
This year I started working in a startup that focuses on various solutions for law firms. During the development of one of those solutions, I stumbled on a problem where I had to rank words for a specific legal document, considering the relevance of each word when compared against all of the others in a set of documents. How did I manage to solve this?
With a little thing called tf-idf! You might have guessed it from the title, but let me tell you that this is a powerful ranking statistic that is widely used by many big corps. Even Google used to use it a lot until some new fancy things came to be, such as BERT.
 Eric Wallace@eric_wallace_
Eric Wallace@eric_wallace_ The state of NLP in 2019.
The state of NLP in 2019.
I’m talking with an amazing undergrad who has already published multiple papers on BERT-type things.
We are discussing deep into a new idea on pretraining.
Me: What would TFIDF do here, as a simple place to start?
Him: ....
Me: ....
Him: What’s TFIDF?05:10 AM - 19 Dec 2019
236
1358
Before you continue reading, let me give you a heads up that everything I show here is available in this Colab notebook so you can easily try things out in an easy way.
Without further ado, let's jump on what's tf-idf.
It stands for term frequency - inverse document frequency, and it can be seen as a function that ranks words based on their importance across documents, weighted down by the amount of times they appear, following the idea that if a word is way too common, it shouldn't be that important.
Mathematically, it is the equivalent of calculating the term frequency (TF) multiplied by the inverse document frequency (IDF). So, given a term t and a document d. For our TF we'd have:
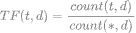
Where count(t,d) is the amount of times t appears inside of d, and count(*,d) is the total number of terms inside of d, meaning that, if a word appears a lot in our documents, that means that it's probably somewhat relevant.
But, what about words that are common but don't bring any value for us? That's where IDF comes in, it's a way to weight down such common words by comparing its appearance among all of our documents. So, if a word appears way too much across many documents, it probably means that it isn't that relevant and it's just a common word. Here's what it looks like in maths language:

Where D is the total number of documents, and amount(t,D) is the number of documents containing t.
The loge is due to the fact that the IDF would explode for the cases where we have too many documents.
Finally, we have:

Here we'll learn how to implement and make proper use of it, and for that I chose to go with BBC's raw dataset of news. We could go with the preprocessed one, but in real life we hardly ever get handed something already tidied up, so let's roll up our sleeves and get to work!
First of all, download the actual dataset from here and extract it somewhere, and import all of the libraries that we'll need to get things going on.
from nltk.stem import SnowballStemmer
from nltk.stem import WordNetLemmatizer
from collections import Counter
import pandas as pd
import numpy as np
import nltk
import re
import os
nltk.download('wordnet')
If you've never heard about nltk (Natural Language Toolkit), it's a nice library that gives us tons of stuff to work with texts and will make our life easier. In that last line, it downloads a lexical database for the English language, which we'll be using a lot since our news are actually in English. Also, do you see that SnowballStemmer and WordNetLemmatizer over there? We'll talk about those later on. For now, we'll begin by reading all of the data into our program
documents = []
for root, dirs, files in os.walk("."):
for name in files:
if name.endswith((".txt")):
filepath = root + os.sep + name
with open(filepath, 'r', encoding='latin-1') as file:
data = file.read().replace('\n', ' ').split()
documents.append(data)
Now it's time to preprocess our data. We'll first remove all characters with a length of 1, since those don't bring any useful information to us.
documents = [[word for word in sublist if (len(word)>1)]
for sublist in documents]
We're also gonna make all words lowercase, since a computer thinks that "Word" is not the same as "word", due to the value of an uppercase letter being different from a lowercase one.
documents = [[word.lower() for word in sublist]
for sublist in documents]
Remove all of the meaningless symbols
symbols = "!\"#$%&()*+-./:;<=>?@[\]^_`{|}~\'"
for i in symbols:
documents = [[''.join([char for char in word if char != i])
for word in sublist]
for sublist in documents]
Now let's make use of nltk in order to detect our stopwords, words that won't have any relevance for our needs, such as is, you, when, and then remove those.
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words("english")
documents = [[word for word in sublist if word not in stopwords]
for sublist in documents]
Remember those nlkt.stem libraries we imported earlier? Those are responsible for the stemming and lemmatization of our dataset. But what are those things?
Simply put, stemming is the process of simply "cutting" a word from any sufix or prefix to get its radical (e.g., studying would become study, while studies would become studi). On the other hand, lemmatization is a process a bit more complicated, where we would go through some morphological analysis in order to get back our "root" word(e.g., better would become good).
You can read more about it here.
Let's go with lemmatization and then stemming because it's fancier, but ideally you should experiment with each one separately and then together to see which strategy would be the best fit for your data while considering the time it takes to run. From personal experience, usually stemming alone is enough for most cases.
lemmatizer = WordNetLemmatizer()
documents = [[lemmatizer.lemmatize(word) for word in sublist]
for sublist in documents]
stemmer = SnowballStemmer('english')
documents = [[stemmer.stem(word) for word in sublist]
for sublist in documents]
Let's recap what we've done so far:
- Removing characters with length equal to 1
- Making everything lowercase
- Removing symbols
- Removing stopwords
- Lemmatizing then stemming every word in our corpus.
Wew! That's a lot of preprocessing. So, everything looks ready to go, let's finally get into processing our data! We'll start off by simply getting the document frequency for each word in each document
dfs = {}
for i in range(len(documents)):
for word in documents[i]:
try:
dfs[word].add(i)
except:
dfs[word] = {i}
One nice thing to note is that the length of dfs is actually the total amout of unique words we have.
len(dfs)
Now, dfs actually has a list of each document that contains a specific word, but we don't need that. Instead, what we need is simply the number of documents containing the word, so let's fix this up
for i in dfs:
dfs[i] = len(dfs[i])
We can finally make ourselves a dictionary containing the tf-idf score for each word in each document
tf_idf = {}
for i in range(len(documents)):
counter = Counter(documents[i])
for token in np.unique(documents[i]):
tf = counter[token]/len(documents[i])
df = dfs[token]
idf = np.log(len(documents)/(df+1))
tf_idf[i, token] = tf*idf
And convert it into a panda's dataframe to make it easier to toy with it
(pd.DataFrame(list(tf_idf.items()))
.sort_values(by=[1], ascending=False)
.head(5))
Here you can already see the words with the highest tf-idf score, and which document they belong to. Let's try to make it a little nicer to see this data through a word cloud
from wordcloud import WordCloud
import matplotlib.pyplot as plt
word_cloud_dict = {}
for key, val in tf_idf.items():
if key[1] not in word_cloud_dict or val > word_cloud_dict[key[1]]:
word_cloud_dict[key[1]] = val
wordcloud = WordCloud().generate_from_frequencies(word_cloud_dict)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Which should give us something like that:

We can also create a word cloud for some specific document
word_cloud_dict = {(key[1] if key[0]==1 else "a"):(val) for (key,val) in tf_idf.items()}
wordcloud = WordCloud().generate_from_frequencies(word_cloud_dict)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Now that you understand what's behind tf-idf and know how to implement it, you can safely rely on libraries that have it already implemented optimally, since no one wants to keep reinventing the wheel all the time
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(sublinear_tf=True,
min_df=5, norm='l2',
encoding='latin-1',
ngram_range=(1, 2),
stop_words='english')
features = tfidf.fit_transform(your_data_here).toarray()
Given that example, I believe it'd be nice to know how you could use the data we obtained. For starters, it could be easily used in a SEO of sorts, like many companies (including Google!) used to do. Another nice thing that you could do is to use it in some machine learning models, like Mercado Libre did, since it gives you an easy way to translate words into numbers. The guys at Google also wrote a nice blog post on ML that touches a bit on tf-idf.





Top comments (1)
I think it's worth noting that I managed to do those nice math images after reading this post:
Math API: LaTeX Math as SVG image
Yasuaki Uechi ・ Oct 23 '18 ・ 1 min read