
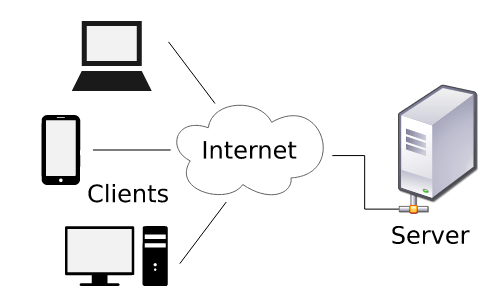
O modelo cliente-servidor (em inglês client-server model), em computação, é uma estrutura/arquitetura de aplicação distribuída que distribui as tarefas e cargas de trabalho entre os fornecedores/provedores de um recurso e/ou serviço, designados como servidores, e os solicitantes/requerentes dos serviços, designados como clientes.
Um servidor é um dispositivo ou computador ou programa dedicado à prestação de serviços para outros programas, chamados de "clientes". Ou seja, um servidor é uma máquina centralizada que oferece serviços a um cliente que é o computador do usuário, assim como o seu. É utilizado pelas pessoas para acessar sites ou sistemas a partir de um endereço no navegador (Google Chrome, Internet Explorer, Safari, Mozilla Firefox e etc).
Depois da etapa de UI/UX Design, vem a etapa de codificação. Na parte de codificação no modelo cliente-servidor, você consegue discernir quem é o requerente e o provedor, o aplicativo mobile do banco de seu celular é o requerente. E a forma como o requerente irá acessar e solicitar as informações dele no sistema, é necessário o provedor. Então, perceba que eles tem funções distintas, assim como também pode haver linguagens de programação distintas ou não.
O modelo cliente-servidor é a arquitetura mais frequentemente citada na literatura de sistemas distribuídos. Historicamente, é a mais importante e continua sendo a mais amplamente utilizada. A figura a seguir ilustra a estrutura simples na qual os processos assumem as funções de clientes ou servidores. Em particular, os processos do cliente interagem com os processos individuais do servidor em computadores host potencialmente separados para acessar os recursos compartilhados que eles gerenciam.
Geralmente os clientes e servidores comunicam através de uma rede de computadores em computadores distintos, mas tanto o cliente quanto o servidor podem residir no mesmo computador.
Um servidor é um host que está executando um ou mais serviços ou programas que compartilham recursos com os clientes. Um cliente não compartilha qualquer de seus recursos, mas solicita um conteúdo ou função do servidor. Os clientes iniciam sessões de comunicação com os servidores que aguardam requisições de entrada.
Frequentemente, clientes e servidores se comunicam em uma rede de computadores em hardware separado, mas tanto o cliente quanto o servidor podem residir no mesmo sistema. Um host de servidor executa um ou mais programas de servidor, que compartilham seus recursos com os clientes.
Um cliente, geralmente, não compartilha nenhum de seus recursos, mas solicita conteúdo ou serviço de um servidor. Os clientes, portanto, iniciam sessões de comunicação com os servidores, que aguardam solicitações de entrada.
O modelo cliente-servidor foi desenvolvido na Xerox PARC durante os anos 70. Este modelo é actualmente o predominante nas redes informáticas. Email, a World Wide Web e redes de impressão são exemplos comuns deste modelo.
A arquitetura cliente-servidor descreve o relacionamento de programas cooperativos em um aplicativo. O componente do servidor fornece uma função ou serviço a um ou mais clientes, que iniciam solicitações para esses serviços. Nesse sentido, os servidores são classificados pelos serviços que fornecem.
Os tipos de servidores dessa arquitetura incluem:
- Servidor de Aplicação (Middleware)
- Servidor DNS
- Servidor Web (Web Server)
- Servidor de Fax
- Servidor de arquivos
- Servidor de email
- Servidor FTP
- Servidor de imagens
A arquitetura de um sistema de software é uma metáfora, análoga à arquitetura de um edifício. Funciona como um blueprint do sistema e do projeto em desenvolvimento, que a gerência do projeto pode utilizar posteriormente para extrapolar as tarefas necessárias a serem executadas pelas equipes e pessoas envolvidas.
A arquitetura de software trata de fazer escolhas estruturais fundamentais que custam caro mudar uma vez implementadas. As opções de arquitetura de software incluem opções estruturais específicas de possibilidades no design do software.
Exemplo: Um servidor web atende páginas web e um servidor de arquivos atende arquivos de computador.
Um recurso compartilhado pode ser qualquer software e componentes eletrônicos do computador servidor, desde programas e dados até processadores e dispositivos de armazenamento. O compartilhamento de recursos de um servidor constitui um serviço.
Se um computador é um cliente, um servidor ou ambos, é determinado pela natureza do aplicativo que requer as funções de serviço.
Exemplo: Um único computador pode executar um servidor web e um software servidor de arquivos ao mesmo tempo para servir dados diferentes a clientes que fazem diferentes tipos de solicitações. O software cliente também pode se comunicar com o software servidor no mesmo computador.
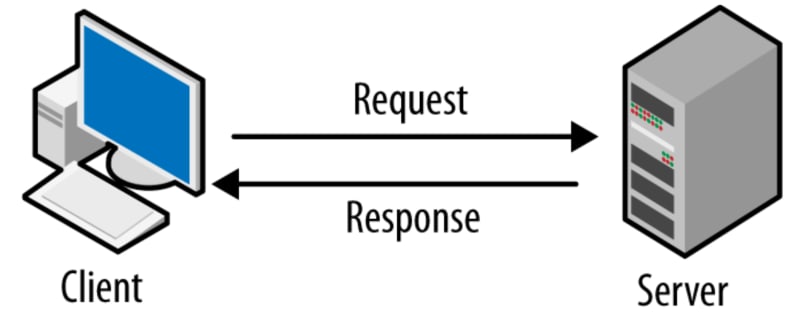
Em geral, um serviço é uma abstração de recursos do computador, e um cliente não precisa se preocupar, em tese, com o desempenho do servidor enquanto atende a solicitação e entrega a resposta. O cliente só precisa entender a resposta com base no protocolo de aplicativo bem conhecido, ou seja, o conteúdo e a formatação dos dados para o serviço solicitado.
Clientes e servidores trocam mensagens em um padrão de mensagem de solicitação-resposta. O cliente envia uma solicitação e o servidor retorna uma resposta. Essa troca de mensagens é um exemplo de comunicação entre processos. Para se comunicar, os computadores devem ter uma linguagem comum e devem seguir regras para que o cliente e o servidor saibam o que esperar.
O idioma e as regras de comunicação são definidos em um protocolo de comunicação, sendo que estes protocolos operam na camada de aplicativo. O protocolo da camada de aplicação define os padrões básicos do diálogo.
Para formalizar ainda mais a troca de dados, o servidor pode implementar uma interface de programação de aplicativos (Application Program Interface – API).
A API é uma camada de abstração para acessar um serviço:
- Ao restringir a comunicação a um formato de conteúdo específico, facilita a análise.
- Ao abstrair o acesso, facilita a troca de dados entre plataformas.
Um servidor pode receber solicitações de muitos clientes distintos em um curto período. Um computador só pode realizar um número limitado de tarefas a qualquer momento e conta com um sistema de agendamento para priorizar as solicitações de entrada dos clientes para acomodá-las.
Para evitar sobrecarga e maximizar a disponibilidade, o software do servidor pode limitar a disponibilidade para os clientes. Aproveitando a eventual possibilidade de sobrecarga, podem ser feitos ataques de negação de serviço que são projetados para explorar a obrigação de um servidor de processar solicitações, sobrecarregando-o com taxas de solicitação excessivas.
Atenção: Caso a segurança seja um fator importante, técnicas de criptografia podem ser aplicadas se as informações confidenciais forem comunicadas entre o cliente e o servidor.
Quando um correntista de banco acessa serviços de banco on-line com um navegador da web (o cliente), este inicia uma solicitação ao servidor de web do banco.
As credenciais de login do correntista podem ser armazenadas em um banco de dados e o servidor da web acessa o servidor de banco de dados como um cliente. Um servidor de aplicativos (Middleware) interpreta os dados retornados aplicando a lógica de negócios do banco e fornece a saída para o servidor da web. Finalmente, o servidor da web retorna o resultado ao navegador da web do correntista para exibição.
Por exemplo, os sistemas que controlavam o veículo de lançamento do ônibus espacial tinham o requisito de serem muito rápidos e muito confiáveis. Portanto, uma linguagem de computação de tempo real (RTC) apropriada precisaria ser escolhida. Além disso, para satisfazer a necessidade de confiabilidade, pode-se optar por ter várias cópias redundantes e produzidas independentemente do programa e executar essas cópias em hardware independente enquanto verifica os resultados.
A documentação da arquitetura de software facilita a comunicação entre as partes interessadas , captura decisões iniciais sobre o design de alto nível e permite a reutilização de componentes de design entre projetos.
A característica do modelo cliente-servidor, descreve a relação de programas numa aplicação. O componente de servidor fornece uma função ou serviço a um ou mais clientes, que iniciam os pedidos de serviço.
Servidor DNS
Quando os usuários digitam nomes de domínio na barra de URL do navegador, os servidores de DNS são responsáveis pela tradução desses nomes de domínio em endereços de IP numéricos, levando-os ao site correto. O Domain Name System (DNS) é a lista telefônica da Internet. Quando os usuários digitam nomes de domínio como 'google.com' ou 'nytimes.com' nos navegadores da web, o DNS é responsável por encontrar o endereço de IP correto para esses sites. Os navegadores então usam esses endereços para se comunicar com os servidores de origem ou com os servidores de borda da CDN para acessar as informações do site. Tudo isso acontece graças aos servidores de DNS: máquinas dedicadas para responder às solicitações ao DNS.
Os clientes DNS, que são integrados à maioria dos sistemas operacionais modernos dos desktops e de dispositivos móveis, permitem que os navegadores web interajam com os servidores de DNS. Para obter mais informações, veja O Modelo Cliente-Servidor.
Web Server (Servidor web)
Um "Servidor web (web server)" pode referir ao hardware ou ao software, ou ambos trabalhando juntos.
As funcionalidades como a troca de e-mail, acesso à internet ou acesso a um banco de dados, são construídos com base no modelo cliente-servidor. Por exemplo, um navegador web é um programa cliente, em execução no computador do usuário, que acede às informações armazenadas num servidor web (Web Server) na internet, onde seu objetivo é ouvir uma porta para responder requisições HTTP. Usuários de serviços bancários, acedendo do seu computador, usam um cliente web para enviar uma solicitação para um servidor web num banco. Esse programa pode, por sua vez, encaminhar o pedido para o seu próprio programa de banco de dados do cliente que envia uma solicitação para um servidor de banco de dados noutro computador do banco para recuperar as informações da conta. O saldo é devolvido ao cliente de banco de dados do banco, que por sua vez, serve de volta ao cliente navegador exibindo os resultados para o usuário.
Mas como o servidor web (Web Server) e o computador sabem o que significa "localhost"? Através do arquivo de hosts. Então, todo sistema operacional possui um arquivo de hosts. No Linux, por padrão fica em
/etc/hosts. No Mac,/private/etc/hosts. Já no Windows,C:\Windows\System32\Drivers\Etc\hosts. Esse arquivo informa ao sistema operacional que quando uma conexão for estabelecida usando algum nome, o IP correspondente deve ser usado. Para o nome localhost, temos o IP da nossa própria máquina (127.0.0.1).
São exemplos de servidores web HTTP, junto com suas características abaixo:
Apache (desenvolvimento/produção): O Servidor HTTP Apache ou Servidor Apache ou HTTP Daemon Apache ou somente Apache, é o servidor web livre criado em 1995 por um grupo de desenvolvedores da NCSA, tendo como base o servidor web NCSA HTTPd criado por Rob McCool. O Apache é um software de servidor da Web de código aberto usado para fornecer páginas da Web aos usuários. É um dos servidores da Web mais populares do mundo e é usado por muitos dos maiores sites. O Apache também é usado como um servidor de aplicativos, permitindo que os desenvolvedores criem e implantem aplicativos na web;
Nginx (desenvolvimento/produção): Nginx é um servidor leve de HTTP, proxy reverso, proxy de e-mail IMAP/POP3, feito por Igor Sysoev em 2005, sob licença BSD-like 2-clause. O Nginx consome menos memória que o Apache, pois lida com requisições Web do tipo “event-based web server”; e o Apache é baseado no “process-based server”, podendo trabalhar juntos;
IIS Express (desenvolvimento): O IIS - Serviços de informação para internet (Internet Information Services) é um servidor web incluso no Visual Studio que permite você aproveitar ao máximo todos os recursos do servidor da Web (SSL, regras de regravação de URL, etc.). O IIS é um servidor web completo – o que significa que você terá uma experiência mais próxima de como funcionará quando implantar o aplicativo em um servidor de produção. O IIS Express é usado apenas para fins de desenvolvimento e teste e não tem suporte para uso em um ambiente de produção como um servidor Web de produção.
Lighttpd (desenvolvimento/produção): é um servidor web projetado para otimizar ambientes de alta performance. A utilização de memória é baixa se comparada a outros servidores web, possui um bom gerenciamento de carga da UCP e opções avançadas como CGI, FastCGI, SCGI, SSL, reescrita de URL, entre outras. Ele é projetado em um modelo assíncrono para lidar com solicitações e funciona em um único thread. Se você não deseja carregar os recursos do sistema, essa é a melhor opção para você. O Lighttpd é capaz de lidar com algumas centenas de solicitações por segundo.
Gunicorn (desenvolvimento/produção): O Gunicorn "Green Unicorn" é um servidor HTTP Python Web Server Gateway Interface. É um modelo de trabalhador pré-fork, portado do projeto Unicorn de Ruby. O servidor Gunicorn é amplamente compatível com vários frameworks da web, implementado de forma simples, leve nos recursos do servidor e bastante rápido. O Gunicorn é, acima de tudo, um servidor de aplicativos Python WSGI e testado em batalha: é rápido, otimizado e projetado para produção. Ele oferece um controle mais refinado sobre o próprio servidor de aplicativos;
Puma (desenvolvimento/produção): Puma é um servidor web HTTP derivado de Mongrel e escrito por Evan Phoenix. Ele enfatiza a velocidade e o uso eficiente da memória. Ele é ideal para aplicações Rails em produção;
Apache Tomcat (desenvolvimento/produção): O Tomcat é um servidor web Java, mais especificamente, um container de servlets. O Tomcat implementa, dentre outras de menor relevância, as tecnologias Java Servlet e JavaServer Pages e não é um container Enterprise JavaBeans. Desenvolvido pela Apache Software Foundation, é distribuído como software livre.
Glassfish (desenvolvimento): GlassFish é um servidor de aplicação open source liderado pela Sun Microsystems para a plataforma Java EE. Sua versão proprietária é chamada Sun GlassFish Enterprise Server. GlassFish suporta todas as especificações da API Java EE, tais como JDBC, RMI, JavaMail, JMS, JMX etc. e define como coordená-las. GlassFish também suporta algumas especificações para componentes Java EE, como Enterprise JavaBeans, conectore, servlets, portlets, JSF e diversas tecnologias de web services. Isto permite que desenvolvedores criem aplicações corporativas portáveis, escaláveis e fáceis de integrar com código legado.
A base de GlassFish é o código-fonte liberado pela Sun e o sistema de persistência TopLink da Oracle. Ele utiliza uma variante do Apache Tomcat como container de servlets, com um componente adicional chamado Grizzly que utiliza nio para maior escalabilidade e eficiência.
- Caddy (desenvolvimento/produção): é um servidor HTTP de código aberto pronto para produção, mais produtivo, fácil de usar e rápido com HTTPS ativado por padrão. Foi lançado em 2015 e oferece suporte a uma variedade de tecnologias de sites. O Caddy é semelhante ao NGINX em sintaxe e em muitas outras coisas, mas é extremamente simplificado. Let's Encrypt (uma autoridade certificadora sem fins lucrativos que fornece certificados TLS) A integração SSL pode ser concluída usando três linhas de configuração.

O modelo cliente-servidor, tornou-se uma das ideias centrais de computação de rede. Muitos aplicativos de negócios, escritos hoje, utilizam o modelo cliente-servidor. O termo também tem sido utilizado para distinguir a computação distribuída por computadores dispersos da "computação" monolítica centralizada em mainframe.
Mainframe é um computador de grande porte dedicado normalmente ao processamento de um volume enorme de informações. O termo mainframe era utilizado para se referir ao gabinete principal que alojava a CPU (unidade central de processamento) nos primeiros computadores.
Cada instância de software do cliente pode enviar requisições a vários servidores (sendo clusters ou não). Por sua vez, os servidores podem aceitar esses pedidos, processá-los e retornar as informações solicitadas para o cliente. Embora este conceito possa ser aplicado por uma variedade de razões e para diversos tipos de aplicações, a arquitetura permanece fundamentalmente a mesma.
Curiosidade: Nesse tipo de arquitetura que surgiu o Desenvolvimento Web com as terminologias de Front-End (Lado do Cliente) e Back-End (Lado do Servidor). Onde o front-end se trata de toda a interface que o usuário interage com a Web com arquivos estáticos e o Back-end se trata do seu consumo e interação com as aplicações de servidores localizados na internet.
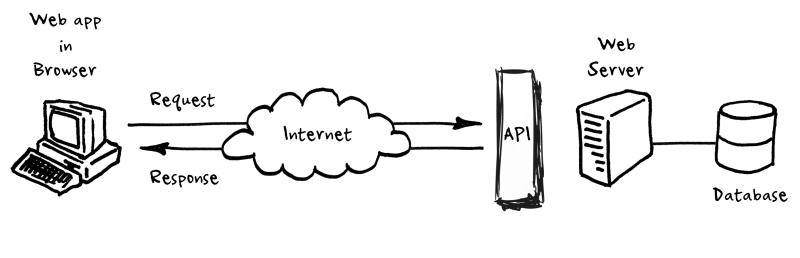
Temos aqui o cliente e o servidor, então imagine que o cliente é um navegador web (browser); e nós temos um servidor rodando, uma aplicação em Java, em PHP, C-Sharp (C#) - .NET, Python, Ruby ou a linguagem que for.
Então, o cliente vai digitar a URL do nosso site: “site.com.br”, por exemplo, e ele vai fazer uma requisição, utilizando o protocolo HTTP, para o computador que tem o nome “site.com.br”. Esse computador precisa saber/receber essa requisição (request) web e fazer uma resposta (response) que pode ser: exibir o HTML, a imagem, devolver o arquivo CSS - ou então mandar para uma aplicação processar essa requisição, uma aplicação em Java, em PHP, em Python ou no que for. Essa tarefa de receber a requisição e decidir o que vai fazer para enviar uma resposta, se vai mandar para uma aplicação, se vai devolver algum arquivo direto - essa é a tarefa de um servidor web (Web Server), e que ele vai fazer dentro de um servidor é ficar ouvindo a porta (Listener).
O papel de um servidor web é ouvir conexões TCP em alguma porta configurada. Um servidor web vai ficar esperando uma conexão chegar. Quando ela chegar, o servidor web faz seu trabalho, garantindo que a mensagem recebida está no formato HTTP e depois fazendo o que deve fazer segundo suas configurações.
Quando falamos de HTTP, a porta padrão é a 80. Então, se você não digita uma porta e está utilizando HTTP, essa requisição vai cair na porta 80. Então um servidor web fica lá ouvindo, por exemplo, a porta 80 e ele fica esperando alguma requisição ou algum pedido entrar para chegar nesse computador.
Caching (Cacheamento)
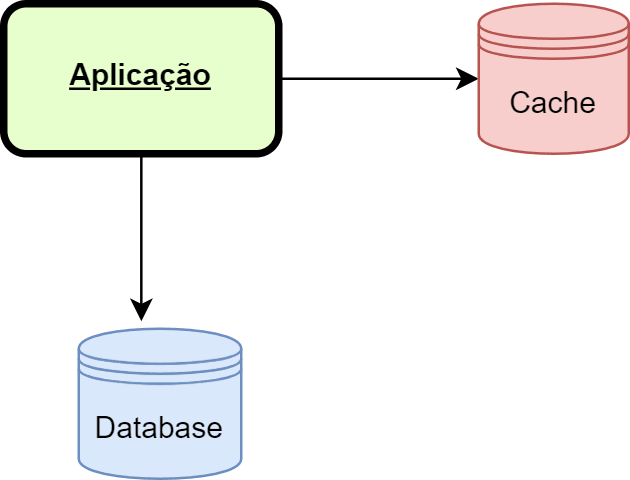
Na área da computação, cache é um dispositivo de acesso rápido, interno a um sistema, que serve de intermediário entre um operador de um processo e o dispositivo de armazenamento ao qual esse operador acede.
Portanto, o caching é uma técnica de armazenamento intermediário de dados da aplicação, que podem ser feitos através de hardware ou software. Ela serve para prover um acesso mais rápido a determinadas informações do que acessar diretamente a base de dados da aplicação.
Uma das maiores causas da má performance em aplicações Web é a falta de cache. Nem todas as requests precisam gastar recursos computacionais do seu servidor para executarem alguma coisa. Grande parte das requisições que fazemos podem ocupar um total de 0 recursos computacionais usando técnicas de caching.
Existem diversas formas de se fazer cache, a mais comum delas é utilizar o próprio servidor de proxy, como o Nginx ou o Apache para poder tratar e verificar se aquela requisição já foi feita no passado e evitar que ela sequer chegue no servidor da sua aplicação, já retornando o valor computado.
Em outros casos, quando precisamos de uma requisição mais complexa, a gente pode usar bancos de dados chave-valor, como o Redis, para poder armazenar os resultados das nossas requisições e retornar uma resposta o mais rápido possível, utilizando o mínimo do nosso servidor.
A grande maioria das empresas, principalmente as que lidam com dados que não se alteram tanto, usam caches para poder servir as páginas da forma mais rápida possível, ou você acha que o Twitter vai recalcular toda a sua linha do tempo todas as vezes?
Middleware (Servidor de Aplicação)
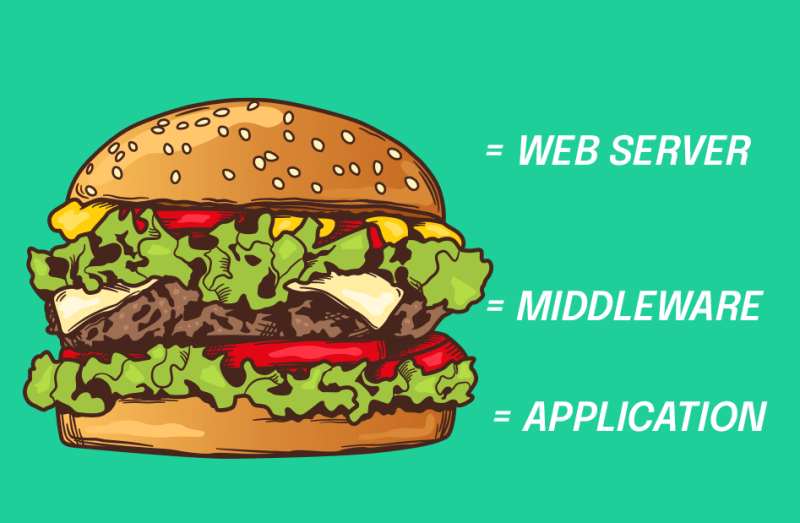
Quando chega, esse servidor web tem que saber o que fazer, ou seja, ele vai analisar e se o que você está pedindo parece ser um arquivo de imagem, então não preciso fazer nada com mais ninguém. Eu só vou te devolver essa imagem e o navegador vai exibir para você. Se você está me pedindo um arquivo estático, um arquivo de CSS? Então só vou te devolver, não preciso envolver ninguém nesse processo. Agora, o que você está me pedindo aqui parece ser uma rota, uma URL, que precisa ser executada por uma aplicação, em PHP, Python ou Java, então o que ele faz é poder transferir a responsabilidade para algum servidor de aplicação, também conhecido como middleware, cujo é um servidor que disponibiliza um ambiente para a instalação e execução de aplicações de informática, centralizando e dispensando a instalação em computadores clientes. Esse servidor de aplicação pode estar, por exemplo, aberto ouvindo uma outra porta.
Middleware é um software que permite um ou mais tipos de comunicação ou conectividade entre dois ou mais aplicativos e/ou componentes de aplicativos em uma rede distribuída. Ao tornar mais fácil conectar aplicativos que não foram projetados para se conectar uns aos outros — e fornecer funcionalidade para conectá-los de maneiras inteligentes — o middleware otimiza o desenvolvimento de aplicativos e acelera o tempo de lançamento no mercado.
E esse servidor web manda uma outra requisição (não utilizando o protocolo HTTP, necessariamente, pode ser usando outro formato), mas ele manda esse pedido para o servidor de aplicação. O servidor de aplicação processa, devolve para o servidor web, e o servidor web vai devolver para o cliente o que ele recebeu. Essa comunicação entre um servidor web e um servidor de aplicação pode ser feita de diversas formas. Então vamos focar, pelo menos no início, só nessa tarefa individual do servidor web tratando o que ele tem que tratar, de forma isolada.

Após vários modelos estudados de cliente-servidor caracterizou-se chamar tecnicamente de arquitetura multicamada, inspirado nas camadas no Modelo OSI, o processo de dividir a arquitetura de cliente-servidor em várias camadas lógicas (logic layers) facilitando o processo de programação distribuída, existe desde o modelo mais simples de duas camadas, e o mais utilizado atualmente que é o modelo de três camadas que é paralelo ao modelo de arquitetura de software denominado MVC (Model-view-controller), onde a troca de mensagens entre o cliente e o servidor é feita através de uma chamada de API: REST, SOAP ou RPC.
O resumo a seguir mostra a sequência de ações tanto do lado do cliente como do lado do servidor.
Características do Cliente
- Inicia pedidos/solicitações para servidores;
- Espera/aguarda por respostas;
- Recebe respostas;
- Conecta-se a um pequeno/reduzido número de servidores por vez;
- Normalmente/usualmente, interage diretamente com os servidores através/por meio de seu software de aplicação específico para a tarefa de estabelecer/possibilitar a comunicação entre cliente e servidor;
- Utiliza recursos da rede.
Características do Servidor
- Sempre aguarda/espera por um pedido/solicitação de um cliente;
- Atende os pedidos/solicitações e, em seguida, responde aos clientes com os dados solicitados/requisitados;
- Podem se conectar com outros servidores para atender uma solicitação específica do cliente; jamais podem se comunicar.
- Fornece recursos adicionais de rede, além da infraestrutura de rede propriamente dita.
- Normalmente interage por meio de interfaces diretamente com os usuários finais através de qualquer interface com o usuário;
- Estrutura o sistema.
Vantagens do modelo Cliente-Servidor
- Na maioria dos casos, a arquitetura cliente-servidor permite que os papéis e responsabilidades de um sistema de computação possam ser distribuídos entre vários computadores independentes que são conhecidos por si só através de uma rede. Isso cria uma vantagem adicional para essa arquitetura: maior facilidade de manutenção. Por exemplo, é possível substituir, reparar, atualizar ou mesmo realocar um servidor de seus clientes, enquanto continuam a ser a consciência e não afetado por essa mudança. A arquitetura cliente-servidor permite que as responsabilidades de um sistema de computação possam ser distribuídas entre vários computadores independentes interconectados por meio de uma rede, o que resulta em maior facilidade de manutenção;
- Todos os dados são armazenados nos servidores, que geralmente possuem controles de segurança muito maiores do que a maioria dos clientes. Os servidores podem controlar melhor o acesso a recursos, para garantir que apenas os clientes com credenciais válidas possam aceder e alterar os dados;
- Como o armazenamento de dados é centralizado, as atualizações dos dados são muito mais fáceis de administrar em comparação com o paradigma P2P. Em uma arquitetura P2P, atualizações de dados podem precisar ser distribuídas e aplicadas a cada nó na rede, o que consome tempo e é passível de erro, já que pode haver milhares ou mesmo milhões de nós. O gerenciamento das atualizações dos dados é mais fácil de ser feita nesse modelo do que no paradigma peer-to-peer (P2P), onde as atualizações de dados podem necessitar ser distribuídas e aplicadas a cada nó na rede, o que consome tempo e torna-se passível de erro;
- Muitas tecnologias avançadas de cliente-servidor estão disponíveis e foram projetadas para garantir a segurança, facilidade de interface do usuário e facilidade de uso;
- Os dados principais são armazenados nos servidores, que por regra possuem controles de segurança mais robustos do que o da maioria dos clientes.
- Muitas tecnologias avançadas de cliente-servidor foram projetadas para garantir a segurança, facilidade de interface do usuário e facilidade de uso encontram-se disponíveis.
- Funciona com vários clientes diferentes, sendo que os clientes podem ter capacidades diferentes.
Entretanto, o modelo apresenta diversos problemas. Visto que a capacidade de oferecer serviços ou recursos fica centralizada na figura do servidor, surge um problema:
O que fazer quando o número de requisições dos clientes ultrapassa a capacidade computacional do servidor?
Essa pergunta não tem uma resposta de alta eficiência para aplicações em redes de computadores. A sobrecarga de servidores é um problema real apesar de a capacidade computacional dos servidores crescer consideravelmente ano após ano.
Além do fato de algumas requisições não serem atendidas, pela sobrecarga do servidor, no modelo cliente-servidor, ainda há o fato de que o modelo não é robusto, ou seja, se um servidor crítico falha, as requisições já feitas pelos clientes não poderão ser atendidas.
Esses motivos são a base para a concepção das redes peer-to-peer (P2P).
Desvantagens do modelo Cliente-Servidor
- Clientes podem solicitar serviços, mas não podem oferecê-los para outros clientes, sobrecarregando o servidor, pois quanto mais clientes, mais informações que irão demandar mais banda.
- Um servidor poderá ficar sobrecarregado caso receba mais solicitações simultâneas dos clientes do que pode suportar;
- Este modelo não possui a robustez de uma rede baseada em P2P. Na arquitetura cliente-servidor, se um servidor crítico falha, os pedidos dos clientes não poderão ser cumpridos. Já no P2P, os recursos são normalmente distribuídos entre vários nós. Mesmo se uma ou mais máquinas falharem no momento de download de um arquivo, por exemplo, as demais ainda terão os dados necessários para completar a referida operação.
Protocolos de transporte e aplicações de rede
Os protocolos do nível de transporte fornecem serviços que garantem uma transferência confiável de dados e aplicativos entre computadores (ou outros equipamentos) remotos. Os programas na camada de aplicação usam os protocolos de transporte para contactar outras aplicações. Para isso, a aplicação interage com o software do protocolo antes de ser feito o contacto. A aplicação que aguarda a conexão informa ao software do protocolo local que está pronta a aceitar mensagem. A aplicação que estabelece a conexão usa os protocolos de transporte e rede para contactar o sistema que aguarda. As mensagens entre as duas aplicações são trocadas através da conexão resultante.
Existem duas formas para que se estabeleça uma ligação cliente-servidor: enquanto uma delas é orientada à conexão, a outra não é. O TCP, por exemplo, é um protocolo de transporte orientado à conexão em que o cliente estabelece uma conexão com o servidor e ambos trocam múltiplas mensagens de tamanhos variados, sendo a aplicação do cliente quem termina a sessão. Já o protocolo UDP não é orientado à conexão, nele o cliente constrói uma mensagem e a envia num pacote UDP para o servidor, que responde porém, sem garantia de entrega em uma conexão permanente com o cliente.





Top comments (0)