Overview of Amazon Web Services
The Overview of AWS pdf is nothing but a literal overview of the benefits of the Amazon Web Services Cloud . Since I like to be thorough about covering a topic, I’m going to give it a good read. My mind kept telling me, “skip that sh$%”, but I’d like to take a careful look at the first few resources provided by AWS to see if I’m going to end up buying additional resources, which I really don’t want to, but we will see.
AWS Cloud Computing
AWS started offering its services back in 2006. Ever since then, it’s been growing exponentially, not only in loyal customers, but in services they offer. The main reason why AWS took off was because it lowered the barriers to entry into application development for start-ups, it lowered expenses of on-prem infrastructure (server setup & mgmt), and it allows businesses to scale rapidly, this was key for both, new and existing businesses.
Cloud Computing Models
-- Infrastructure as a Service (IaaS)
Building blocks of networking and cloud IT, IaaS gives you the flexibility and control over your IT resources.
-- Platform as a Service (PaaS)
Underlying infrastructure that typically include hardware and O.S., PaaS helps by taking the stress and worry about resource mgmt, capacity planning, software maintenance, patching, or any other tedious and complex task for your hardware to run the O.S. that hosts your application.
-- Software as a Service (SaaS)
SaaS provides you with a completed product or feature for your application that is run and managed by the SP (Service Provider). The benefit is that you don’t have to think about how to configure your software, just how to use it in your application, whether it be a web-based email or AWS Cognito.
Cloud Computing Deployment Models
-- Cloud
A cloud-based app is fully deployed in the cloud and all parts of the app run in the cloud.
-- Hybrid
A hybrid deployment is a way to connect on-prem infrastructure with cloud-based resources.
-- On-premises
On-prem infrastructure with some app mgmt and virtualization on the cloud is often referred to as “private cloud”.
Global Infrastructure
The AWS Cloud infrastructure is built around Regions and Availability Zones (AZ).
A Region is a physical location in the world where we have multiple AZs.
An Availability Zone consist of one or more discrete data centers, each with redundant power, networking, and connectivity, house in separate facilities.
The AWS Cloud operates in over 60 AZs within 20 Regions around the world, with more coming soon. Each Region is designed to be completed isolated from the other Regions. Each AZ is isolated, but the AZs in a Region are connected through low-latency links.
These AZs give you the ability to operate apps and DBs that are highly available, fault tolerant, and scalable as fast as a few clicks.
Security and Compliance
-- Security
Cloud security at AWS is the highest priority. As an AWS customer, we inherit all the best practices of AWS policies, architecture, and operational processes built to satisfy the most security-sensitive customers.
While AWS manages the security of the cloud, we are responsible for security in the cloud.
-- Compliance
The IT infrastructure in AWS provides best security practices and a variety of IT security standards, following a partial of assurance programs:
- SOC 1/ISAE 3402, SOC 2, SOC 3
- FISMA, DIACAP, and FedRAMP
- PCI DSS Level 1
- ISO 9001, ISO 27001, ISO 27017, ISO 27018
AWS Cloud Platform
This section introduces the major AWServices by category.
To access AWS services, you can use:
- AWS Mgmt Console
- Command Line Interface (CLI using AWS CLI)
- Software Development Kits (SDKs)
Analytics
-- Amazon Athena
Athena is an interactive query service used to analyze data in Amazon S3. This SaaS has no infrastructure to manage, and you pay only for queries ran.
To use it, simply point your data in Amazon S3, define the schema, and start querying using SQL. Data is returned within seconds, and there is no need for extract, transform and load (ETL) jobs to massage your data for analysis, Athena does it for you.
Benefits include, but not limited to:
- Athena uses Presto with ANSI SQL support and works with a variety of data formats, including CSV, JSON, ORC, Avro, and Parquet.
- Athena uses Amazon S3 as its data store, so it is highly available and durable, as well as cheap
- Pay per queries ran. You are charged $5 per TeraByte scanned by queries. To save on queries, use compression, portioning, and converting data into columnar formats
- Athena is fast, as it executes queries in parallel, so you’ll get data back within seconds
- Run federated queries against relational DBs, data warehouses, object stores, and non-relational data stores
- Create your own user-defined functions (UDF), and invoke one or multiple UDFs from your SELECT and FILTER clauses
- Some custom functions include compressing and decompressing data, redacting sensitive data, or applying customized decryption
- Invoke Machine Learning models for inference directly from SQL queries using Athena, and integrate with Amazon SageMaker’s learning algos
- The ability to use Machine Learning models in SQL makes complex tasks such as anomaly detection, customer cohort analysis and sales predictions as simple as invoking a function in a SQL query
- Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repo across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions to maintain schema versioning
-- Amazon EMR
Amazon Elastic MapReduce (EMR) is a tool for big data processing and analysis. Using open source tools, coupled with the scalability of AWS EC2 and storage of Amazon S3, EMR can run PetaBytes scale analysis for a fraction of the cost of traditional on-prem clusters.
Some of the benefits to use EMR are:
- Easy to use — EMR is easy to use because you don’t worry about infrastructure setup, node provisioning, Hadoop configuration, or cluster tuning. Data lovers can launch a server less Jupyter notebook in seconds using EMR Notebooks
- Elastic and Flexible — Unlike the rigid infrastructure of on-prem clusters, EMR decouples compute and persistent storage, to scale each independently, rather than having to buy hardware for storage running out when there is no need for additional compute power. You also have full control and root access to every instance, so additional apps can be installed to customize every cluster. There’s also an option to launch EMR clusters with custom Amazon Linux AMIs, and reconfigure already running clusters on the fly, without having to re-launch existing, running clusters
- Reliable — EMR is tuned for the cloud, and constantly monitors your cluster — retrying failed tasks and automatically replacing poorly performing instances to fix compute performance issues.
- Secure — EMR automatically configures EC2 firewall settings controlling network access to instances, and launches clusters in an Amazon Virtual Private Cloud (VPC), a logically isolated network you define.
- Low cost - big data workloads for less saving up to 90% using EC2 Spot Instances, using S3 for data lakes for free using EMR services
Some of the use cases for EMR are:
- Machine learning — easily add your preferred libraries and tools to create your own predictive analytics toolset
- Extract, Transform and Load (ETL) — quickly perform data transformation workloads (ETL) such as - sort, aggregate, and join - on large datasets
- Clickstream analysis — using Apache Spark and Apache Hive to segment users, understand user preferences, and deliver more effective ads
- Real-time streaming — create long-running, highly available, and fault-tolerant streaming data pipelines by analyzing events from Apache Kafka, Kinesis or any real-time streaming data source with Apache Spark Streaming and EMR
- Interactive analytics — EMR Notebooks provide a managed analytic environment based on open source Jupyter to prepare and visualize data, collaborate with peers, build apps, and perform interactive analysis
- Genomics — process vast amounts of genomic data and other large scientific data sets quickly and efficiently
-- Amazon CloudSearch
CloudSearch is a SaaS that makes it simple and cost-effective to setup, manage and scale a search solution for your app. CloudSearch supports 34 languages and popular search features such as:
- Highlighting
- Autocomplete
- Geospatial search
- Custom relevance ranking and query-time rank expressions
- Field weighting
Cost is based on usage, but the good thing is that it uses S3 as data storage and recovery, and customers get this for free, which is a significant cost saving over self-managed search infrastructure. Customers are billed based on usage across the following dimensions:
- Search instances
- Document batch uploads
- IndexDocuments requests
- Data transfer
-- Amazon Elasticsearch Service
Elasticsearch is a fully managed service that makes it easy to build, deploy, secure, monitor and troubleshoot applications.
Some of the benefits are:
- Easy to deploy and manage — service simplifies mgmt tasks such as hardware provisioning, software installation and patching, failure recovery, backups, and monitoring
- Highly scalable and available — lets you store up to 3 PB of data in a single cluster, enabling you to run large log analytics via a single Kibana interface
- Kibana — With Elasticsearch service, Kibana is deployed automatically with your domain as a fully managed service, automatically taking care of all the heavy-lifting to manage the cluster
- Highly secure - achieve network isolation using VPC, encrypt data at-rest and in-transit using keys managed through AWS KMS, and manage authentication and access control with Cognito and IAM policies
- HIPAA eligible, and compliant with PCI, DSS, SOC, ISO, and FedRamp standards
- Low cost — pay only for the resources you consume by selecting on-demand pricing with no upfront costs or long-term commitments, OR get significant savings by getting a Reserved Instance pricing
Some use cases are:
- Application monitoring — log data to find and fix issues faster and improve app performance by receiving automated alerts if app is underperforming
- Security Info and Event Management (SIEM) — centralize and analyze logs from disparate applications and systems across your network for real-time threat detection and incident management
- Search — same features as CloudSearch
- Infrastructure monitoring — collect logs from servers, routers, switches, virtualized machines to get a view detailed view into your infrastructure, reducing Mean Time To Detect (MMTD) and Resolve (MMTR) issues and lowering system downtime
-- Amazon Kinesis
Kinesis makes it easy to collect, process and analyze video and data streams in real-time. Kinesis enables you to process and analyze data as it arrives, instead of having to wait for it to begin processing.
Amazon Kinesis capabilities include:
-
Kinesis Video Streams
- Ingests and stores video streams to use in custom apps for analytics, ML, playback...
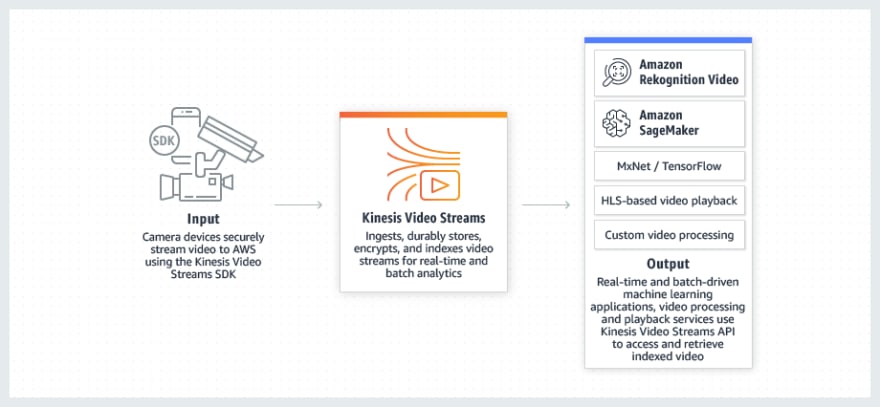
- Ingests and stores video streams to use in custom apps for analytics, ML, playback...
-
Kinesis Data Streams (KDS)
- Takes care of getting the data streamed to storage, streams such as: DB event streams, website clickstreams, social media feeds, IT logs, location-tracking events
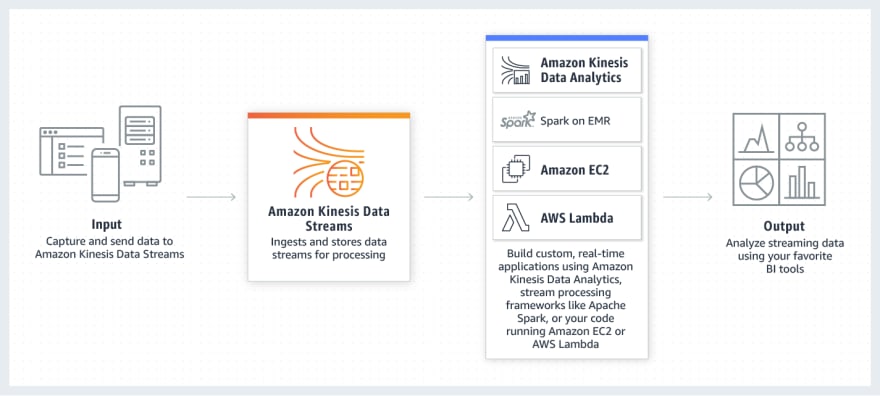
- Takes care of getting the data streamed to storage, streams such as: DB event streams, website clickstreams, social media feeds, IT logs, location-tracking events
-
Kinesis Data Firehose
- Think of the name firehose and the shape of it, now think of data flowing through that actual hose, that is the data streaming into data stores and analytic tools

- Think of the name firehose and the shape of it, now think of data flowing through that actual hose, that is the data streaming into data stores and analytic tools
-
Kinesis Data Analytics
- Analytics happen at the end of the data stream to generate the output
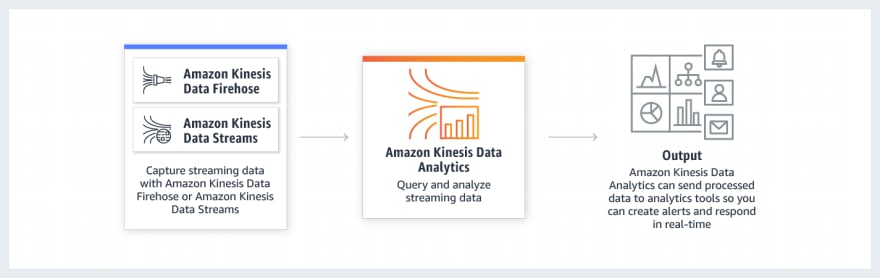
- Analytics happen at the end of the data stream to generate the output
Major benefits from Amazon Kinesis:
- Real-time data metrics ingestion, buffering and processing
- Fully managed infrastructure
- Scalable to stream and process data from a variety of sources
Some use cases:
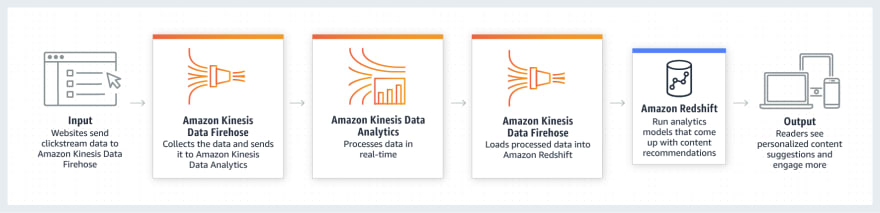

-- Amazon Redshift
Redshit is cloud data lakes and/or warehouse services. Redshift has been improved by using ML, massively parallel query execution, and columnar storage on high-performance disk. Redshift allows you to query petabytes of data (structured or unstructured) out of your data lakes using standard SQL.
Redshift AQUA (Advanced Query Accelerator) is a new distributed and hardware accelerated cache that allows Redshift to run 10x faster than any other data lake or warehouse.
Some use cases for Redshift:
- Business Intelligence (BI) reports built by analyzing all of your data, data lake, or data warehouse.
- Use mixed structured data from a data lake and semi-structured data such as app logs to get operational insights on your apps and systems
-- Amazon QuickSight
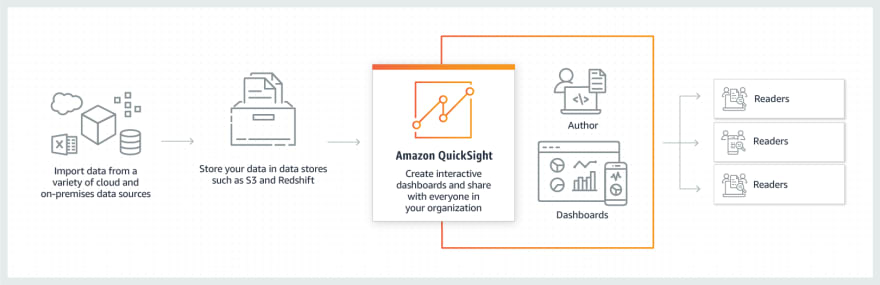
QuickSight is a BI service used to efficiently deliver insights to everyone in an org. You can build interactive dashboards that can be accessed from mobile or web that provide powerful self-service analytics. QuickSight scales to thousands of users without any software, servers, or infrastructure to deal with and buy. It is a pay-as-you-go service with no upfront costs or annual commitments.
Benefits:
- Pay only for what you use
- Scale to all your users
- Embed analytics in apps
- Built end-to end BI reports
How it works...
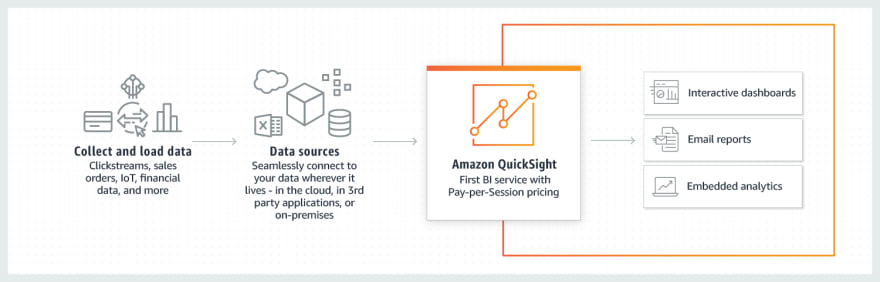
Some use cases include:
Using QuickSight in interactive dashboards for BI
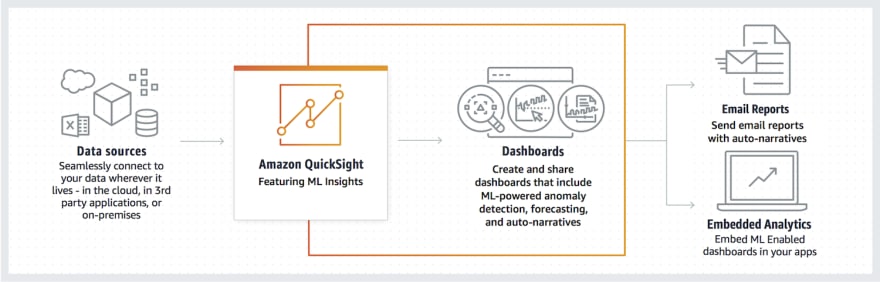
Create dashboards for ML anomaly detection, pattern seeker, forecasting, and data auto-narratives
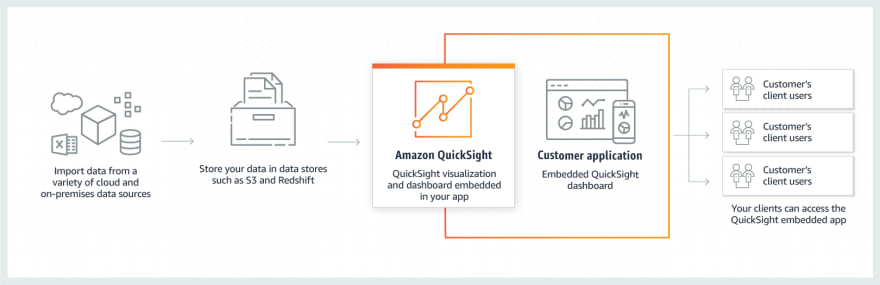
Enhance custom apps by embedding QuickSight dashboards
BI sent via email
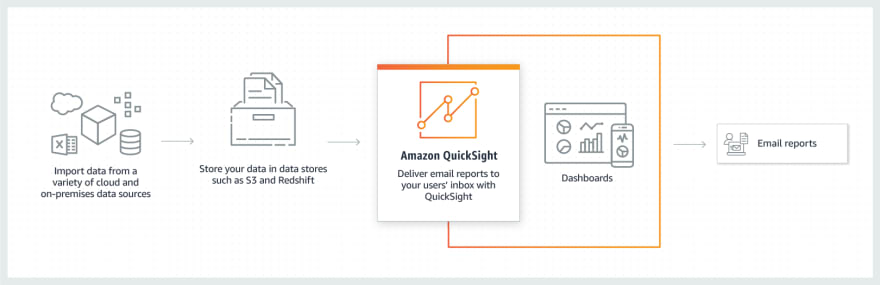
-- AWS Data Pipeline
Data Pipeline allows you to process and move data from different AWS resources such as compute and storage services, as well as on-prem storage. The results can be stored in S3, RDS, DynamoDB or EMR. As with most AWS services, you don’t have to worry about creating complex data processing workloads that are fault tolerant, highly available, and repeatable, or worry about resource availability or inter-task dependencies. Even if something fails after retries, AWS Data Pipeline will send you notifications via AWS Simple Notification Service (SNS).
Data Pipeline makes it so easy to use that their drag-and-drop console allows you to create a file search function in S3 within a few clicks. There are a number of Data Pipeline templates to create pipelines for complex use cases.
-- AWS Glue
Glue is a fully managed ETL SaaS that makes it easy to prepare and load data for analytics. Simply point AWS Glue to the data storage on AWS, and Glue will crawl your data, suggest schemas and transformations, and store associated metadata in the AWS Glue Data Catalog.
Once cataloged, data is immediately searchable, queryable and available for extract, transform and load (ETL).
Some use cases are:
Queries against an S3 Data Lake
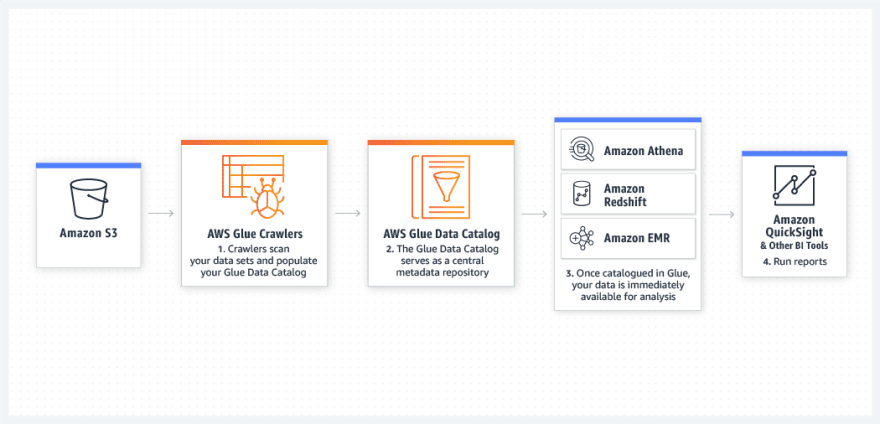
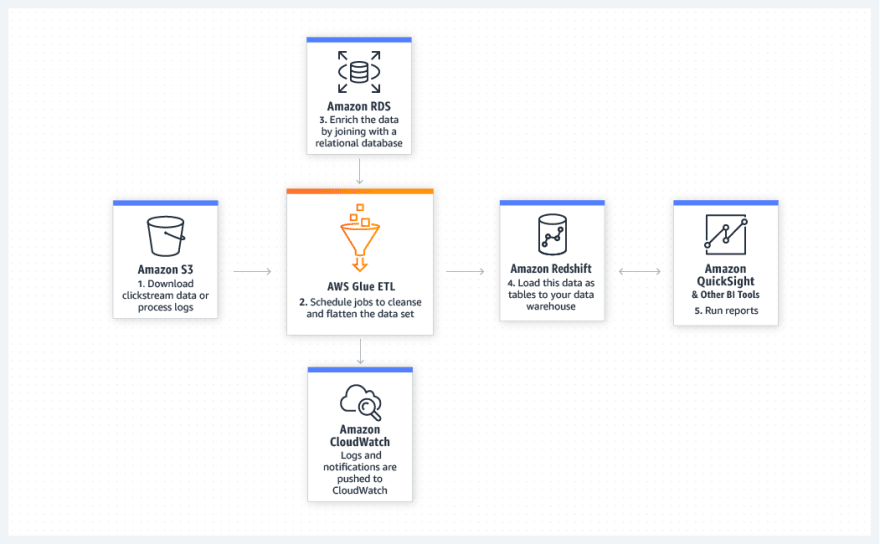
Analyze log data in S3 to enrich data set and generate BI reports
One-stop-shop for multiple data stores
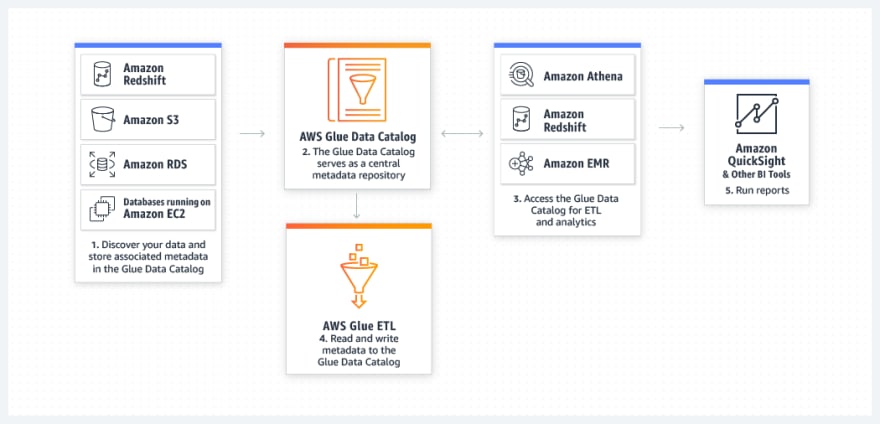
Event-driven ETL data pipelines
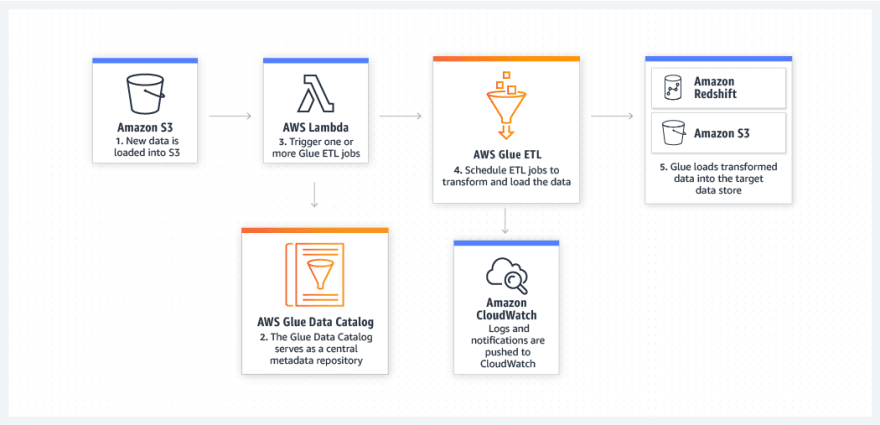
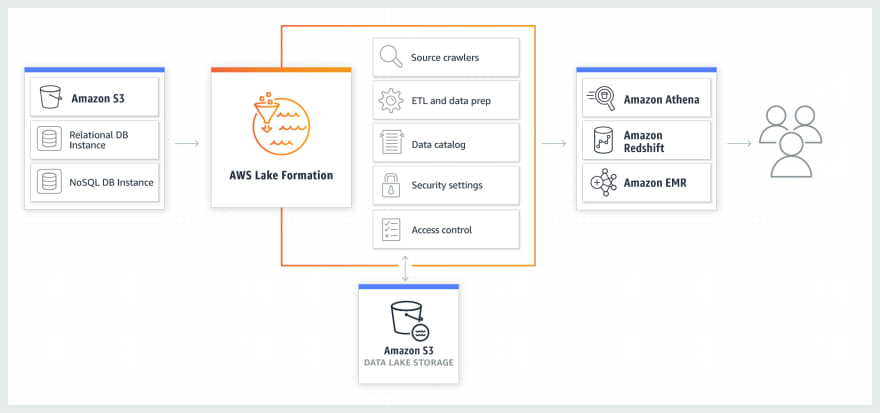
-- AWS Lake Formation
Lake Formation makes it easy to setup a secure data lake in days. A data lake is a centralized, curated and secured repo that stores all your data, in original form and prepared for analysis.
Point Lake Formation at the data sources that you want to move into Lake Formation, and it moves it cleanly taking care of the right schema and metadata, along with choosing security policies and encryption for your data to be used in analytic services.
How it works:
- Everything that the orange box touches is Lake Formation’s kingdom
-- Amazon Managed Streaming for Kafka (MSK)
MSK is a fully managed service that helps you build and run apps that use Apache Kafka to process streaming data. With MSK, you can use Kafka API to populate data lakes, stream changes to and from DBs, and power ML and analytics apps.
Apache Kafka is a streaming data store that decouples apps producing streaming data (producers) into its data store from apps consuming streaming data (consumers) from its data store. Companies use Kafka as a data source for apps that continuously analyze and react to streaming data.
Once again, AWS makes it easy to manage the MSK infrastructure taking care of most of the heavy lifting. AWS takes care of monitoring Kafka clusters and replaces unhealthy nodes with no downtime to your app.
Benefits:
- Fully compatible
- Easy to migrate and run existing Kafka apps on AWS w/out changes to your app’s source code
- You can continue using custom and community built tools such as MirrorMaker, Apache Flink (streaming), and Prometheus.
- Fully managed by AWS
- MSK manages the provisioning, config and maintenance of Apache Kafka clusters and Apache ZooKeeper nodes
- Elastic stream processing
- Run fully managed Apache Flink apps that elastically scale to process data streams w/in MSK
- Highly available
- Multi-AZ replication within an AWS Region
- Highly secure
- VPC network isolation, AWS IAM for API auth, encryption at rest, TLS encryption in-transit, TLS based certificate auth, and supports Kafka Access Control Lists (ACLs) for data auth.

- VPC network isolation, AWS IAM for API auth, encryption at rest, TLS encryption in-transit, TLS based certificate auth, and supports Kafka Access Control Lists (ACLs) for data auth.
Lesson Learned
After diving into the first set of AWServices, Analytics, I found out I have been using only a fraction of all that AWS has to offer. Knowing all the data analytics and services that makes it easy to create valuable insight for decision makers makes me feel like a data science god. With just a few clicks, you can create a Data Lake that uses ML to generate BI and insightful, patterned information to derive smart decisions to drive businesses forward.
The Ramp-Up guide had the Overview of AWS’s duration as 2 hours, but it took me about 5 hours to get the first set of services done, and I still have 76 pages to go.
Stay tuned for the next set of services.
Peace Out.
irb___





Top comments (0)