
What is this about?
This post is about building AI agents that can semantically integrate structured and unstructured data for advanced search and analysis. The ability to search and analyze data is becoming increasingly important in today's data-driven world. With the explosion of data sources and the increasing complexity of data formats, it is becoming more and more difficult for humans to manually search and analyze data. AI agents can help to automate this process, allowing organizations to quickly and accurately extract insights from their data and web. As a demonstration, an agentic application proposed in this post shows capabilities of leveraging a set of tools and techniques to search and analyze structured and unstructured data. The code for this application is available on GitHub.
What is the problem?
The problem is that organizations are struggling to search and analyze structured and unstructured data together. Traditional methods of searching and analyzing data, such as keyword-based search engines and manual data processing tools, are no longer sufficient to handle the dynamic user requests as well as volume and complexity of data that organizations are dealing with. These methods are time-consuming, require a lot of engineering manpower, and the results are not always accurate, relevant, and up-to-date due to the insufficient understanding of the user's query or request, context and meaning of the data.
For example, as an analyst in a healthcare organization, you may need to search and analyze patient records, medical reports, and research papers to identify patterns, trends, and insights that can help improve patient care. However, the data is stored in different formats, such as databases, spreadsheets, text documents, images, and videos, making it difficult to search and analyze the data effectively. Some organizations may put a lot of engineering effort to convert unstructured data into structured or key-word indexing data, but this is time-consuming and very costly. However, even with structured or key-word indexing data, the traditional methods of searching and analyzing data are not sufficient to handle the dynamic user requests. For instance, when you are trying to query a database to find the average age of patients with a specific medical condition, you may need to write complex SQL queries and join multiple tables, which can be time-consuming and error-prone, even if you are technically capable of doing so. And the results? They may still not be accurate and relevant, and even misleading due to the insufficient understanding of your request and background context (e.g., orgnaizational background or business scope).
Why is this important?
Combining structured and unstructured data in the way of semantic integration allows organizations to extract insights quickly and accurately, leading to better decision-making and actionable insights.
For example, as a healthcare analyst, you need to identify patterns and trends to improve patient care. By submitting your plain-language query, the system can automatically understand it semantically, retrieve and integrate relevenat data from various sources like patient records and medical reports, analyze the data, and present the results in an easy-to-understand format. This helps you make better decisions and draft reports with actionable insights for patient care improvement quickly.
With this type of system, organizations can improve their search and analysis capabilities, enhance decision-making, increase productivity, drive innovation, improve customer experience, and gain a competitive advantage. The key of this type of system is how it can accurately understand the user's requests or queries, related context, and then retrieve the relevant data from structured and unstructured data sources, analyze the data, and present the results in a meaningful way.
What is the semantic integration of structured and unstructured data?
The semantically integration of structured and unstructured data is the process of combining structured data, such as databases and spreadsheets, with unstructured data, such as text documents, images, web pages, and videos, into a unified, meaningful structure by understanding and preserving the user requests or queries, context, meaning, and relationships of the data. Semantic integration focuses on the meaning and context of data rather than just its structure. This includes linking related entities, resolving conflicts in data interpretations, and ensuring interoperability between systems and data. For example, for a healthcare organization, semantic integration could involve combining structured patient records with unstructured medical reports (e.g., PDF files) to provide a comprehensive view of a patient's health history.
The processing key components of semantic integration include:
User Query Understanding: Understanding the user's query and intent is the first step in semantic integration. This involves analyzing the user's query to determine the context, meaning, and relationships of the data.
Data Retrieval and Integration: Retrieving and integrating data from a variety of sources, including interal document stores, relational databases, and crawled web pages, is the next step in semantic integration. This involves combining data from different sources into a unified, meaningful structure.
Data Analysis and presentation: Analyzing, interpreting, and presenting the integrated data is the final step in semantic integration. This involves extracting insights from the data, such as summaries, classifications, and predictions.
Accordingly, the technical key components of semantic integration include:
User Interactive Agent: The user interactive agent is responsible for understanding the user's query and intent. This involves analyzing the user's query to determine the context, meaning, and which tools or function callings it could leverage.
Structured Data Retrieval Agent: The structured data retrieval agent is responsible for retrieving and integrating structured data from a variety of sources, such as databases and spreadsheets. This involves combining data from different sources into a unified, meaningful structure.
Unstructured Data Retrieval Agent: The unstructured data retrieval agent is responsible for retrieving and integrating unstructured data from a variety of sources, such as text documents, images, and videos. This usually leverages RAG (Retrieve, Analyze, Generate) approach and Retrival-Augmented Generation (RAG) technology.
Web Search Agent: The web search agent is responsible for crawling and indexing web pages to retrieve and integrate data from the Internet. This involves searching for relevant data on the web and extracting insights from the data.
The following diagram illustrates the technical key components of semantic integration of structured and unstructured data:
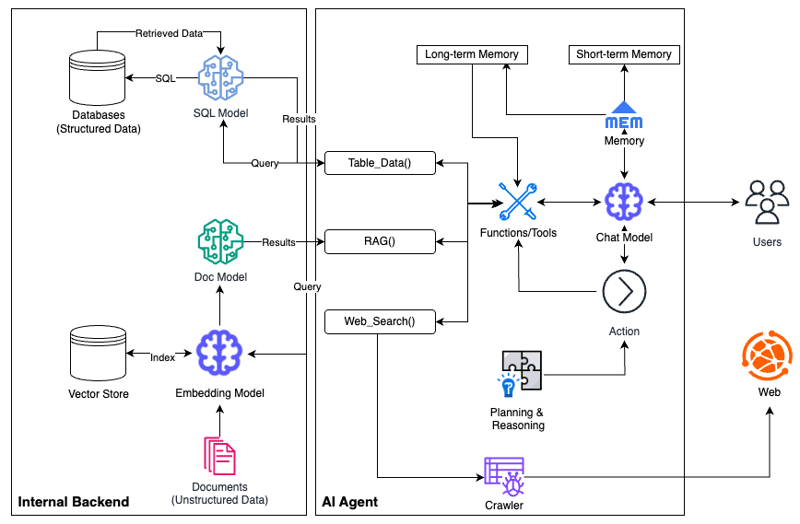
What are the other benefits?
Beside the benefits mentioned above, the semantic integration of structured and unstructured data provides a number of other benefits, including:
Flexibility: Organizations can easily adapt to changing data sources, formats, and user requests. The system can also be easily extended to support new features and capabilities as well as integrated with other systems and tools.
Efficiency: Organizations can process large amounts of data quickly and accurately because the system can automatically understand the user's requests, context, and meaning of the data and then use the appropriate tools and techniques to search and analyze the data based on the user's requests. The data volume and complexity are small and no longer a barrier to search and analyze data.
Relevancy: Organizations can extract relevant and valuable insights from their data. The system can automatically understand the user's requests, context, and meaning of the data, and then retrieve and integrate the relevant data from structured and unstructured data sources, analyze the data, and present the results in a meaningful way.
Real-time insights: Organizations can easily extract real-time insights from their data and Internet or web, allowing them to quickly respond to changing market conditions and user requests, and further improve their decision-making and customer experience.
How can it be implemented?
In this post, we will use OpenAI Agent SDK and other techniques to build an AI Agent application that can semantically integrate structured and unstructured data for advanced search and analysis. The application is built on top of the Python programming language and uses a number of popular libraries, including PandasAI, OpenAI, etc. The code for this application is available on GitHub.
Why use OpenAI Agent SDK?
OpenAI has introduced new tools, including Agent SDK, to help developers and enterprises build, deploy, and scale AI agents. The Agents SDK is an open-source framework that simplifies the orchestration of single-agent and multi-agent workflows. It includes features like intelligent handoffs, configurable guardrails for safety, and observability tools for tracking performance. It supports built-in web search, file search, and computer use, making it easier to build agents that perform various tasks autonomously. These tools address challenges in building production-ready AI agents, such as complex orchestration and extensive prompt iteration. By replacing manual prompt engineering and custom scripting with advanced tools, OpenAI makes agent development faster and more practical. These innovations empower businesses to automate complex workflows without extensive technical expertise, transforming operations across various industries.
What is the approach for unstructured data
One of the key techniques used in the application is the RAG approach, which stands for Retrival-Augmented Generation (RAG). The RAG approach is a three-step process that allows agents to quickly and accurately extract insights from unstructured data. In the Retrieve step, the agent retrieves relevant data from a variety of sources, including text documents, images, and videos based on the user's request. In the Analyze step, the agent analyzes the retrieved data using a variety of techniques, including natural language processing, computer vision, and machine learning. In the Generate step, the agent generates insights from the analyzed data, such as summaries, classifications, and predictions. The RAG technology is a powerful tool for searching and analyzing unstructured data, allowing agents to quickly extract valuable insights from their data.
What is the approach for structured data
The application also uses a number of techniques to search and analyze structured data. One of the key techniques used in the application is PandasAI, which is a powerful library for data manipulation and analysis. PandasAI provides a number of tools for working with structured data, including data structures, data manipulation functions, and data analysis functions. By using PandasAI, agents can quickly and easily process structured data, allowing them to extract valuable insights from their data.
Notice: we don't use the RAG approach here since structured data is already organized in a way that makes it easy to search and analyze. Structured data is typically stored in databases or spreadsheets, which provide a consistent format for storing and retrieving data. Because structured data is already organized, agents can quickly and easily extract insights from structured data without the need for the RAG approach. Instead, agents can use tools like PandasAI to quickly process structured data and extract valuable insights.
Which agentic pattern does it use?
In this agentic application, we use the "agent orchestration" pattern. This pattern is used to build agents that can perform complex tasks by breaking them down into smaller, more manageable sub-tasks. Each sub-task is handled by a separate agent, which is responsible for retrieving and processing the data. The agents work together to complete the task, passing data back and forth as needed. For example, you might have a frontline agent that receives a user's request, and then hands off to a specialized agent based on the language of the request. The specialized agent then retrieves and processes the data, and hands off the results back to the frontline agent, which presents the results to the user. This pattern is ideal for building agents that need to perform multiple tasks in parallel or in sequence, such as searching and analyzing structured and unstructured data.
Conclusion
The agentic application proposed in this post provides a set of tools and techniques that can be used to build intelligent agents that can search and analyze structured and unstructured data. It is capable of processing large amounts of data quickly and accurately, allowing organizations to extract valuable insights from their data. The application is designed to be flexible and extensible, allowing developers to easily add new features and capabilities to their agents. The application is built on top of the Python programming language and uses a number of popular libraries, including PandasAI, OpenAI, etc. The application is designed to be easy to use and understand, making it ideal for both beginners and experienced developers.



Top comments (0)