Todays blog is a part of chapter 3 from the book "The Internals of PostgreSQL". This blog will introduce to the main subsystems of query processing.
Overview
PostgreSQL employs a single backend process to handle all queries sent by a client, although version 9.6 does use multiple background workers for parallel queries. The system supports a wide range of features in compliance with the 2011 SQL standard, with the query processing subsystem being the most complex. This system is divided into five subsystems.
- Parser
- Analyser/Analyzer
- Rewriter
- Planner
- Executor
Parser
The first subsystem in the backend process of PostgreSQL is the parser, which converts plain text SQL statements into a parse tree. The parse tree can then be processed by the other subsystems of the backend. An example of this process is provided
The parse tree will look like this for the query
testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;
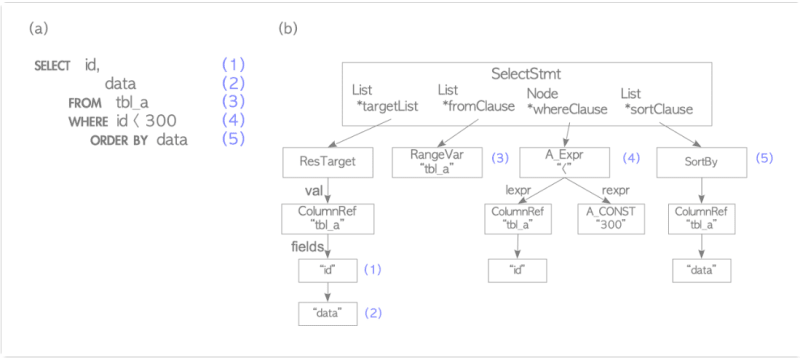
Parser doesn’t check the semantics of the input. This will be done in the next step by the analyzer.
Analyzer
The analyzer/analyser is responsible for performing a semantic analysis of the parse tree that is generated by the parser. The output of this process is a query tree. The root of this query tree is a Query structure defined in parsenodes.h, which contains metadata about the corresponding query, such as the type of command (SELECT, INSERT, or other). Each leaf of the query tree forms a list or a tree and contains data related to a particular clause of the query.
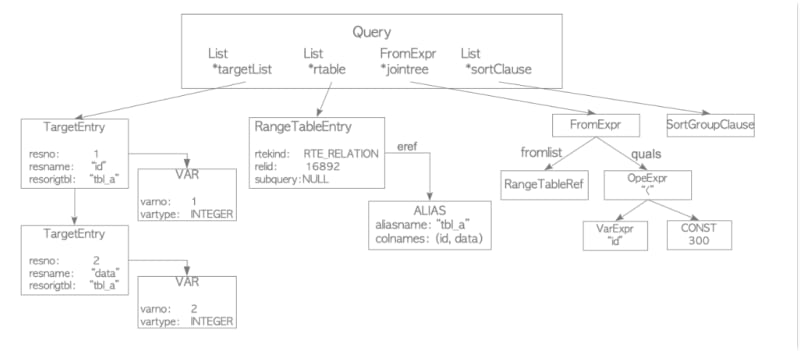
A simple example for the query tree.The query tree generated by the analyzer/analyser in PostgreSQL contains several elements. The targetlist contains the columns that will be included in the query result. In cases where the input query tree includes an asterisk, representing all columns, the analyzer/analyser replaces it with the full list of columns.
The range table holds information about the relations used in the query, such as the table OID and name. The join tree stores information about the FROM and WHERE clauses, and the sort clause is a list of SortGroupClause.
Overall, the query tree provides metadata about the query being executed, including its type and specific clauses, which is used by the subsequent subsystems in the backend process to plan and execute the query.
Rewriter
The PostgreSQL rewriter is responsible for implementing the rule system and modifying the query tree based on the rules stored in the pg_rules system catalog. This process is carried out if it is necessary for query optimization or to enforce data integrity constraints.
A simple example of the rewriter stage in the book

Planner and Executor
The planner receives a query tree from the rewriter and generates a plan tree that can be processed by the executor most effectively. The plan tree is composed of plan nodes that contain information required for processing by the executor. The executor reads and writes tables and indexes in the database cluster via the buffer manager, uses some memory areas, and creates temporary files if necessary. It also maintains consistency and isolation of the running transactions using a concurrency control mechanism.
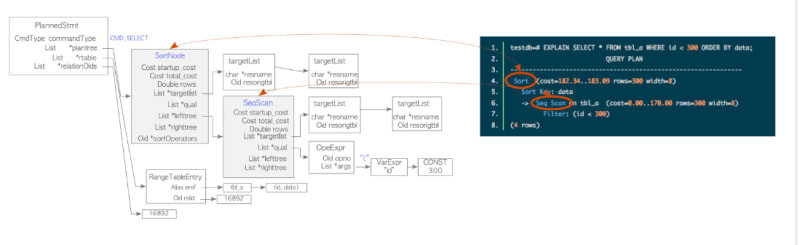
A simple plan tree and the relationship between the plan tree and the result.
Don't forget to checkout the book yourself as I only provide basic summaries to get you started.
Thats it for today I will return with some more easy to understand summaries.





Top comments (0)