Introdução
Na documentação do Kafka Streams temos a seguinte descrição: "Kafka Streams é uma biblioteca cliente para construir aplicações e microserviços onde a entrada e saída de dados são armazenados nos clusters do Kafka. Ele combina a simplicidade de escrever e subir aplicações Java e Scala no lado do cliente com os benefícios da tecnologia de clusters do lado do servidor do Kafka"
Isso significa que o Kafka Streams é uma ferramenta para processamento de fluxo de dados (streams) em tempo real que é integrada ao ambiente do Kafka. Possibilitando o processamento, transformação e persistência de dados em novos tópicos.
Nesse artigo será mostrado um exemplo onde uma aplicação conectada ao Kafka utiliza a biblioteca do Kafka Streams para executar o processamento dos dados.
O Projeto
Anteriormente em artigos passados foi mostrado como produzir mensagens com Kafka e como consumir mensagens com Kafka e agora vamos continuar com esse modelo onde o produtor irá enviar esses dados e tanto o consumidor simples quanto o nosso consumidor com Streams irá processar e para esse exemplo não iremos persistir em um novo tópico iremos apenas chamar um Processor que irá persistir em um banco de dados.
A visão geral de como os projetos se comunicam com o Kafka seria algo assim:
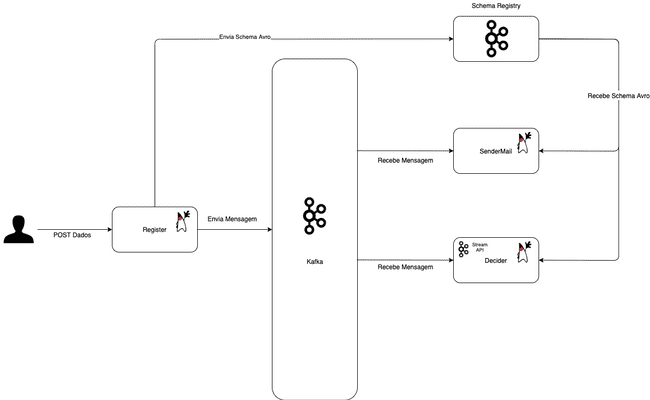
Iniciando o projeto
O projeto foi criado no site Spring Initializr como um projeto Maven e para usarmos o Kafka Streams precisamos adicionar as dependências do Apache e também foi adicionado as dependências da Confluent para poder ser usado o suporte que existe para Schema Registry como Serialização e Deserialização (SerDe):
<!-- https://mvnrepository.com/artifact/org.apache.avro/avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.1</version>
</dependency`
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<!--dependencies needed for the kafka part -->
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/io.confluent/kafka-avro-serializer -->
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>5.3.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
E também é necessário adicionar a tag que indica de onde deve ser baixado as dependências da Confluent:
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
Configurando Kafka Properties
O Kafka é todo baseado em configurações que passamos via Properties como no exemplo:
@Configuration
public class KafkaConfiguration implements MessageConfiguration {
@Autowired
private KafkaProperties kafkaProperties;
@Override
public Properties configureProperties() {
Properties properties = new Properties();
properties.put(APPLICATION_ID_CONFIG, kafkaProperties.getApplicationId());
properties.put(GROUP_ID_CONFIG, kafkaProperties.getGroupId());
properties.put(BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
properties.put(CLIENT_ID_CONFIG, kafkaProperties.getClientId());
properties.put(PROCESSING_GUARANTEE_CONFIG, kafkaProperties.getProcessingGuaranteeConfig());
properties.put(AUTO_OFFSET_RESET_CONFIG, kafkaProperties.getOffsetReset());
properties.put(DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, kafkaProperties.getTimeStampExtarctor());
properties.put(SCHEMA_REGISTRY_URL_CONFIG, kafkaProperties.getSchemaRegistryUrl());
properties.put(DEFAULT_KEY_SERDE_CLASS_CONFIG, kafkaProperties.getDefaultKeySerde());
properties.put(DEFAULT_VALUE_SERDE_CLASS_CONFIG, kafkaProperties.getDefaultValueSerde());
properties.put(SPECIFIC_AVRO_READER_CONFIG, kafkaProperties.isSpecficAvroReader());
return properties;
}
}
Das configurações acima vale ressaltar as seguintes:
- APPLICATION_ID_CONFIG: Um identificador único do processo no cluster do Kafka.
- GROUP_ID_CONFIG: O identificador do grupo de consumidores.
- BOOTSTRAP_SERVERS_CONFIG: Pode ser uma lista de url's de conexão com o cluster do Kafka.
- SCHEMA_REGISTRY_URL_CONFIG: Url de conexão do Schema Registry.
- DEFAULT_KEY_SERDE_CLASS_CONFIG: Definição do Serializador/Deserializador padrão para as chaves das mensagens.
- DEFAULT_VALUE_SERDE_CLASS_CONFIG: Definição do Serializador/Deserializador padrão para as mensagens.
- SPECIFIC_AVRO_READER_CONFIG: Indica que será usado uma classe específica para ler a mensagem Avro
Configurando o processamento
Quando recebermos os nossos dados de Taxpayer há uma informação sobre a situation do contribuinte. Podemos usar isso e definir um processador específico para cada situação do contribuinte; caso seja true será processado pela classe TaxpayerProcessorSituationTrue e caso seja false pela TaxpayerProcessorSituationFalse. Para esse exemplo vamos processar cada contribuinte, de acordo com a sua situation e salvar em um banco de dados para cada tipo de situação do contribuinte.
A API do Kafka Streams fornece uma interface chamada Processor para implementarmos um processador de dados e ainda temos uma abstração chamada AbstractProcessor que facilita ainda mais esse trabalho, então as classes ficam dessa forma para situation igual a true:
@Component
@Slf4j
public class TaxpayerProcessorSituationTrue extends AbstractProcessor<String, TaxPayer>{
@Autowired
private TaxpayerPort repository;
@Override
public void process(String key, TaxPayer value) {
log.info("Processing Taxpayer with situation :: " + value.getSituation());
ComplaintTaxpayer complaintTaxpayer = ComplaintTaxpayer.createDefaultedTaxpayer(value);
repository.save(complaintTaxpayer);
}
}
E para situation igual a false:
@Component
@Slf4j
public class TaxpayerProcessorSituationFalse extends AbstractProcessor<String, TaxPayer> {
@Autowired
private TaxpayerPort repository;
@Override
public void process(String key, TaxPayer value) {
log.info("Processing Taxpayer with situation :: " + value.getSituation());
DefaultedTaxpayer defaultedTaxpayer = DefaultedTaxpayer.createDefaultedTaxpayer(value);
repository.save(defaultedTaxpayer);
}
}
Configurando o Stream
Para configurar a Stream é necessário ser passado as Properties do cluster do Kafka, o nome do tópico e a configuração de SerDe:
StreamsBuilder streamsBuilder = new StreamsBuilder();
Serde<TaxPayer> taxpayerAvroSerde = new SpecificAvroSerde<>();
taxpayerAvroSerde.configure(getSerdeProperties(), false);
KStream<String, TaxPayer> stream = streamsBuilder.stream(getTopic(), Consumed.with(Serdes.String(), taxpayerAvroSerde));
Nesse trecho de código podemos ver que o Kafka possui um Builder para as nossas Streams, ela recebe o tópico e a combinação chave/valor da mensagem que será recebida. Como estamos trabalhando com Schema Registry definimos que o valor dessa mensagem será um Serde.
Com o objeto KStream podemos fazer várias manipulações dos dados que irão chegar aqui para podermos filtrá-los e encaminhar para o Processor certo vamos usar o método branch que nos devolverá o um Array:
KStream<String, TaxPayer>[] branch = stream.branch(
(id, tax) -> tax.getSituation() == false,
(id, tax) -> tax.getSituation() == true
);
No código acima usamos o método branch para fazer o nosso filtro por situation e podemos delegar para os Processors:
branch[0].process(() -> processorFalse);
branch[1].process(() -> processorTrue);
O exemplo completo dessa configuração:
@Autowired
private TaxpayerProcessorSituationTrue processorTrue;
@Autowired
private TaxpayerProcessorSituationFalse processorFalse;
private KafkaStreams kafkaStreams;
@Override
public String getTopic() {
return "taxpayer-avro";
}
@SuppressWarnings("unchecked")
@Override
public StreamsBuilder creataStream() {
StreamsBuilder streamsBuilder = new StreamsBuilder();
Serde<TaxPayer> taxpayerAvroSerde = new SpecificAvroSerde<>();
taxpayerAvroSerde.configure(getSerdeProperties(), false);
KStream<String, TaxPayer> stream = streamsBuilder.stream(getTopic(), Consumed.with(Serdes.String(), taxpayerAvroSerde));
KStream<String, TaxPayer>[] branch = stream.branch(
(id, tax) -> tax.getSituation() == false,
(id, tax) -> tax.getSituation() == true
);
branch[0].process(() -> processorFalse);
branch[1].process(() -> processorTrue);
return streamsBuilder;
}
private Map<String, String> getSerdeProperties() {
return Collections.singletonMap(SCHEMA_REGISTRY_URL_CONFIG, (String)kakfaConfiguration.configureProperties().get(SCHEMA_REGISTRY_URL_CONFIG));
}
Configurando o start
Com o Stream configurado é necessário fazer o start, onde será passado o Stream, as configurações do cluster Kafka, um handler de Exceptions e um hook para podermos lidar o shutdown da aplicação.
@PostConstruct
@Override
public void start() {
StreamsBuilder streamsBuilder = this.creataStream();
kafkaStreams = new KafkaStreams(streamsBuilder.build(), kakfaConfiguration.configureProperties());
kafkaStreams.setUncaughtExceptionHandler(this.getUncaughtExceptionHandler());
kafkaStreams.start();
this.shutDown();
}
@Override
public void shutDown() {
Runtime.getRuntime().addShutdownHook(new Thread(kafkaStreams::close));
}
private UncaughtExceptionHandler getUncaughtExceptionHandler() {
return (thread, exception) -> exception.printStackTrace();
}
Produzindo em um novo tópico
Um ponto muito utilizado quando se trabalha com Streams é o processamento, transformação e produção de novos fluxos de dados, então podemos simular o recebimento de uma mensagem de Taxpayer e transformamos o name pra lower case e enviamos para um novo tópico chamado name-lower-case-topic:
KStream<String, String> nameLowerCase = stream.mapValues(taxpayer -> taxpayer.getName().toLowerCase());
nameLowerCase.to("name-lower-case-topic");
Conclusão
Aqui foi mostrado uma forma de usar Kafka Streams porém essa biblioteca é muito extensa e tem muitos recursos, para mais informações consultar as documentações do Apache Kafka Streams e da Confluent Kafka Streams
Código fonte
O código fonte desse projeto pode ser encontrado no GitHub





Top comments (0)