- What is web? A-Web 1.0 B-Web 2.0 C-Web 3.0 2-How Web 2.0 works? A-Breaking parts of URL B-How does the browser lookup an IP address for the domain? C-How does the browser initiate a TCP connection with the server D-How does the browser send HTTP requests to the server? E-Server process request and sends a response to client F-How the browser renders content 3-Introduction to load balancer 4-Introduction to firewall 5-Conclusion
What is web?
According to Wikipedia, The World Wide Web (WWW), commonly known as the Web, is an information system where documents and other web resources are identified by Uniform Resource Locators, which may be interlinked by hyperlinks, and are accessible over the Internet.
The web has greatly improved (from web 1.0, web 2.0 and now the recent web 3.0) since it was first invented by Tim Berners Lee in 1989. This article will focus on web 2.0 and for that, we will see a brief of web 1.0 and web 3.0.
-------------------
Web 1.0
It is the "readable" phrase of the planet Wide Web with flat data. In Web 1.0, there's only limited interaction between sites and web users. Web 1.0 is just an information portal where users passively receive information without being given the chance to post reviews, comments, and feedback.
---------------
Web 2.0
It is the "writable" phrase of the planet Wide Web with interactive data. Unlike Web 1.0, Web 2.0 facilitates interaction between web users and sites, so it allows users to interact more freely with one another. Web 2.0 encourages participation, collaboration, and knowledge sharing. Samples of Web 2.0 applications are Youtube, Wiki, Flickr, Facebook, and so on.
---------------
Web 3.0
It is the "executable" phrase of Word Wide Web with dynamic applications, interactive services, and "machine-to-machine" interaction. Web 3.0 may be a semantic web which refers to the longer term. In Web 3.0, computers can interpret information like humans and intelligently generate and distribute useful content tailored to the requirements of users. One example of Web 3.0 is Tivo, a digital video recorder. Its recording program can search online and skim what it finds to you supported by your preferences.
That was a very broad view of the web. Let's narrow it down to the functionality and operation of web 2.0. Let's see the tech terms that we will be referring to in this article.
--------------------------
^Internet - the Internet is a vast network that connects computers all over the world.
^Internet Service Provider (ISP) - an organization that provides services for accessing, using, or participating in the Internet.
^Client - the user-agent; any tool that acts on behalf of the user. This role is primarily performed by the Web browser, but it may also be performed by programs used by engineers and Web developers to debug their applications.
^Client requests - queries sent to the server by the client.
^Resolver - a set of dynamic library routines used by applications that need to know machine names.
^Server - a piece of computer hardware or software that provides functionality for other programs or devices, called "clients".
^Webserver - is computer software with underlying hardware that connects to the Internet and supports physical data interchange with other devices connected to the web.
^Domain Name System (DNS) - the hierarchical and decentralized naming system used to identify computers, services, and other resources reachable through the Internet or other Internet Protocol networks.
^Internet Protocol address (IP) - a numerical label such as 192.0.2.1 that is connected to a computer network that uses the Internet Protocol for communication. An IP address serves two main functions: network interface identification and location addressing.
^Transmission Control Protocol (TCP) - a connection-oriented protocol that means it establishes the connection before the communication that occurs between the computing devices in a network. This protocol is used with an IP protocol, so together, they are referred to as a TCP/IP.
^HyperText Transfer Protocol (HTTP) - a protocol for fetching resources such as HTML documents. It is the foundation of any data exchange on the Web and it is a ^client-server protocol, which means requests are initiated by the recipient, usually the Web browser.
^Load balancer - a device/program that acts as a reverse proxy and distributes network or application traffic across many servers.
^Application server - a type of server designed to install, operate and host-associated services and applications for the IT services, end-users and organizations.
^Database - is an organized collection of structured information, or data, typically stored electronically in a computer system.
^Firewall - a network security system that monitors and controls the incoming and outgoing network traffic based on predetermined security rules.
-----------------'xxxxx--------------
How web 2.0 works
We'll look at what happens when you type a URL into your browser and press enter. End to end, the process involves the browser, your computer's operating system, your internet service provider, the server where you host the site, and services running on that server.
Websites are collections of files, often HTML, CSS, Javascript, and images, that tell your browser how to display the site, images, and data. They need to be accessible to anyone from anywhere at any time, so hosting them on your computer at home isn't be scalable or reliable. A powerful external computer connected to the Internet, called a server , stores these files.
When you point your browser at a URL like google.com your browser has to figure out which server on the Internet is hosting the site. It does this by looking up the domain, google.com, to find the address.
Each device on the internet is identified by its IP address. E.g 197.0.0.2 Series of numbers like this are hard to remember that's why domain names were invented to lessen the torture. Google.com is much easier to remember than 172.217.170.174 right?
With the evolution of domain names, DNS came along. DNS is like the Contacts app on our phone. DNS helps our browser find servers on the Internet. We can do a DNS lookup to find the IP address of the server based on the domain name, google.com
-----------------------------------
Breaking parts of URL
Up to this far, we have been referring to our demo URL as google.com but in a real sense, it has a hidden part that is autocompleted by your search upon a request. The complete URL appears ass https://google.com
Let's take a closer look at the URL. https:// is the scheme. HTTPS stands for Hypertext Transfer Protocol Secure. This scheme tells the browser to make a connection to the server using Transport Layer Security (TLS). TLS is an encryption protocol to secure communications over the Internet. With HTTPS, the data exchanged between your browser and the server, like passwords, credit card info etc, is encrypted. You may have also seen ftp://, mailto://, or file://. These are other protocols that browsers know how to handle.
The next part, google.com is a domain of the site. It is the memorable name that points to 172.217.170.174 server.
Some URLs contain more content after the domain. Eg https://beta-scribbles.tech/hello-world
/hello-world is the path on the server to the requested resource. You can think of the path as a directory structure of files and other directories on your computer. It's a way to organize your resources, whether they are static HTML, CSS, Javascript, image files, or dynamically generated content.
We now know that when you type google.com and press enter, the browser will look up the IP address of the domain. How will the process go about?
----------------------------
How does the browser lookup an IP address for the domain?
After you've typed the URL into your browser and pressed enter, the browser needs to figure out which server on the Internet to connect to. To do that, it needs to look up the IP address of the server hosting the website using the domain you typed in. It does this using a DNS lookup. You can read more about how DNS works here.
Because DNS is complex and has to be blazingly fast, DNS data is cached at different layers between your browser and various places across the Internet. Your browser checks its cache, the operating system cache, a local network cache at your router, and a DNS server cache on your corporate network or at your internet service provider (ISP). If the browser cannot find the IP address at any of those cache layers, the DNS server on your corporate network or at your ISP does a recursive DNS lookup. A recursive DNS lookup asks multiple DNS servers around the Internet, which in turn ask more DNS servers for the DNS record until it is found.
Once the browser gets the DNS record with the IP address, it's time for it to find the server on the Internet and establish a connection. How is this connection established?
-----------_____-------------
How does the browser initiate a TCP connection with the server?
Using the public Internet routing infrastructure, packets from a client browser request get routed through the router, the ISP, through an internet exchange to switch ISPs or networks, all using transmission control protocol (TCP) to find the server with the IP address to connect to at port 443. Once the browser has established a connection with the server, a Secure Socket Layer (SSL) certificate is generated to denote the domain as secured. The next step is to send the HTTP request to get the resource or the page. How is the request made?
-----------///////------------
How does the browser send HTTP requests to the server?
Now that the browser has a connection to the server, it follows the rules of communication for the HTTP(s) protocol. It starts with the browser sending an HTTP request to the server to request the contents of the page. The HTTP request contains a request line, headers (or metadata about the request), and a body. The request line contains information that the server can use to determine what the client (in this case, your browser) wants to do.
The request line contains the following:
-a request method, which is one of GET, POST, PUT, PATCH, DELETE, or
- a handful of other HTTP verbs -the path, pointing to the requested resources the HTTP version to communicate with
For a broader explanation, see here👉👉 https://developer.mozilla.org/en-US/docs/Web/HTTP/Session So what happens after the server has received the client's request?
---------$$$$$$$$------------
Server process request and sends a response to client
The server takes the request and based on the info in the request line, headers, and body then decides how to process the request. It fetches the requested content from the available database.
The response contains the following:
a status line, telling the client the status of the request
response headers, telling the browser how to handle the response
the requested resource at that path, either content like HTML, CSS, Javascript, or image files, or data
Resources can be static files, either text (HTML files) or non-text data (images). Browsers aren't always requesting static files, though. Often, these are dynamic resources generated at the time of the request and there is no file associated with the resource. The browser renders the content afterwards.
-------------'xxxxxxxx---------
How the browser renders content?
Once the browser has received the response from the server, it inspects the response headers for information on how to render the resource. The Content-Type header above tells the browser it received an HTML resource in the response body.
Sometimes, there is a lot of traffic of clients requests to servers (you are typing google.com, other people are typing so much more). To improve the efficiency of servers and reduce loading time, a load balancer is used.
-------------%%%%%%%------------
Introduction to load balancer
A load balancer intelligently distributes traffic from clients across multiple servers without the clients having to understand how many servers are in use or how they are configured. Because the load balancer sits between the clients and the servers it can enhance the user experience by providing additional security, performance, resilience and simplifying scaling your website.
Load balancers perform many functions in addition to just splitting traffic across servers, among them are: HTTP reverse proxy, Traffic and routing optimisation algorithms, Image caching (reducing web server load), Content caching
Your request to view google.com will be equally balanced with all other available requests from other clients. The load balancer will allocate a server for you.
Now that you know how requests are balanced using a load balancer, let's see something else. How can you prevent unauthorized access to your website?
---------&&&&&&&&&&-------------
Introduction to firewall!
A firewall is a security device — computer hardware or software — that can help protect your network by filtering traffic and blocking outsiders from gaining unauthorized access to the private data on your computer.
Not only does a firewall block unwanted traffic, but it can also help block malicious software from infecting your computer.
Firewalls can provide different levels of protection. The key is determining how much protection you need.
The image below is a summary of the whole process.
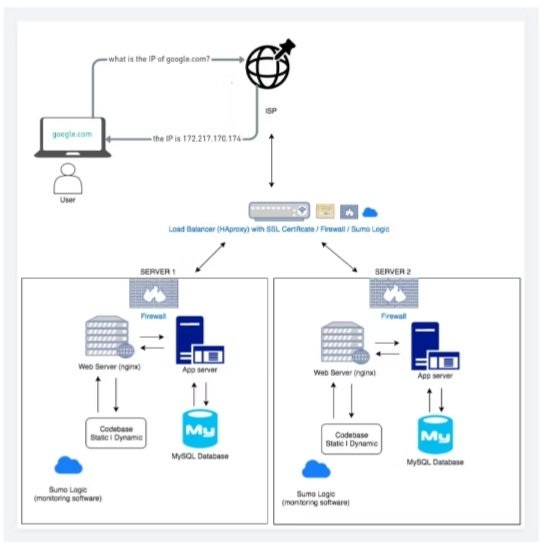
👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉
Conclusion
You have learned about the web 2.0 architecture, how the pieces communicate together to receive clients requests, establish connections between servers and clients, balance requests between servers, how resources are served to clients by servers, and finally, you were introduced to the concept of a firewall.
I hope this tour has increased your understanding of the web like a spiderman





Top comments (0)