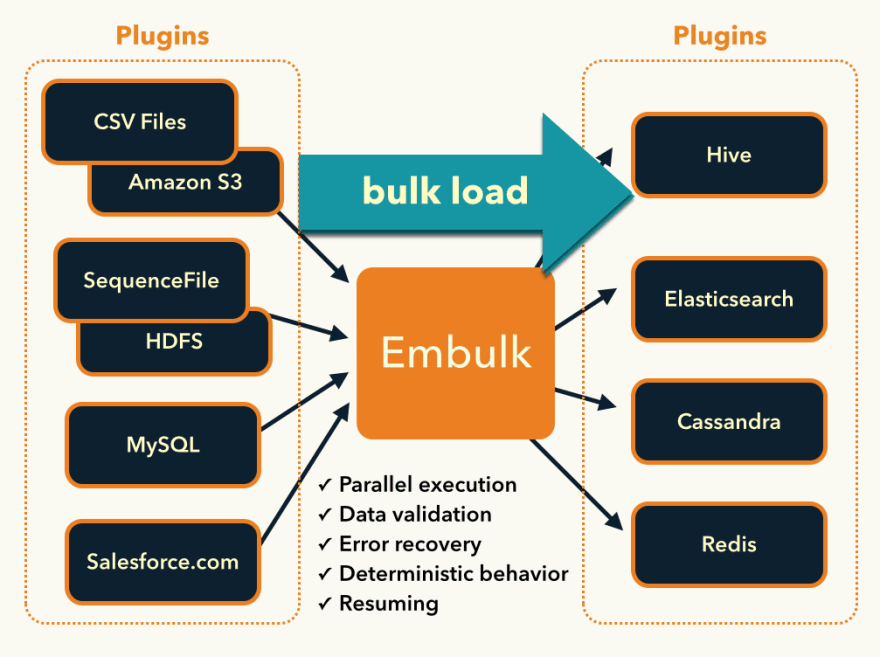
Embulk is an open-source bulk data loader that helps data transfer between various databases, storages, file formats, and cloud services.
I'm collecting Embulk knowledge in the World. Please let me know if you find useful information.
Hiroyuki Sato (twitter @hiroysato)
Official page.
Committer documents
- Embulk, an open-source plugin-based parallel bulk data loader
- Embuk internals
- Embulk Meetup keynote #2 Treasure Data, Inc. Sadayuki Furuhashi(@frsyuki)
Past events
- 2015-04-18 Fluentd and Embulk Study for gaming server. Masahiro Nakagawa
- 2015-07-31 JRuby with Java Code in Data Processing World tagomoris JRUBYCONF.eu presentation Video
- 2015-12-03 Loading data into Redshift - simplified with Schema-on-Read ELT (Slide)
- 2015-12-15 Embulk Meetup #2
- Embulk Meetup #2 keynote Treasure Data, Inc. Sadayuki Furuhashi (@frsyuki)
- Embulk at Treasure Data, Inc.
- 2016-03-30 Using Embulk at Treasure Data Treasure Data Inc. Muga Nishizawa Treasure Data Tech Talk in Japan.
- 2016-05-03 Fighting Against Chaotically Separated Values with Embulk csv,conf,v2 Treasure Data, Inc. Sadayuki Furuhashi (@frsyuki) (Video)
- 2018-10-12 Apache Airflow & Embulk (Antoine Augusti)
- 2019-05-02 Learning how to perform ETL data migrations with open source tool Embulk (Jason Bell)
Japanese documents.
Others
blog posts
- Treasure Data
- DZone
- AWS Big Data Blog
- drivy.engineering
- 2017-12-11 Embulk: move easily data across datasources





Top comments (0)