Hoy en día resulta evidente el gran beneficio que la inteligencia artificial y, en particular, Machine Learning ofrece a la sociedad. Se trata de algo que no para de crecer en temas tan dispares como análisis facial, vehículos autónomos, interpretación de pruebas médicas, optimización de procesos, controles de calidad o determinar cómo se pliegan las proteínas.
Sin embargo, uno de lo principales problemas en los sistemas de aprendizaje automático es que los modelos estén sesgados. El sesgo puede tener unas consecuencias bastante negativas en función del contexto, como por ejemplo, cuando el algoritmo aplica criterios racistas o misóginos en sus predicciones. Hay ya demasiados ejemplos de estos problemas y por ello es muy importante entender cómo se producen estos sesgos y cómo combatirlos.
Hay una creencia generalizada de que el sesgo algorítmico es un problema exclusivo de los datos. Si los datos usados para entrenar tienen sesgo, el sesgo será aprendido por el modelo y, por lo tanto, eliminando o corrigiendo el sesgo presente en los datos tendrá como consecuencia la corrección del sesgo del modelo. Esto es verdad pero no es toda la verdad. Puede haber otras causas que acentúen este problema.
Veamos algunos ejemplos de cómo otras cosas pueden incrementar el sesgo dado un mismo conjunto de datos.
Poda y cuantificación de redes neuronales (pruning and quantification)
La poda y la cuantificación de redes neuronales son recursos cada vez más populares por las limitaciones de los entornos de ejecución en términos de latencia, memoria y energía.
Las técnicas de cuantificación consiguen una compresión muy significativa mientras el impacto en las métricas de desempeño mas populares suele ser insignificante. La cuantificación es una técnica de aproximación de una red neuronal que utiliza números de punto flotante mediante otra red neuronal que usa números de menor precisión. Esto reduce drásticamente tanto el requisito de memoria como el coste computacional del uso de redes neuronales. Sin embargo, si bien es cierto que la precisión general no se vea afectada, esta apreciación oculta un error desproporcionadamente alto en pequeños subconjuntos de datos. En esta publicación, titulada “Characterising Bias in Compressed Models”, Sara Hooker de Google Brain y otros exploran este tema y proponen técnicas para detectar este potencial problema. A este subconjunto de datos lo llaman Ejemplares Identificados por Compresión (CIE del inglés Compression Identified Exemplars) y establecen que para estos subconjuntos, la compresión amplifica enormemente el sesgo algorítmico existente.

Fuente: https://arxiv.org/pdf/2010.03058.pdf

Fuente: https://arxiv.org/pdf/2010.03058.pdf
De forma parecida, la poda de redes neuronales reducen el tamaño de la red sin apenas impacto en las métricas de la red neuronal, pero también pueden incrementar de forma desproporcionada el error en pequeños subconjuntos de datos infra-representados, en este caso llamados PIE (Pruning Identified Exemplars). En “What Do Compressed Deep Neural Networks Forget?” se muestra cómo se produce una sobre indexación en los PIE y proponen una metodología para detectar los ejemplos atípicos para tomar medidas adecuadas.

Fuente: https://arxiv.org/pdf/1911.05248.pdf
Los ejemplos difíciles se aprenden más tarde
En este artículo, "Estimating Example Difficulty Using Variance of Gradients", Chirag Agarwal, Sara Hooker definen una puntuación escalar como proxy para medir cómo de complicado es para una red neuronal aprender un ejemplo concreto. Usando esta puntuación que llaman Variance of Gradients (VOG) pueden ordenar los datos de entrenamiento según su dificultad para ser aprendidos.

Fuente: https://arxiv.org/pdf/2008.11600.pdf
En redes con exceso de parámetros se ha visto que se puede llegar a cero errores mediante la memorización de ejemplos. Esta memorización se produce más tarde durante el entrenamiento y las técnicas propuestas en el artículo ayuda a discriminar que elementos del dataset son especialmente difíciles y deben, por tanto, ser memorizados. La memorización de datos puede presentar riesgos de privacidad cuando los datos tienen información sensible. Es interesante destacar que medidas como VOG permiten detectar datos atípicos o out-of-distribution (OOD).
Modelos que garantizan la privacidad diferencial tienen un efecto dispar en la precisión del modelo
La privacidad diferencial (Differential privacy o DP) en machine learning es un mecanismo de entrenamiento que minimiza las fugas de datos sensibles presentes en los datos de entrenamiento. Sin embargo, el coste de la privacidad diferencial es una reducción en la precisión del modelo que no afecta por igual a todos los ejemplos. La precisión sobre los que pertenecen a clases o grupos infrarrepresentados tiene una caída mucho mayor.
En “Differential Privacy Has Disparate Impact on Model Accuracy” demuestran como, por ejemplo, la clasificación de género tiene una precisión muy inferior en caras negras que en caras blancas y que en un modelo DP el gap de precisión es mucho mayor que en el modelo no-DP. Es decir, si el modelo original no es justo, esta característica se acentúa en el modelo con privacidad diferencial.
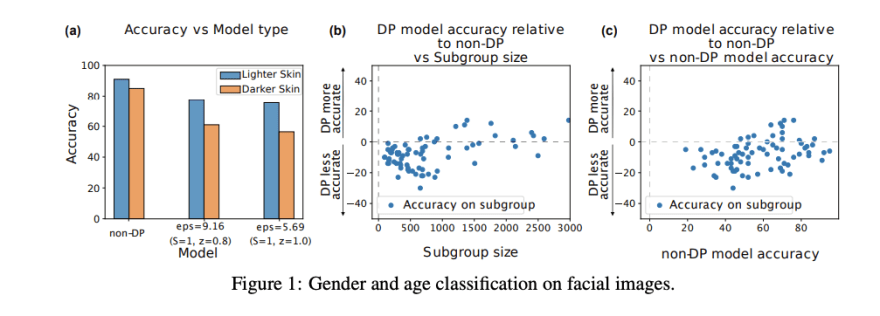
Fuente: https://arxiv.org/pdf/1905.12101.pdf
Conclusión
En los ejemplos anteriores se observa que combatir el sesgo en los modelos no es algo que se resuelva exclusivamente a nivel de datos (es importante notar que estos ejemplos distan mucho de ser exhaustivos). Al aplicar distintas técnicas populares sobre los modelos, se puede acentuar inadvertidamente el sesgo de los modelos. Entender, primero, y medir, después, este efecto negativo son los pasos necesarios para poder tomar las acciones adecuadas de corrección o compensación.
Fuentes
- Characterising Bias in Compressed Models [https://arxiv.org/abs/2010.03058] Sara Hooker, Nyalleng Moorosi, Gregory Clark, Samy Bengio, Emily Denton
- What Do Compressed Deep Neural Networks Forget? [https://arxiv.org/abs/1911.05248] Sara Hooker, Aaron Courville, Gregory Clark, Yann Dauphin, Andrea Frome
- Estimating Example Difficulty Using Variance of Gradients [https://arxiv.org/abs/2008.11600] Chirag Agarwal, Sara Hooker
- Characterizing Structural Regularities of Labeled Data in Overparameterized Models [https://arxiv.org/abs/2002.03206] Ziheng Jiang, Chiyuan Zhang, Kunal Talwar, Michael C. Mozer
- Differentially Private Fair Learning [http://proceedings.mlr.press/v97/jagielski19a/jagielski19a.pdf] Matthew Jagielski, Michael Kearns, Jieming Mao. Alina Oprea, Aaron Roth, Saeed Sharifi-Malvajerdi, Jonathan Ullman
- Differential Privacy Has Disparate Impact on Model Accuracy [https://arxiv.org/abs/1905.12101] Eugene Bagdasaryan, Vitaly Shmatikov
- Does Learning Require Memorization? A Short Tale about a Long Tail [https://arxiv.org/abs/1906.05271] Vitaly Feldman





Top comments (0)