This post is originally published on our blog.
Recently our team has been working on a project with data crawling from various sites for pricing comparison. Our team has selected Puppeteer to implement. We have successfully built and delivered this solution to our customer, so I would like to write this article to share and provide some outlines steps to help you set up and have a try. I hope you enjoy it!
Why Puppeteer?
Per Google's documentation
Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
There are a couple of reasons why we've selected Puppeteer:
- Headless supported so easy to run on we can run on any container as serverless such as AWS Lambda, Azure Function, ECS.
- It is powerful, provides us a lot of commands and API.
- Easy to get started, we can automate input and navigation easily with a few lines of code. For our pricing crawler, inputs, actions, and navigation are required, therefore, using Puppeteer can help us.
- Node.js + TypeScript supported, we can utilize our automation development with Selenium, Protractor, Cypress skills.
- And much more, you can find out why people select Puppeteer over other tools by reading some articles below:
Our case study
The idea is we wanted to crawl pricing info from the online shop sites of trade-in mobile devices so that we can compare prices. End-user can select the best site for them. Once we crawled data from the sites, we need to write output in .csv file and upload to AWS S3 for archiving, we also need to archive output our database for reporting purpose.
Basically, Puppeteer can run on any serverless container such as AWS Lambda or Azure Function, but because of time limitations, we cannot running process longer than 15 minutes for AWS Lambda or 10 minutes for Azure Function that use Consumption plan. Basically, our crapper process took around 1 hour to finish. That is the reason we've selected AWS Fargate to run our crapper process.

Why AWS Fargate over other services?
AWS Fargate allows you to run containers without having to manage servers or clusters. With AWS Fargate, you no longer have to provision, configure, and scale clusters of virtual machines to run containers. Like AWS Lambda, AWS Fargate, there are no upfront payments and you only pay for the resources that you use. You pay for the amount of vCPU and memory resources consumed by your containerized applications.
Let's get started
Configure, and launch a Puppeteer crawler is pretty simple, so I will not mention how to do it in this article. In case if you don't know how to get started, then refer to this instruction for more details.
Example project
In order to help you easy to follow this article, I have created a sample project, you can find it on Github. This project is different from the above case study, but it is easy to understand and setup. This project contains two simple processes to generate pdf and screenshot for a URL then upload those files to an S3 bucket.
- First of all, you will need to clone our ecs-puppeteer-crawler-example repository from Github:
git clone git@github.com:innomizetech/ecs-puppeteer-crawler-example.git- Install node modules
cd ecs-puppeteer-crawler-example
npm install- Below is the code of the pdf generator pdf-generator.ts using Puppeteer and
import { archive } from './lib/s3-util';
import * as bluebird from 'bluebird';
import { emptyDirSync } from 'fs-extra';
const argv = require('yargs').argv;
const browserless = require('browserless')({
headless: !!argv.headless,
ignoreHTTPSErrors: true,
defaultViewport: null,
dumpio: false,
args: ['--disable-setuid-sandbox', '--no-sandbox']
});
if (!argv.url) {
console.log('Url is required');
process.exit(1);
}
const devices = browserless.devices.slice(0, 2);
const hostname = new URL(argv.url).hostname;
console.time('Finished in');
const generatePdf = async () => {
const generatePdfPerDevice = async device => {
console.log(
`${new Date().toUTCString()}: Generating pdf for ${device.name} device`
);
const buffer = await browserless.pdf(argv.url, {
waitUntil: ['load', 'networkidle2'],
fullPage: true,
device: device.name
});
const fileName = `output/${hostname} on (${device.name}).pdf`;
return { buffer, fileName };
};
const data = await bluebird.map(
devices,
device => generatePdfPerDevice(device),
{
concurrency: 5
}
);
await bluebird.map(data, item => archive(item));
console.timeEnd('Finished in');
process.exit(0);
};
emptyDirSync('output');
generatePdf();
- You can then generate .pdf for a URL such as https://www.innomizetech.com by running below command:
# --headless means we want to run without UI
env-cmd npx ts-node src/screenshot-generator.ts --url=https://www.innomizetech.com/ --headlessAnd here is the console output

The steps
Now you might wonder how to run, build, deploy and run your task on AWS ECS either manually or automation. So I wanted to outline the steps we need to perform to set up and run our example project on AWS Fargate.
- Build a docker image and upload it into ECR repo.
- Create an ECR repo to store docker images. Alternative you can use public docker hub.
- Setup VPC in case if you want to run your task under your private network. Otherwise, you can use default VPC on AWS. In this project, we use default VPC on a public subnet because our process doesn't contain any sensitive information, create a new VPC doesn't need, even add more cost if we run under a private subnet.
- Create an S3 bucket for achieving output files.
- Create task definition, ECS cluster and setup scheduled task to run our task (optional).
A lot of steps, right? Don't worry, I will show you how to automate those steps.
Infrastructure as code (IaC)
There are a couple of ways to automate your infrastructure on AWS cloud such as AWS CloudFormation, Terraform, AWS CDK. In this project, we use AWS CDK, I will have another article to provide more details about AWS CDK and why we use it for our IaC stuff.
Pre-requisites
Before continuing you need an AWS account. If you do not already have an AWS account, you can utilize their free-tier accounts. Follow Step 1: Prepare credentials on my article to configure your credentials to interact with AWS API via CLI. You also need to install AWS CLI and Docker on your machine.
Step 1 - Build docker and push to ECR
To run Puppeteer on AWS Fargate, we need a docker image. Below is our Dockerfile to build our Puppeteer code:
FROM node:10
RUN apt-get update
ENV HOME_DIR /usr/src/app
# for https
RUN apt-get install -yyq ca-certificates
# install libraries
RUN apt-get install -yyq libappindicator1 libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6
# tools
RUN apt-get install -yyq gconf-service lsb-release wget xdg-utils
# and fonts
RUN apt-get install -yyq fonts-liberation
RUN mkdir -p $HOME_DIR
RUN mkdir -p $HOME_DIR/views
WORKDIR $HOME_DIR
# Add our package.json and install *before* adding our application files to
# optimize build performance
ADD package.json $HOME_DIR
ADD package-lock.json $HOME_DIR
# install the necessary packages
RUN npm install --unsafe-perm --save-exact --production
COPY . $HOME_DIR
RUN npm run clean && npm run build
ENTRYPOINT ["/usr/local/bin/npm", "run"]
CMD ["clean"]To create an ECR repo, build, push a docker image to AWS ECR, use the build_and_push.sh script. This script also will check and create the repo for you if it doesn't exist yet.
#!/bin/bash
# This script is using to build and push docker image to ECR repository
AWS_PROFILE=development
REGION=us-east-2
REPO_NAME=ecs-puppeteer-crawler-example
TAG=latest
# Get the account number associated with the current IAM credentials
ACCOUNT_ID=$(aws sts get-caller-identity --profile $AWS_PROFILE --query Account --output text)
if [ $? -ne 0 ]
then
exit 255
fi
# If the repository doesn't exist in ECR, create it.
echo 'Checking repo existance...'
aws ecr describe-repositories --region $REGION --profile $AWS_PROFILE --repository-names "${REPO_NAME}" > /dev/null 2>&1
if [ $? -ne 0 ]
then
echo "Repo $REPO_NAME doesn't exist, try to create a new one"
aws ecr create-repository --repository-name "${REPO_NAME} --region $REGION --profile $AWS_PROFILE" > /dev/null
fi
echo 'Login to ECR Repository...'
$(aws ecr get-login --no-include-email --region $REGION --profile $AWS_PROFILE)
echo 'Building and pushing docker image to ECR repository...'
docker build -t $ACCOUNT_ID.dkr.ecr.$REGION.amazonaws.com/$REPO_NAME:$TAG .
if [ "$1" != "true" ]; then
docker push $ACCOUNT_ID.dkr.ecr.$REGION.amazonaws.com/$REPO_NAME:$TAG
fi
echo 'Publish docker image completed'Review and update the following parameters on the top of the script file according to your environment and AWS credentials
AWS_PROFILE=development
REGION=us-east-2
REPO_NAME=ecs-puppeteer-crawler-example
TAG=latestAnd then execute the script to create the repo, build docker and push to ECR
chmod +x scripts/build_and_push.sh
./build_and_push.shWait until the script finished, then you can find your docker image on the AWS ECR
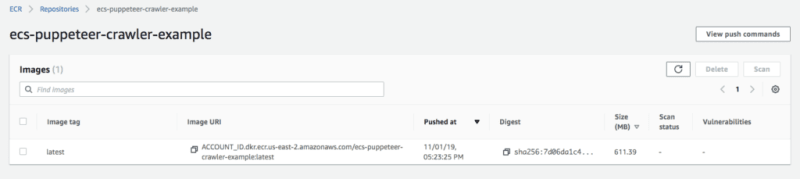
Step 2 - 5: Provision AWS service and run your task
As I have mentioned above, we can automate step #2 through #5 above by using the AWS CDK framework. I have created PuppeteerCrawlerFargateStack to construct all required resources
import cdk = require('@aws-cdk/core');
import ec2 = require('@aws-cdk/aws-ec2');
import ecr = require('@aws-cdk/aws-ecr');
import events = require('@aws-cdk/aws-events');
import ecs = require('@aws-cdk/aws-ecs');
import iam = require('@aws-cdk/aws-iam');
import { EcsTask } from '@aws-cdk/aws-events-targets';
import { PolicyStatement } from '@aws-cdk/aws-iam';
import { Bucket } from '@aws-cdk/aws-s3/lib/bucket';
import { PuppeteerCrawlerFargateStackProps } from './interfaces';
export class PuppeteerCrawlerFargateStack extends cdk.Stack {
constructor(
scope: cdk.Construct,
id: string,
props?: PuppeteerCrawlerFargateStackProps
) {
super(scope, id, props);
const vpc = this.constructVpc(props);
const cluster = new ecs.Cluster(this, 'PuppeteerCrawlerCluster', { vpc });
const bucket = this.constructArchiveBucket(props);
const taskDef = this.constructTaskDef(props, bucket);
// Create rule to trigger this be run task
new events.Rule(this, 'PuppeteerCrawlerSchedule', {
schedule: events.Schedule.expression(
props.scheduleExpression || 'cron(0/5 * * * ? *)'
),
description: 'Starts the puppeteer crawler job',
targets: [
new EcsTask({
cluster: cluster,
taskDefinition: taskDef,
subnetSelection: {
subnetType: ec2.SubnetType.PUBLIC
},
containerOverrides: [
{
containerName: 'PuppeteerContainer',
command: ['pdf']
}
]
}),
new EcsTask({
cluster: cluster,
taskDefinition: taskDef,
subnetSelection: {
subnetType: ec2.SubnetType.PUBLIC
},
containerOverrides: [
{
containerName: 'PuppeteerContainer',
command: ['screenshot']
}
]
})
]
});
}
private constructVpc(props: PuppeteerCrawlerFargateStackProps) {
if (props.useDefaultVpc) {
return ec2.Vpc.fromLookup(this, 'VPC', {
isDefault: true
});
}
return new ec2.Vpc(this, 'EcsFargateVPC', {
cidr: '172.15.0.0/16',
maxAzs: 1,
// natGateways: 1,
subnetConfiguration: [
{
cidrMask: 16,
name: 'Public',
subnetType: ec2.SubnetType.PUBLIC
}
// In case if you want to run your task under private subnet
// then uncomment below lines and change subnetSelection
// options above to PRIVATE
// {
// cidrMask: 20,
// name: 'Private',
// subnetType: ec2.SubnetType.PRIVATE
// }
]
});
}
private constructArchiveBucket(props: PuppeteerCrawlerFargateStackProps) {
return new Bucket(this, 'PuppeteerCrawlerArchiveBucket', {
bucketName: props.bucketName,
removalPolicy: cdk.RemovalPolicy.DESTROY
});
}
private constructTaskDef(
props: PuppeteerCrawlerFargateStackProps,
bucket: Bucket
) {
// Role for task
const taskRole = this.constructTaskRole(bucket);
const taskDef = new ecs.FargateTaskDefinition(
this,
'PuppeteerCrawlerTaskDefinition',
{
memoryLimitMiB: 8192,
cpu: 2048,
taskRole
}
);
const repo = ecr.Repository.fromRepositoryName(
this,
'PuppeteerCrawlerRepo',
props.repoName
);
taskDef.addContainer('PuppeteerContainer', {
image: ecs.ContainerImage.fromEcrRepository(repo),
logging: new ecs.AwsLogDriver({
streamPrefix: 'puppeteer-data-crawler',
logRetention: 1
}),
environment: {
S3_BUCKET: bucket.bucketName
}
});
return taskDef;
}
private constructTaskRole(bucket: Bucket) {
const taskRole = new iam.Role(this, 'EcsTaskRole', {
assumedBy: new iam.ServicePrincipal('ecs-tasks.amazonaws.com')
});
// Note: we can add more policy here
taskRole.addToPolicy(
new PolicyStatement({
resources: [bucket.bucketArn, `${bucket.bucketArn}/*`],
actions: ['s3:PutObject']
})
);
return taskRole;
}
}
Open the infra/app.ts file and make your desired changes then execute cdk deploy command to deploy and create resources on AWS
cd infra
cdk deployAn ECS cluster, an S3 bucket, and a CloudWatch schedule will be created automatically, you can find them on AWS Console Management
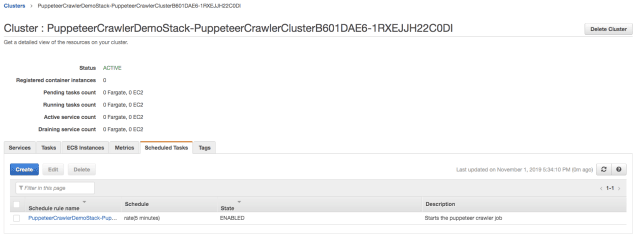
Wait for 5 minutes (default schedule expression from our Github code) then check the ECS Task execution logs on CloudWatch and also S3 bucket

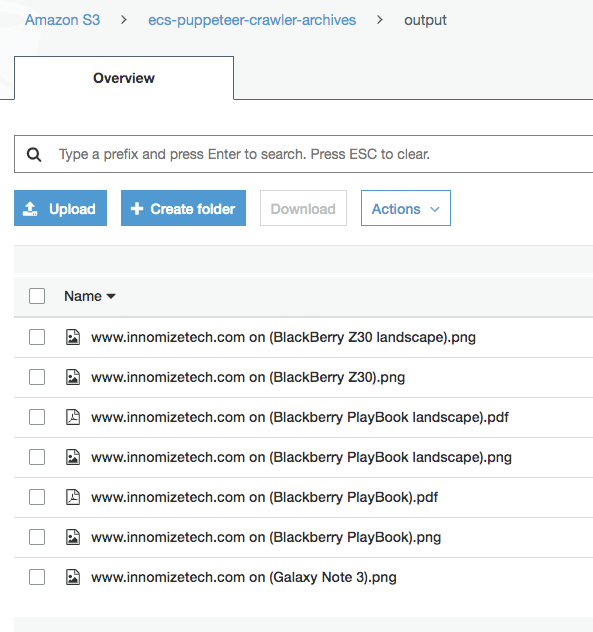
So far so good, I believe that within 10 minutes you will have a web crawler up and running. You can our setup and modify your Puppeteer codes based on your requirement. I also mentioned database archiving (i.e. MySQL or DynamoDB). To implement this, I have some options as below:
- Implement directly on the puppeteer code, you can use the bulkInsert function of the s3-util to insert bulk record to the database.
- Build a Lambda function trigger object create event of the archive S3 bucket.
Clean up
To avoid increasing your AWS bills, you need to clean up and remove resources on AWS:
- First, you need to empty your S3 bucket.
- Then delete AWS resource by running destroy command.
cd infra
cdk destroy- Finally, delete your ECS repo.
Summary
I know that this article is very long, but I wanted to provide detailed steps to help you understand step by step. Any suggestions and recommendations are welcome.
Should you run into issues while practicing the steps outlined in this article, I encourage you to reach out to me. You can get in touch with me through my Twitter handle @hoangleitvn
Visit our blog for more interesting articles. If you have any questions or need help you can contact me via Twitter.
If you are looking for developers, offshore team, or need consulting about the AWS cloud, Serverless architecture, and so on, then hire us, we can help you!
Thank you for reading!





Top comments (4)
For anyone interested in this post, we have updated our repo to remove the build and push the docker image to ECR manually (step #1) by using Docker Image Assets of the AWS CDK framework. So for now, deployment can be done by executing the following commands:
This is awesome! FYI if you add a lambda @edge component to this you get SEO! dev.to/danquack/caching-spas-for-s...
It sounds great.
Great article thanks for sharing