In this article, we’ll figure out how to create slugs. Not the slobbery kind of little gastropods that crawls on the ground. Instead, we’ll see how to create the short hyphened text you can see in the URL of your web browser, and that is often a URL-friendly variation of the title of the article.
Interestingly, one of the most popular posts on my blog is an almost 20 year old article that explains how to remove accents from a string. And indeed, in slugs you would like to remove accents, among other things.
So what problem are we trying to solve today? Let’s say you have an article whose title is “L’été, où est tu ?”(which translates to: “Summer, where have you been?”"). You want your blog to have a friendly URL that looks like the title, but without the punctuation, or the accents (also called diacritical marks), and you also want to replace spaces with hyphens. The final URL should then be https://myblog.com/l-ete-ou-est-tu.
A naive approach would be to try to replace all the letters with diacritical marks with their non marked equivalents. So don’t try to replace “é” with “e”, etc. You’ll likely miss some letters in some languages. A better approach is to take advantage of Unicode normalization.
If you are interested, you can learn more aboutunicode normalizationon the Unicode.org website. But in a nutshell, some letters, like accented letters, are a combination of a base letter, and a diacritical mark.
Let’s have a look at this image from the link above:
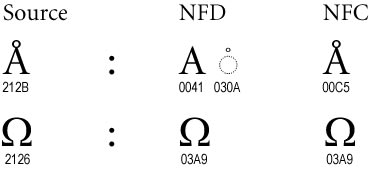
The uppercase angström letter is comprised of the A uppercase letter, and the ring above diacritical mark. The composed letter has a unicode value of U+212B but can be decomposed into U+0041 (uppercase A) and U+30A (ring above).
I’ll spare you from the details of the various normalization forms. But Java allows you to work with the normalized forms of letters thanks to the java.text.Normalizer class. We’ll also take advantage of Java’s regex Pattern class to identify particular classes of characters.
Be sure to check the Javadocs of the
NormalizerandPatternclasses:The former explains how to do string normalization, and the latter will give you the list of available character classes.
Let’s have a look at the following Java snippet:
import java.text.Normalizer;
String title = "L'été, où es tu ?"
Normalizer.normalize(title, Normalizer.Form.NFD)
.toLowerCase() // "l'été, où es tu ?"
.replaceAll("\\p{IsM}+", "") // "l'ete, ou es tu ?"
.replaceAll("\\p{IsP}+", " ") // "l ete ou es tu "
.trim() // "l ete ou es tu"
.replaceAll("\\s+", "-") // "l-ete-ou-es-tu"
My approach is usually the following:
- First, I normalize the text into the
NFDform (canonical decomposition), so base characters and diacritical marks are now separated, - Then, I’m replacing all the uppercase letters with lowercase ones,
- Next, we use the
IsMproperty which selects the the diacritical marks, and we remove them - Simiarly, we look at the characters which are punctuation, with the
IsPbinary property, and replace them with spaces - I usually trim the string at that point, as I don’t want to have spaces at the beginning or end of the strings (when a punctuation mark is replace with a space in the previous step)
- Eventually, all the space characters are replaced with hyphens.
Slugify
Recently, I came across a Java library that takes care of creating slugs: Slugify!
With Slugify, you can do a similar transformation as mine, with the following code:
import com.github.slugify.Slugify;
Slugify slugify = Slugify.builder().build();
slugify.slugify("L'été, où es tu ?") // "lete-ou-es-tu"
A small difference here is that the quote is removed, which leads to having the string lete instead of l-ete. I find that a bit less readable at a glance, but Slugify has various knobs you can tweak to customize its output.
There’s one particular thing I like about this library, it’s its use of theICU4J library, which supports transliteration (ICU is a well known set of libraries for full unicode and globalization support.)
The problem with our examples above is that they work well for language with latin-like alphabets. But my examples keep characters like ideograms intact, and Slugify removes them by default. If you want to have URLs that stay within the ASCII realm, you can use transliteration, which can map text in one language into readable latin-like text that sounds like the original text.
So if I wanted to transliterate my string into ascii-friendly text, I could use Slugify’s integration of ICU:
import com.github.slugify.Slugify;
Slugify slugify = Slugify.builder()
.transliterator(true) // use transliteration
.locale(Locale.ENGLISH)
.build()
slugify.slugify("夏よ、どこにいるの?") // "xiayo-dokoniiruno"





{kind=link}
Top comments (0)