR that fixes the issue.
13) Auto-detect entered edition ID type
Repo : https://github.com/internetarchive/openlibrary
Auto-detect entered edition ID type
#8424

When adding a new book, it would be great if the ID type be automatically selected when entering the ID.
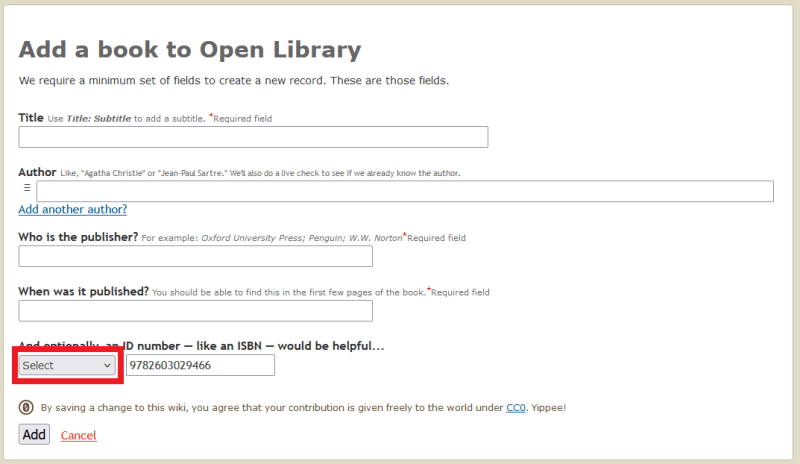
Describe the problem that you'd like solved
Proposal & Constraints
I'm thinking like it is done in the author edit page when entering an identifier with a recognizable pattern.
There is only 3 ID types allowed here (ISBN-10, ISBN-13 and LCCN). Could be also be extended to the edition edit page also, however there is a lot more ID types allowed.
Additional context
Stakeholders
14) Telegram Toolkit [Feature Request]
Repo : https://github.com/TransformerOptimus/SuperAGI
Telegram Toolkit [Feature Request]
#1196

⚠️ Check for existing issues before proceeding. ⚠️
- [X] I have searched the existing issues, and there is no existing issue for my problem
Where are you using SuperAGI?
MacOS
Which branch of SuperAGI are you using?
Main
Do you use OpenAI GPT-3.5 or GPT-4?
GPT-4(32k)
Which area covers your issue best?
Tools
Describe your issue.
This document outlines the features that can be added to the SuperAGI application to enable interaction with a Telegram account using a Telegram Toolkit. It provides the technical framework for integrating and operating various features in a Telegram bot with the SuperAGI application. The toolkit aims to offer functionalities such as message sending, receiving, managing chats, and more.
Requested Features:
1. Account Authentication
Description Enables SuperAGI to authenticate the Telegram user account.
API Methods
getMe
Workflow User inputs Telegram API token. Validate token by calling getMe.
2. Sending Messages
Description Send text and multimedia messages to individual users or groups.
API Methods
sendMessage
sendPhoto
sendAudio
sendVideo
Workflow Get chat ID. Prepare message or media. Call the appropriate API method.
3. Receiving Messages
Description Receive and process incoming messages from individual users or groups.
API Methods
getUpdates
setWebhook
Workflow Poll for new messages or set up a webhook. Process incoming message data.
4. Inline Keyboard and Custom Commands
Description Customize the chat interface with buttons and slash commands.
API Methods
sendMessage with InlineKeyboardMarkup
Workflow Create inline keyboard object. Attach to a message. Implement custom command functions.
5. File Handling
Description Send, receive, and process files like documents, spreadsheets, etc.
API Methods
sendDocument
getFile
Workflow Get chat ID. Prepare file. Call appropriate API method.
6. Chat Analysis
Description Analyze chat history and user behavior.
API Methods
getChat
getChatMembers
Workflow Get chat history and members. Run analytics functions.
How to replicate your Issue?
No
Upload Error Log Content
No
15) Fixed point intermediary type
Repo : https://github.com/SFTtech/openage
Fixed point intermediary type
#1545

Required Skills: C++
Difficulty: Medium
We could use an optional intermediary type for fixed-point types. Intermediary types are used for temporary values in calculations where intermediary steps can cause the original values to overflow. A common scenario where this can happen are multiplication or division. We take inspiration for this from the fpm library.
Intermediary types are only strictly necessary if the base type is small, e.g. int16_t. Therefore, their usage should be optional.
Tasks
- [ ] Add intermediary type as optional template parameter
- [ ] Use intermediary type in fixed-point calculations
Further Reading
16) Reflex Tuple class to fully support tuples
Repo : https://github.com/reflex-dev/reflex
Reflex Tuple class to fully support tuples
#1371

We need a ReflexTuple class just like ReflexDicts and ReflexLists.
Tuples need to be converted to lists to avoid render errors.
17) Make Document Embedders enrich Documents instead of recreating them
Repo : https://github.com/deepset-ai/haystack
Make Document Embedders enrich Documents instead of recreating them
#6107

Problem
When the Document Embedders were implemented, the Document class was frozen, so they are recreating Documents just to add the embedding to them.
Solution
Now, the Document class is unfrozen,
so we should simply do something like doc.embedding = emb
Components to refactor
OpenAIDocumentEmbedderSentenceTransformersDocumentEmbedder-
DONE:
InstructorDocumentEmbedder(in haystack-core-integrations)
18) Fixed point math constants
Repo : https://github.com/SFTtech/openage
Fixed point math constants
#1544
Required Skills: C++
Difficulty: Easy
It would be nice to have common math constants like pi defined using our fixed-point implementation, so that they can be used in fixed-point calculations with deterministic outcome. Floating point constants are already implemented here.
Tasks:
- [ ] Define existing math constants also as fixed point
Further Reading
19) [BUG] Adding model to existing plugin, existing plugin instances disappear
Repo : https://github.com/django-cms/django-cms
[BUG] Adding model to existing plugin, existing plugin instances disappear
#7476

Description
I have some simple plugins which are basically just templates to wrap child content, things like rows and columns. Usually they don't need a model. If the requirements of a plugin change and I do need a model for a plugin, adding a model will make all existing instances of a plugin disappear from the editor.
Steps to reproduce
`
@plugin_pool.register_plugin
class ColumnPlugin(CMSPluginBase):
name = _("Column")
# model = models.Column <-- adding model to plugin that already exists
render_template = "cmsplugin_column/cmsplugin_column.html"
allow_children = True
require_parent = True
parent_classes = ["RowPlugin"]
def render(self, context, instance, placeholder):
context = super().render(context, instance, placeholder)
return context
`
- create the plugin above, initially without a model
- create a couple instances of the plugin on the page
- add the model to the plugin ( uncomment the commented line above )
- plugins will disappear from the page
Expected behaviour
I would expect that either plugins show up, but without any settings, or that some error displays, indicating that some plugins dont have corresponding model isntances.
Actual behaviour
Plugins disappear without any warning or indication
Additional information (CMS/Python/Django versions)
django==3.2.14 django-cms==3.11.0
Do you want to help fix this issue?
Could this be solved via an manage.py command that creates default model instances for plugins that hove none? I could help creating a manage.py command if I had some guidance how to correctly query for this case.
- [ ] Yes, I want to help fix this issue and I will join #workgroup-pr-review on Slack to confirm with the community that a PR is welcome.
- [x ] No, I only want to report the issue.
20) Link section for disabling file based logging to Databricks docs
Repo : https://github.com/kedro-org/kedro
Link section for disabling file based logging to Databricks docs
#2978

Description
- The docs on logging are kind of hidden away. This page with all the information about the logging setup does not show up on the landing page for logging but is visible in the side bar.
- It's also worth linking the section for disabling file based logging to the deployment docs - eg. The Databricks docs and recommending disabling file based logging for read-only Databricks repos. Not everyone starts with the
databricks-irisstarter. - We had this as a note in the old docs - https://docs.kedro.org/en/0.18.10/deployment/databricks/databricks_workspace.html#databricks-notebooks-workflow
21) docs: replacement of exit command with creation of .kube directory and usage of newgrp
Repo : https://github.com/canonical/microk8s
docs: replacement of exit command with creation of .kube directory and usage of newgrp
#3779

Summary
As discussed in last community meeting a change in the tutorial section under this link in which while getting a error when installing microk8s it is advised to - "To validate the changes you can exit the VM’s shell and log in again." which is not a good practice and can be replaced by using newgrp.

What Should Happen Instead?
Instead of using exit command, a directory named ".kube" can be made if doesn't exit in the current VM and then the commands shown in the screenshot should be copy and pasted in the terminal followed by newgrp microk8s
Reproduction Steps
- Launch a new VM using
multipass launch --name <vm-name> --mem 4G --disk 40G - Shell into that VM using
multipass shell <vm name> - Install microk8s in that VM using
sudo snap install microk8s --classic - Run
microk8s status --wait-ready
Can you suggest a fix?
To overcome this error usage of newgrp is a better than using exit and re-enter
Are you interested in contributing with a fix?
yes
22) [BUG] COCO export: Instance Segmentations OOB wrt their bounding box
Repo : https://github.com/voxel51/fiftyone
[BUG] COCO export: Instance Segmentations OOB wrt their bounding box
#2847

Instructions
Thank you for submitting an issue. Please refer to our issue policy for information on what types of issues we address.
- Please fill in this template to ensure a timely and thorough response
- Place an "x" between the brackets next to an option if it applies. For example:
- [x] Selected option
- Please delete everything above this line before submitting the issue
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04
-
Python version (
python --version): 3.10.10 -
FiftyOne version (
fiftyone --version): 0.20.0 - FiftyOne installed from (pip or source): pip
Commands to reproduce
def check_ann(ann):
bb = ann['bbox']
segall = ann['segmentation']
bbxyxy = bb.copy()
bbxyxy[2] += bbxyxy[0]
bbxyxy[3] += bbxyxy[1]
for seg in segall:
seg = np.array(seg,dtype=np.float64).reshape((len(seg)//2),2)
#print(seg1)
orx0 = seg[:,0]<bbxyxy[0]
orx1 = seg[:,0]>bbxyxy[2]
ory0 = seg[:,1]<bbxyxy[1]
ory1 = seg[:,1]>bbxyxy[3]
if np.any(orx0):
print(f'x0, {seg[orx0,0]} against {bbxyxy[0]}')
if np.any(orx1):
print(f'x1, {seg[orx1,0]} against {bbxyxy[2]}')
if np.any(ory0):
print(f'y0, {seg[ory0,1]} against {bbxyxy[1]}')
if np.any(ory1):
print(f'y1, {seg[ory1,1]} against {bbxyxy[3]}')
return seg, bbxyxy
PATH = '/home/allen/tmp/export_oiv7'
ds = foz.load_zoo_dataset('open-images-v7',max_samples=15,
split='validation',label_types=['segmentations'])
ds.export(export_dir=PATH,dataset_type=fo.types.COCODetectionDataset)
ds2 = fo.Dataset.from_dir(dataset_dir=PATH,dataset_type=fo.types.COCODetectionDataset)
JSON = os.path.join(PATH,'labels.json')
with open(JSON) as fh:
j0 = json.load(fh)
for aidx,ann in enumerate(j0['annotations']):
print(aidx)
check_ann(ann)
Output:
0
x0, [752.5] against 753.651712
1
2
3
y0, [154.5 153.5] against 154.77248
4
5
y0, [350.5 351. ] against 351.99974399999996
6
x0, [266.5 266.5] against 267.327488
y0, [166.5 167.5] against 167.727725
7
y0, [86.5] against 87.560681
8
y0, [71.5 71.5] against 72.42499
9
y0, [468.5] against 469.25214600000004
10
x0, [102.5 103.5] against 103.999488
y0, [86.5 86.5] against 87.999744
... snip ...
Describe the problem
Exporting instance segmentations via COCODetectionDataset can result in segmentations that go out of bounds with respect to their bounding box by up to ~1.5px. This may cause an issue for some training pipelines and/or represent a small loss in accuracy.
I investigated one of the original COCO datasets downloaded from cocodataset.org and this issue was not present. So round-tripping through FO (importing and then re-exporting) likely causes the slight discrepancies.
What areas of FiftyOne does this bug affect?
- [ ]
App: FiftyOne application issue - [x]
Core: Core Python library issue - [ ]
Server: FiftyOne server issue
Willingness to contribute
The FiftyOne Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix for this bug to the FiftyOne codebase?
- [ ] Yes. I can contribute a fix for this bug independently
- [ ] Yes. I would be willing to contribute a fix for this bug with guidance from the FiftyOne community
- [ ] No. I cannot contribute a bug fix at this time
23) MarkdownToTextDocument (v2)
Repo : https://github.com/deepset-ai/haystack
`MarkdownToTextDocument` (v2)
#5669

This file converter converts each Markdown files into a text Document.
Draft I/O:
@component
class MarkdownToTextDocument:
@component.output_type(documents=List[Document])
def run(self, paths: List[Union[str, Path]]):
... loads the content of the files ...
return {"documents": documents}
In order to ease preprocessing, this converter should also extract metadata from the files while converting them into Documents.
Some information that can be gathered from the files may be:
- File name and file-related metadata
- Page numbers
- Headings and chapter information (implemented partially in v1 as well)
All this information should be "anchored" to the text by character index, if so needed. For example, it may look like this:
{
"pages": [
{"start": 0, "end": 2034},
{"start": 2034, "end": 3987},
...
],
"headings": [
{"text": "Chapter 1", "position:" 3, "level": 1},
{"text": "Paragraph 1", "position:" 203, "level": 2},
{"text": "Paragraph 2", "position:" 3203, "level": 2},
{"text": "Chapter 2", "position:" 10349, "level": 1},
....
]
}
Thank you for taking the time to read these issues. I hope you find them helpful. Make sure to contribute to open source during this month.
Here is a little bit about me: I'm Shreya, and I'm building Firecamp.
Firecamp 🔥
Opensource postman/insomnia alternative, helps developers in building APIs faster than ever!
I look forward to seeing you next week for another blog post.
Wishing you a great week ahead!

Top comments (2)
Nice Issues Shreya!
thanks nathan :)