
Today, In this article I'll try to explain the Netflix API and how to get data about movies and tv shows :). I've been scraping a lot of popular streaming providers and Netflix was by the hardest one to get.
Falcor
Falcor is Netflix's JavaScript library, used for fetching data. If you want to read more about it, you can do it on their Github.
Inspecting the network
First, I'll look through the network and check what's happening, now if you've used Netflix you know they have auto playing videos everywhere, which causes a lot of requests as you scroll or click or whatever you're doing. I tried filtering down the endpoints/urls by typing "netflix".
At first you can see some of the auth links, but I'll ignore this for now. 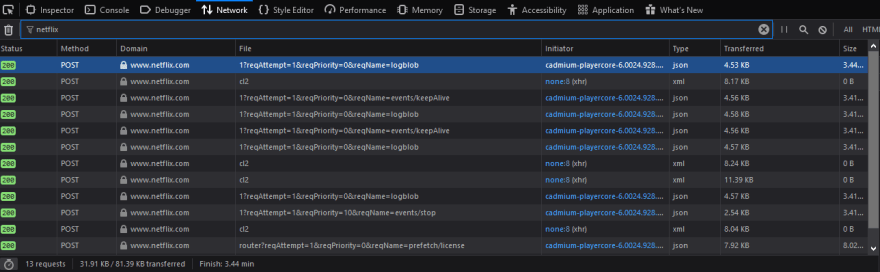 We need to find out how Netflix actually loads the videos and the data about them, so let's open this show for example and inspect the traffic.
We need to find out how Netflix actually loads the videos and the data about them, so let's open this show for example and inspect the traffic.
We can see there is a POST request to this url, 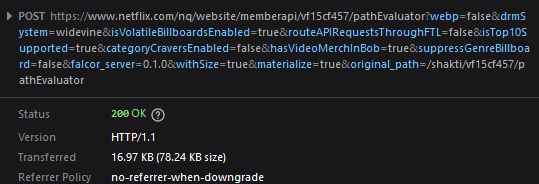 Checking the request data we can see what Netflix is sending.
Checking the request data we can see what Netflix is sending. 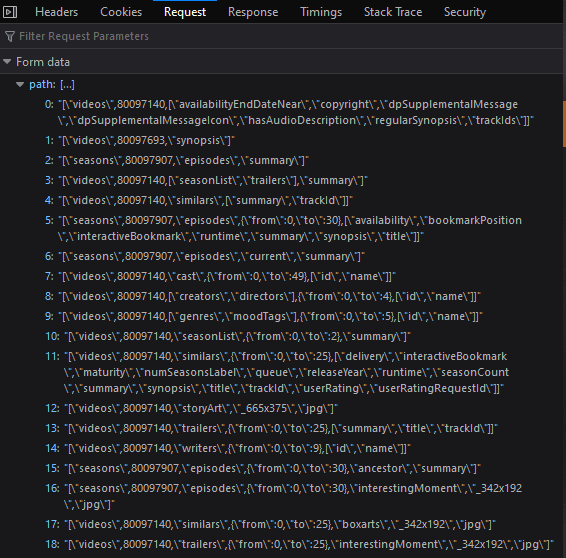 By inspecting the request headers we can see this is
By inspecting the request headers we can see this is application/x-www-form-urlencoded content-type, so in this case, our key will videos, which probably means, that's just Netflix differentiates this data. Looking at the url (https://www.netflix.com/browse?jbv=80097140) we can see that the ID is being passed next, and finally we have a list of what we want to get in response. Cool, looks like we have some of the info we need, but we need to a find a way to get these video IDs, we're not going to manually go over and copy them..
Let's search through the genres and see what traffic we're getting, Almost same as the first one, I clicked to check Anime genre and found this POST data in request, 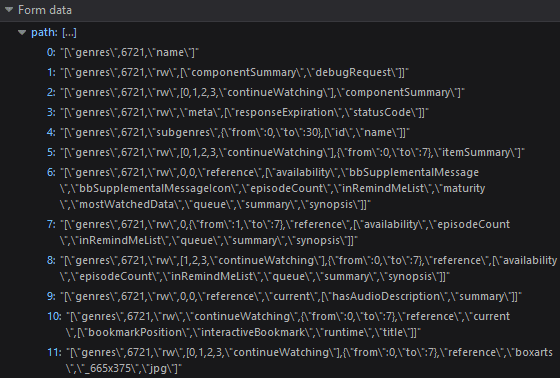
Well, well, same strategy as before, let's copy the request and check it out in Postman.
Analyzing the request headers
The headers are pretty much standard stuff, with some Netflix exceptions, however the most important is the Cookie. 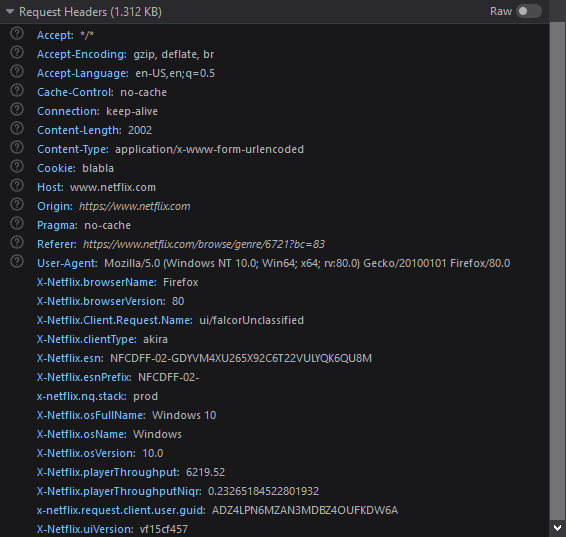 The cookie consists of 2 important token values, SecureNetflixId and NetflixID, these are passed in every request I've inspected and it looks like they're bound to the account, so you have to be subscribed to Netflix to hit those endpoints.
The cookie consists of 2 important token values, SecureNetflixId and NetflixID, these are passed in every request I've inspected and it looks like they're bound to the account, so you have to be subscribed to Netflix to hit those endpoints.
memclid={id}SecureNetflixId={SecureNetflixID}; NetflixId={NetflixId}; playerPerfMetrics=%7B%22uiValue%22%3A%7B%22throughput%22%3A6231.89%2C%22throughputNiqr%22%3A0.5994435164694499%7D%2C%22mostRecentValue%22%3A%7B%22throughput%22%3A6233.69%2C%22throughputNiqr%22%3A0.39654013276722966%7D%7D; OptanonConsent=isIABGlobal=false&datestamp=Wed+Jul+22+2020+11%3A06%3A12+GMT%2B0200+(Central+European+Summer+Time)&version=6.3.0&consentId=f0aa447b-7bc0-468f-a12e-e8f7f8acde23&interactionCount=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0004%3A1&hosts=H1%3A1%2CH2%3A1%2Cjyl%3A1%2CH7%3A1%2CH4%3A1%2CH6%3A1&AwaitingReconsent=false; _ga=GA1.2.616486459.1595596356; pas=%7B%22supplementals%22%3A%7B%22muted%22%3Atrue%7D%7D; profilesNewSession=0; clSharedContext=f89661b7-8d71-48cf-80ce-f53d4f1e959c; lhpuuidh-browse-ADZ4LPN6MZAN3MDBZ4OUFKDW6A=US%3AEN-US%3A648428ac-7104-4e30-83d9-b412c71e1910_ROOT; lhpuuidh-browse-ADZ4LPN6MZAN3MDBZ4OUFKDW6A-T=1596565541035
Looks like that's all we need for the headers.
Analyzing the URL
In the second image we saw the URL had some get queries, 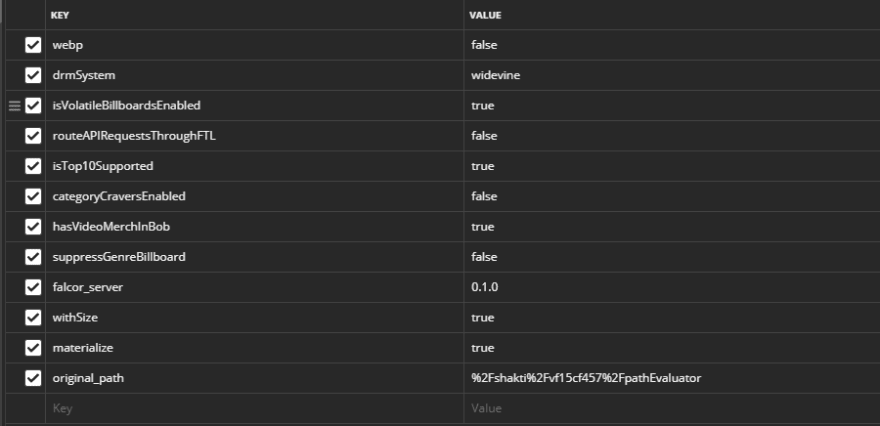 Mostly generic stuff, nothing catches eye here. So, we have everything we need, let's start making some requests and find more.
Mostly generic stuff, nothing catches eye here. So, we have everything we need, let's start making some requests and find more.
Making the first request
I copied the request as cURL and imported it in Postman, then I enabled only 1 key-value for our post data, because I don't want to get tons of data, baby steps.. 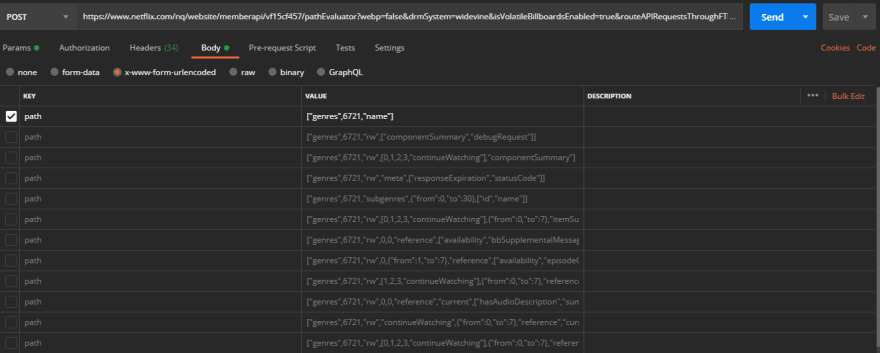 Hit send and voila! We get this response,
Hit send and voila! We get this response,
{
"jsonGraph":{
"genres":{
"6721":{
"name":{
"$type":"atom",
"value":"Anime Series"
}
}
}
},
"paths":[
[
"genres",
6721,
"name"
]
]
}
This looks right, right? Now let's play with the values and see if we can pull something else from that genre. Looks like there's a path that looks like this,
["genres",6721,"subgenres",{"from":0,"to":30},["id","name"]]
Let's try and modify it to our needs, now I'm not going to waste time how I found out the correct values and stuff, because that's all manual 'brute-forcing', if you want you can always brute force these endpoints.
["genres", 6721, {"from":0,"to":30}, "videos"]
so what does this means?Hey netflix, give me 30 videos from the genre ID 6721I'm not going to paste the whole response here, because it is quite long, but here's an example when fetching 3 videos,
{
"jsonGraph":{
"genres":{
"6721":{
"0":{
"$type":"ref",
"value":[
"videos",
"81002438"
]
},
"1":{
"$type":"ref",
"value":[
"videos",
"70205012"
]
},
"2":{
"$type":"ref",
"value":[
"videos",
"80050063"
]
},
"3":{
"$type":"ref",
"value":[
"videos",
"80095241"
]
}
}
},
"videos":{
"70205012":{
"videos":{
"$type":"atom"
}
},
"80050063":{
"videos":{
"$type":"atom"
}
},
"80095241":{
"videos":{
"$type":"atom"
}
},
"81002438":{
"videos":{
"$type":"atom"
}
}
}
},
"paths":[
[
"genres",
6721,
{
"from":0,
"to":2
},
"videos"
]
]
}
Judging by the first request we made we can see we're getting actual video IDs! Awesome, so all that's left is to find all genres and pull every video id, after that it's a cake.
Pulling the genres
Now, we all know Netflix has tons of hidden genres, we've seen a lot of articles, plugins etc, about them, but how do we get them? Of course we're not going to copy-paste or even scrape those sites, we want fresh data. There are few ways to do this.
Brute forcing genre ids
Well, duh! we can just brute force with the same path from above,
["genres",{id_here},{"from":0,"to":30}, "videos"]
..but how would that work? Simple! if there are no videos under certain id, Netflix will send back response with $type: "error", which looks something like this.
{
"jsonGraph":{
"genres":{
"4":{
"0":{
"$type":"error",
"value":{
"message":"Cannot invoke method withAnnotation() on null object",
"cause":"java.lang.NullPointerException: Cannot invoke method withAnnotation() on null object"
}
},
"1":{
"$type":"error",
"value":{
"message":"Cannot invoke method withAnnotation() on null object",
"cause":"java.lang.NullPointerException: Cannot invoke method withAnnotation() on null object"
}
}
}
}
},
"paths":[
[
"genres",
4,
{
"from":0,
"to":1
},
"videos"
]
]
}
Awesome, now it's matter of doing this till we hit 8 digits :). Which we can do quite fast, since we can put list of genre ids instead of just passing only 1 ID per request, should look something like this,
["genres",[1, 2, 3, 4, 5, 6, 7, 8],{"from":0,"to":30}, "videos"]
I actually did this at first with async requests and pulled around 90,000 different genres, and quite fast.
The other way
I was convinced brute forcing was the only way of pulling these genres, but I started playing with the API and managed to make a path that looks something like this,
["genreList",{"from":0,"to":1000}]
Hey Netflix, gimme genre list that has 1000 objects!!
This pulls total 137 genres! Will that be enough though? -nop_So what do we do? -_if you want reliable data, I'd say go with the brute forcing method, since some videos you can't find under some genres
Let's find some data now!
Pulling information about video titles
After playing with responses and looking at certain values, I constructed the following path,
["videos",{video_ids},["title", "runtime", "summary", "seasons", "releaseYear", "availability", "maturity", "mostWatchedData", "seasonCount", "episodeCount"]]
Same as genres we can pass multiple video ids and get data about them, max is 380, though. From the path you can see we're asking for some info like title of the show, the runtime etc.
Let's try for this ID,
["videos",80189685,["title", "runtime", "summary", "seasons", "releaseYear", "availability", "maturity", "mostWatchedData", "seasonCount", "episodeCount"]]
But also, let's pass another path,
["videos",80189685,"seasonList",{"from":0,"to":8},"id"]
Yep, that's right, we also want season list,_but simeon what if it's a movie, movies don't have seasons!!_yeah, well, remember the genres brute forcing method? if it's a movie, we simply don't care about it, as Netflix won't send us anything :). let's check the response,
{
"jsonGraph":{
"videos":{
"80189685":{
"title":{
"$type":"atom",
"value":"The Witcher"
},
"runtime":{
"$type":"atom",
"value":null
},
"summary":{
"$type":"atom",
"$size":41,
"value":{
"id":80189685,
"type":"show",
"isOriginal":true
}
},
"releaseYear":{
"$type":"atom",
"value":2019
},
"availability":{
"$type":"atom",
"$size":84,
"value":{
"isPlayable":true,
"availabilityStartTime":1576828800000,
"availabilityDate":"December 20"
}
},
"maturity":{
"$type":"atom",
"$size":591,
"value":{
"rating":{
"value":"TV-MA",
"maturityDescription":"For Mature Audiences. May not be suitable for ages 17 and under.",
"maturityLevel":110,
"specificRatingReason":"violence, sex, nudity, language, gore, smoking",
"board":"US TV",
"boardId":10,
"reasons":[
{
"id":7415,
"reasonDescription":"violence",
"levelDescription":null
},
{
"id":7417,
"reasonDescription":"sex",
"levelDescription":null
},
{
"id":7421,
"reasonDescription":"nudity",
"levelDescription":null
},
{
"id":7426,
"reasonDescription":"language",
"levelDescription":null
},
{
"id":7429,
"reasonDescription":"gore",
"levelDescription":null
},
{
"id":7430,
"reasonDescription":"smoking",
"levelDescription":null
}
]
}
}
},
"mostWatchedData":{
"$type":"atom",
"value":null
},
"seasonCount":{
"$type":"atom",
"value":1
},
"seasonList":{
"0":{
"$type":"ref",
"value":[
"seasons",
"80189598"
]
},
"1":{
"$type":"atom"
},
"2":{
"$type":"atom"
},
"3":{
"$type":"atom"
},
"4":{
"$type":"atom"
},
"5":{
"$type":"atom"
},
"6":{
"$type":"atom"
},
"7":{
"$type":"atom"
},
"8":{
"$type":"atom"
}
},
"episodeCount":{
"$type":"atom",
"value":8
}
}
},
"seasons":{
"80189598":{
"id":{
"$type":"atom"
}
}
}
},
"paths":[
[
"videos",
80189685,
[
"availability",
"episodeCount",
"maturity",
"mostWatchedData",
"releaseYear",
"runtime",
"seasonCount",
"seasons",
"summary",
"title"
]
],
[
"videos",
80189685,
"seasonList",
{
"from":0,
"to":8
},
"id"
]
]
}
Awesome! Though we still need to find information about episodes, so let's use some of the data from the previous response,
["seasons",{season_list}, "episodes", {{"from":0,"to":{total_episodes}}},["title","runtime", "summary", "releaseYear", "availability", "maturity", "mostWatchedData"]]
Pretty simple, right? Same as videos and genres fetching, we can add list of seasons, not just 1! Here's an example response for an episode,
"80244465":{
"title":{
"$type":"atom",
"value":"Betrayer Moon"
},
"runtime":{
"$type":"atom",
"value":4022
},
"summary":{
"$type":"atom",
"$size":89,
"value":{
"idx":3,
"id":80244465,
"type":"episode",
"isOriginal":true,
"episode":3,
"season":1,
"isPlayable":true
}
},
"releaseYear":{
"$type":"atom",
"value":2019
},
"availability":{
"$type":"atom",
"$size":84,
"value":{
"isPlayable":true,
"availabilityStartTime":1576828800000,
"availabilityDate":"December 20"
}
},
"maturity":{
"$type":"atom",
"$size":591,
"value":{
"rating":{
"value":"TV-MA",
"maturityDescription":"For Mature Audiences. May not be suitable for ages 17 and under.",
"maturityLevel":110,
"specificRatingReason":"violence, sex, nudity, language, gore, smoking",
"board":"US TV",
"boardId":10,
"reasons":[
{
"id":7415,
"reasonDescription":"violence",
"levelDescription":null
},
{
"id":7417,
"reasonDescription":"sex",
"levelDescription":null
},
{
"id":7421,
"reasonDescription":"nudity",
"levelDescription":null
},
{
"id":7426,
"reasonDescription":"language",
"levelDescription":null
},
{
"id":7429,
"reasonDescription":"gore",
"levelDescription":null
},
{
"id":7430,
"reasonDescription":"smoking",
"levelDescription":null
}
]
}
}
},
"mostWatchedData":{
"$type":"atom",
"value":null
}
}
Pretty cool, huh?
Coding it
I'm assuming your familiar with virtual environments and all, so I'm not going to explain that. Let's install requests,
(venv) $ pip install requests
Then, let's create config.py, where we'll copy our headers and urls. Next we need to somehow construct these 'paths' aka the POST body. Let's create a file path.py and write this class,
class Path(object):
def __init__ (self, name):
self.name = name
def __str__ (self):
return self.name
def __repr__ (self):
return "'" + self.name + "'"
Why do we need this? Well, if we want to build the path, we need to make a dictionary, and we need multiple paths, as we know, dictionaries can't have duplicate keys. This class allows us to create multiple keys, because we're going to pass an object, a string: 'path', which makes the keys 'different'. Let's create our main.py or whatever you want to call it. We need to import our Path class and our config, so let's add an empty __init__.py in our directory, For the sake of simplicity, I'm going to define one function only and put everything there. Also, I would recommend using proxies.
from .path import Path
from .config import url, PROXIES, headers
import requests
videos_id_list = []
# Note: We don't actually have to use the Path class here, since we have only one key-value pair.
payload = {
Path('path') : f'["genres", {list(range(1, 1000))}, {{"from":0, "to":300}}, "videos"]'
}
try:
response = requests.post(url, proxies=PROXIES, headers=headers, data=payload)
for obj in response.json().get('jsonGraph').get('videos'):
# NOTE: This most likely won't work, because `obj` is still json we need to parse.
videos_id_list.append(obj)
except Exception:
# Do something
pass
videos_payload = {
Path('path'): f"["videos",{videos_id_list},["title", "runtime", "summary", "seasons", "releaseYear", "availability", "maturity", "mostWatchedData", "seasonCount", "episodeCount"]]",
Path('path'): f"["videos", {videos_id_list}, "seasonList",{{"from":0,"to":8}},"id"]",
}
# After we get the video IDs we'll send
You can see the idea, I leave the rest to you.
Additional attributes we can get
- availabilityEndDateNear
- bookmarkPosition
- boxArts
- cast
- copyright
- creditsOffset
- delivery
- evidence
- hasSensitiveMetadata
- synopsis
- isNSRE
- tallBoxarts
- writers
The End
I think Netflix has very a interesting API, it was fun working on this! If anyone has any questions feel free to drop a comment below.





Top comments (0)