It was hard for me to grasp the concept of JPA relations until I started to invest more time in it.
I will start with OneToOne, the easiest, what I find important in this relation is that we can insert ids for each participant making it bidirectional at no cost(except allocated space for parent id in child table).
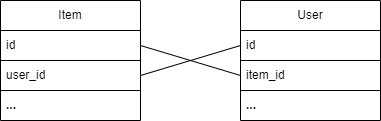
It is not necessarily to map OneToOne bidirectionally and it does make sense to map it LAZY otherwise N+1 problem is your friend if using JPA QueryBuilder. This is pretty strange because LAZY is the source for N+1. True, however you can choose if it is a hidden N+1 or a managed one. When query a Parent through QueryBuilder, if OneToOne child is eagerly connected, JPA will run a query to find all parents, will create a list of child ids and for each id will run a query to get each child details, so N+1 through EAGER. This is hidden, you can spot it just by verifying generated queries. Only by using LAZY, you will be able to fetch Parents only. And yes you will have to fetch explicitly each child, still within N+1, the only difference is that first example is unmanaged, done by JPA behind the counter, second one is managed, you are fully aware of what happens.
OneToMany is a bit complicated, and I wish I knew from the beginning that in order to not duplicate the rows in parent table, parent table id should be placed into the child not vice-versa. The reason is simple, if child id is placed in parent, parent has to replicate its rows for each child relation just because child id is present in parent table.
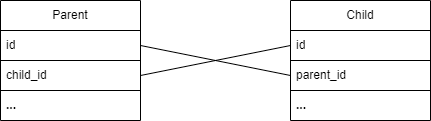
Here is how data in parent duplicates:

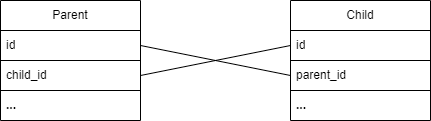
A better approach would be to map child to parent by parent id and live it as is. It becomes ManyToOne now.

And data is aligned as expected:

The join table for OneToMany is an overhead. Not only it becomes redundant, requires additional space, and adds up to the complexity, it is also a source to mistakenly transform it into a ManyToMany relation.

For OneToMany relation join table does not save allocated space:
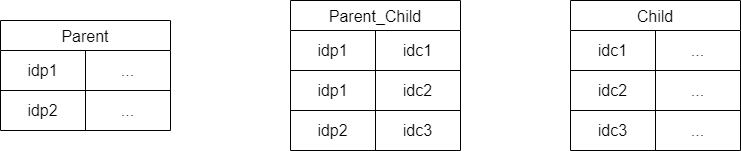
ManyToMany is where a join table helps. Its apparent complexity saves database space, without a join table database size will increase unjustifiably by replicating data.
Without join table:
Data is duplicated:
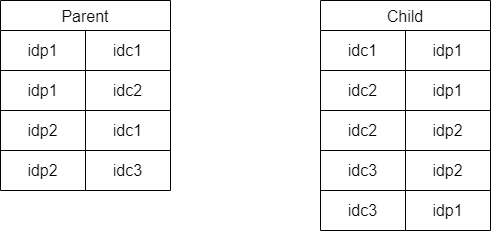
Moving to join table and schema becomes comprehensible:

Data also avoids redundancy except for ids:

Offtopic
Non relational databases are prone data replication issues. Mainly because it is hard to imagine a relational diagram. Though, not only non relational DBs are prone to this issue. Relational are too. For example if the architecture is based on Spark framework. The gain in performance by running tasks in parallel comes at the cost of removing foreign key relations from database. And when multiple DDL changes are made uncontrollably it is hard to imagine how data are linked. This is why Spark based architects run away from Hibernate/JPA, they will move to MyBatis or similar frameworks, even JDBC in this case would become a good choice. Most interesting is that after a while, Spark applications become Spark addictive. Due to data duplication it will be hard to optimize such databases. And the solution would be to increase the number of Spark workers. Unfortunately, even horizontal scaling is not indefinitely inflatable. It is easy to predict the refactoring to a new data storage solution, non relational inclusively, in this kind of projects.





Top comments (0)